1,spark基础及体系架构
1.1 spark why?
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
- Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求
- 官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍
Spark VS MapReduce 迭代计算:
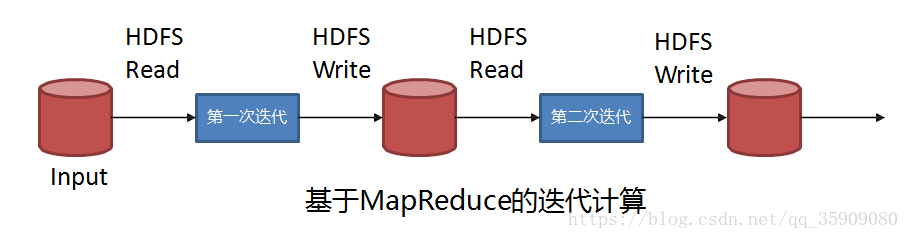
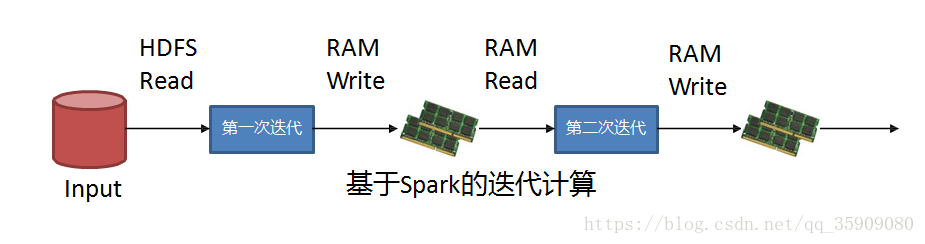
有多个MapReduce任务串联时,依赖HDFS存储中间结果的输出。MapReduce在处理复杂DAG时会带来大量的数据copy、序列化和磁盘I/O开销;
spark处理速度则非常快:
- Spark尽可能减少中间结果写入磁盘
- 尽可能减少不必要的Sort/Shuffle
- 反复用到的数据进行Cache
- 对于DAG进行高度优化
- 划分不同的Stage
- 使用延迟计算技术
1.2 架构及生态
- 通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:

- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
Spark架构的组成图如下:
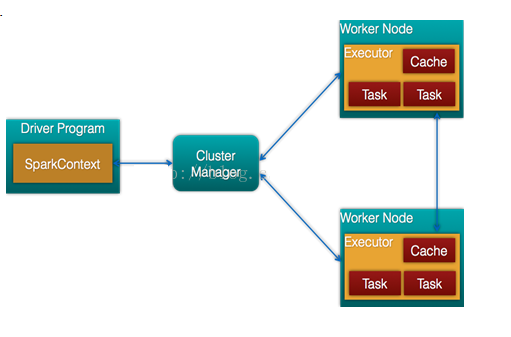

- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
- Driver: 运行Application 的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程
1.3 spark执行流程
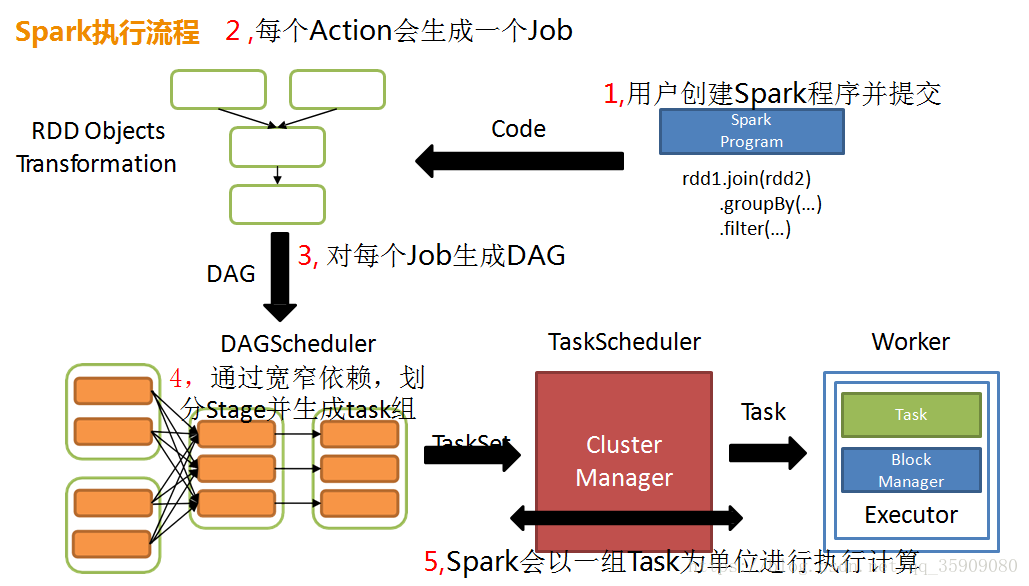
术语解释
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
- Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
- Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
- Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
- Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
- Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
- DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图

- TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用

- 在不同运行模式中任务调度器具体为:
- Spark on Standalone模式为TaskScheduler
- YARN-Client模式为YarnClientClusterScheduler
- YARN-Cluster模式为YarnClusterScheduler
- 将这些术语串起来的运行层次图如下:

Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
1.4 RDD及Stage
RDD:
Spark将数据缓存在分布式内存。弹性分布式数据集。
如何做实现?RDD:
- Spark的核心
- 分布式内存抽象
- 提供了一个高度受限的共享内存模型
- 逻辑上集中但是物理上是存储在集群的多台机器上
RDD特性:
•只读
- 通过HDFS或者其它持久化系统创建RDD
- 通过transformation将父RDD转化得到新的RDD
- RDD上保存着前后之间依赖关系
•Partition
- 基本组成单位,RDD在逻辑上按照Partition分块
- 分布在各个节点上
- 分片数量决定并行计算的粒度
- RDD中保存如何计算每一个分区的函数
•容错
- 失败自动重建
- 如果发生部分分区数据丢失,可以通过依赖关系重 新计算
宽窄依赖及Stage
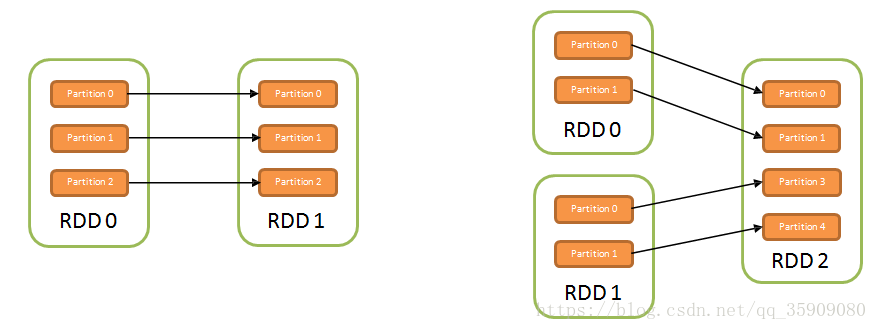
•窄依赖:没有数据shuffling;所有父RDD中的Partition均会一一映射到子RDD的Partition中
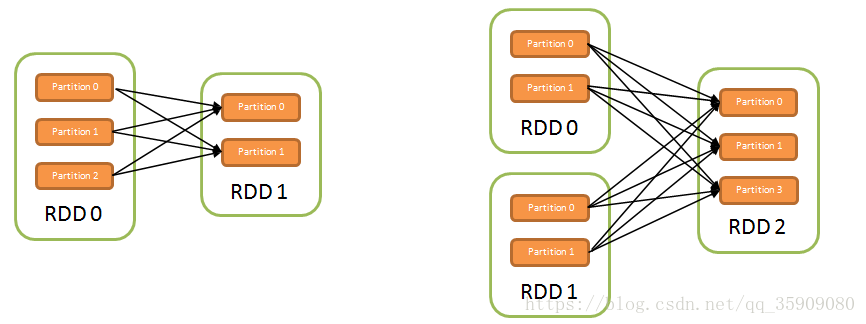
•宽依赖:有数据shuffling ;所有父RDD中的Partition会被切分,根据key的不同划分到子RDD的Partition中
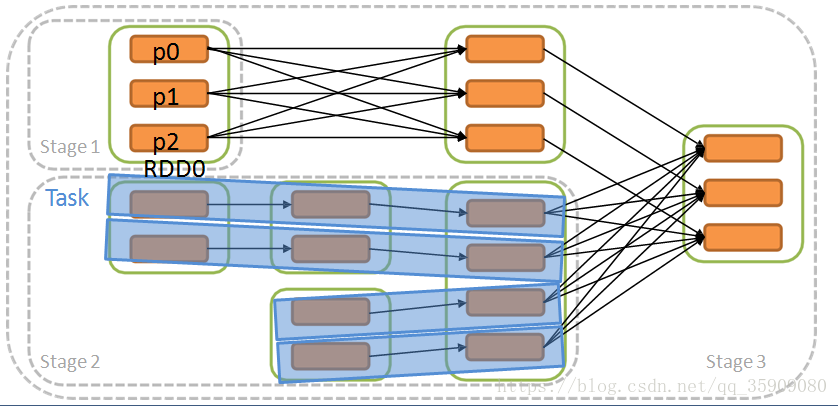
•Stage : 一个Job会被拆分为多组Task,每组Task被称为一个Stage
划分依据: 以shuffle操作作为边界,遇到一个宽依赖就分一个stage
Stage优化:
- 对窄依赖可以进行流水线(pipeline)优化
- 不互相依赖的Stage可以并行执行
- 存在依赖的Stage必须在依赖的Stage执行完之后才能执行
- Stage并行执行程度取决于资源数
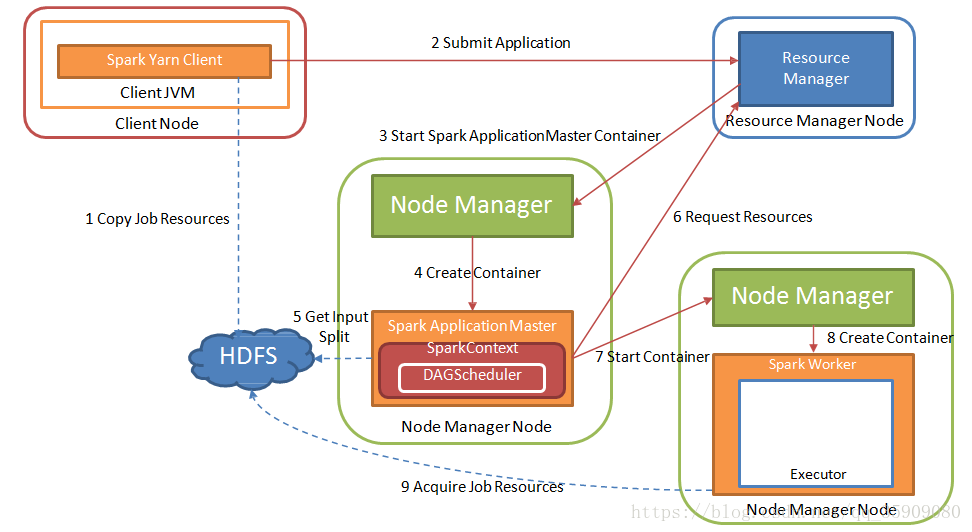
1.5 spark on yarn
yarn资源调度过程
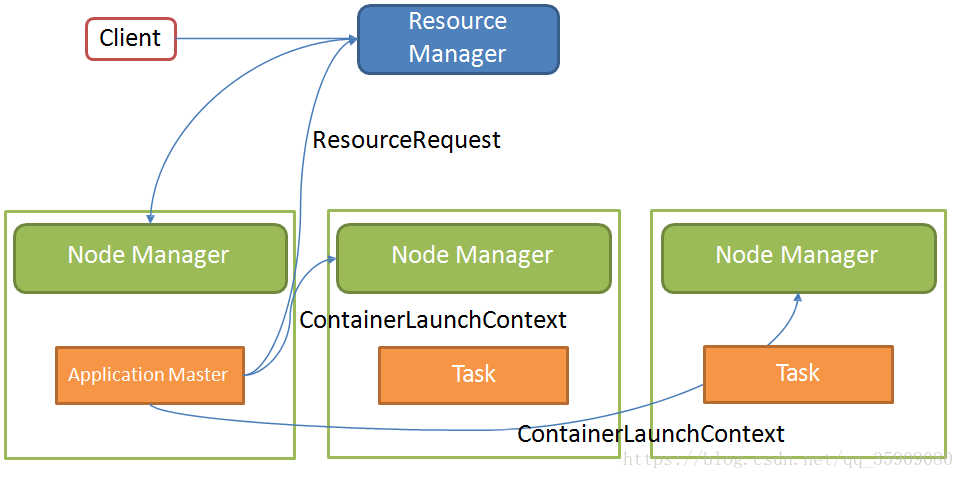
sprark on yarn:
•Yarn
- ResourceManager:负责整个集群资源管理和分配
- ApplicationMaster:Yarn中每个Application对应一个AM,负责与ResrouceManager协商获取资源,并告知NodeManager分配启动Container
- NodeManager:每个节点的资源和任务管理器,负责启动Container,并监 视资源使用情况
- Container:资源抽象
•Spark
- Application:用户自己编写的Spark程序
- Driver:运行Application的main函数并创建SparkContext,和ClusterManager通信申请资源,任务分配并监控运行情况
- ClusterManager:指的是Yarn
- DAGScheduler:对DAG图划分Stage
- TaskScheduler:把TaskSet分配给具体的Executor
•Spark支持三种运行模式 :standalon, yarn-cluster, yarn-client
处理流程:
2,spark编程模型
2.1 spark编程核心思想
函数式编程特点:函数为一等公民;数据映射;变量不可变;没有副作用。
2.2 spark对于RDD有四种类型的算子
1)Create
- SparkContext.textFile()
- SparkContext.parallelize()
2)Transformation
- 作用于一个或者多个RDD,输出转换后的RDD。例如:map, filter, groupBy
3)Action
- 会触发Spark提交作业,并将结果返回Driver Program 。例如:reduce, countByKey
4)Cache
- cache 缓存
- persist 持久化
惰性运算:遇到Action时才会真正的执行
访问官方文档:https://spark.apache.org/docs/1.6.0/
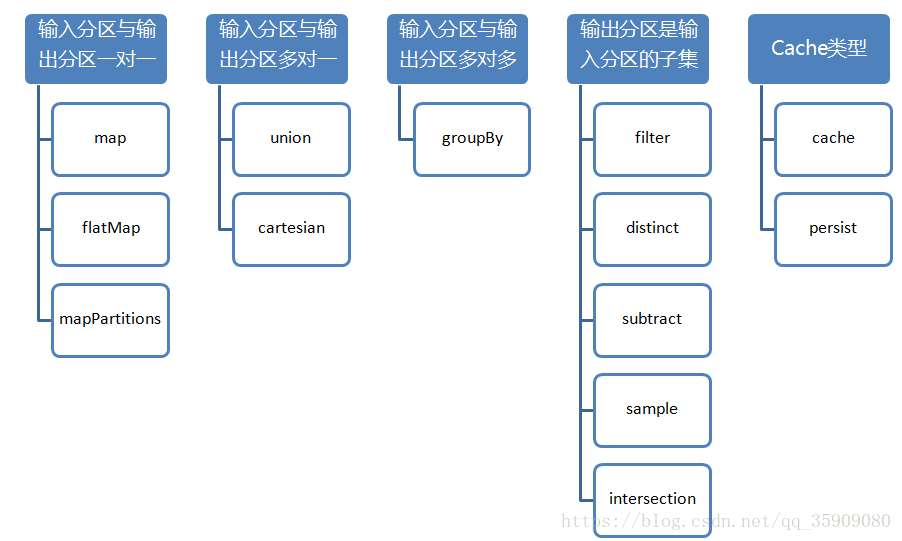
2.3 Value类型 Transformation 算子分类
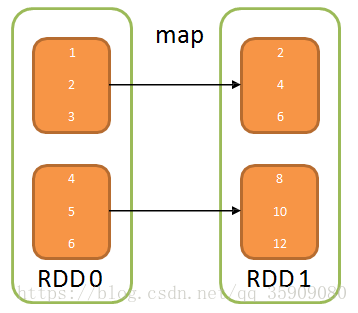
2.3.1Transformation-map
map
- def map[U](f: (T) ⇒ U)(implicit arg0: ClassTag[U]):RDD[U]
- 生成一个新的RDD,新的RDD中每个元素均有父RDD通 过作用func函数映射变换而来
- 新的RDD叫做MappedRDD
Example:
- val rd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6), 2) val rd2 = rd1.map(x => x * 2)
- rd2.collect()
- rd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize
- rd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map res1: Array[Int] = Array(2, 4, 6, 8, 10, 12)
2.3.2 Transformation-mapPartitions
mapPartitions
- def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]
- 获取到每个分区的迭代器
- 对每个分区中每个元素进行操作
Example
- val rd1 = sc.parallelize(List("20180101", "20180102", "20180103", "20180104", "20180105","20180106"), 2)
- val rd2 = rd1.mapPartitions(iter => {val dateFormat = new java.text.SimpleDateFormat("yyyyMMdd") iter.map(dateStr => dateFormat.parse(dateStr))})
- rd2.collect()
- res1: Array[ java.util.Date] = Array(Mon Jan 01 00:00:00 UTC 2018, Tue Jan 02 00:00:00 UTC 2018, Wed Jan 0300:00:00 UTC 2018, Thu Jan 04 00:00:00 UTC 2018, Fri Jan 05 00:00:00 UTC 2018, Sat Jan 06 00:00:00 UTC 2018)
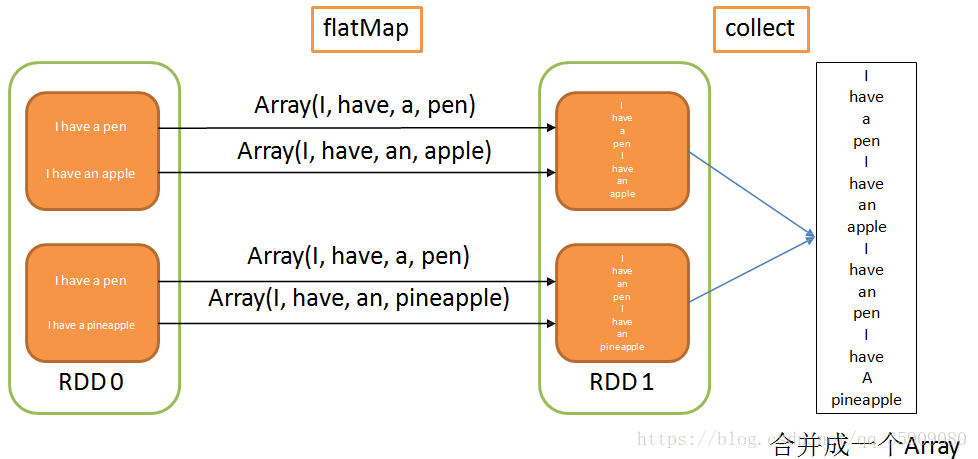
2.3.3 Transformation-flatMap
flatMap
- def flatMap[U](f: (T) ⇒ TraversableOnce[U])(implicit arg0: ClassTag[U]): RDD[U]
- 将RDD中的每个元素通过func转换为新的元素
- 进行扁平化:合并所有的集合为一个新集合
- 新的RDD叫做FlatMappedRDD
Example
- val rd1 = sc.parallelize(Seq("I have a pen","I have an apple", "I have a pen","I have a pineapple"), 2) val rd2 = rd1.map(s => s.split(" "))
- rd2.collect()
- val rd3 = rd1.flatMap(s => s.split(" "))
- rd3.collect()
- rd3.partitions
- res136: Array[Array[String]] = Array(Array(I, have, a, pen), Array(I, have, an, apple), Array(I, have, a, pen), Array(I, have,a, pineapple))
- res137: Array[String] = Array(I, have, a, pen, I, have, an, apple, I, have, a, pen, I, have, a, pineapple)
2.3.4Transformation-union
union
- def union(other: RDD[T]): RDD[T]
- 合并两个RDD
- 元素数据类型需要相同,并不进行去重操作
Example
- val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange")) val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
- val rdd3 = sc.parallelize(Seq("Durian"))
- val rddUnion = rdd1.union(rdd2).union(rdd3)
- rddUnion.collect.foreach(println)
- res1: Array[String] = Array(Apple, Banana, Orange, Banana, Pineapple, Durian)
2.3.5 Transformation-distinct
distinct
- def distinct(): RDD[T]
- 对RDD中的元素进行去重操作
Example
- val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange")) val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
- val rdd3 = sc.parallelize(Seq("Durian"))
- val rddUnion = rdd1.union(rdd2).union(rdd3)
- val rddDistinct = rddUnion.distinct()
- rddDistinct.collect()
- res1: Array[String] = Array(Orange, Apple, Banana, Pineapple, Durian)
2.3.6 Transformation-filter
filter
- def filter(f: (T) ⇒ Boolean): RDD[T]
- 对RDD元素的数据进行过滤
- 当满足f返回值为true时保留元素,否则丢弃
Example
- val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
- val filteredRDD = rdd1.filter(item => item.length() >= 6)
- filteredRDD.collect()
- res1: Array[String] = Array(Banana, Orange)
2.3.7 Transformation-intersection
interesction
- def intersection(other: RDD[T]): RDD[T]
- def intersection(other: RDD[T], numPartitions: Int): RDD[T]
- def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
- 对两个RDD元素取交集
Example
- val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
- val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
- val rddIntersection = rdd1.intersection(rdd2)
- rddIntersection.collect()
- res1: Array[String] = Array(Banana)
2.4 Key-Value类型 Transformation 算子分类

2.4.1 Transformation-groupByKey
groupByKey
- def groupByKey(): RDD[(K, Iterable[V])]
- def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
- def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
- 对RDD[Key, Value]按照相同的key进行分组
Example
- val scoreDetail = sc.parallelize(List(("xiaoming","A"), ("xiaodong","B"),("peter","B"), ("liuhua","C"), ("xiaofeng","A")), 3) scoreDetail.map(score_info => (score_info._2, score_info._1)).groupByKey().collect().foreach(println(_))
- scoreDetail: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[110] at parallelize(A,CompactBuffer(xiaoming, xiaofeng)) (B,CompactBuffer(xiaodong, peter)) (C,CompactBuffer(lihua))
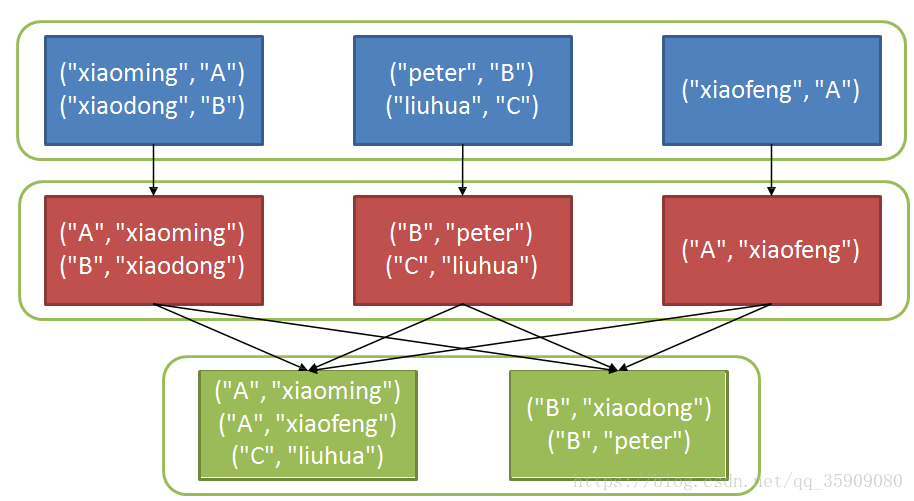
2.4.2 Transformation-reduceByKey
reduceByKey
- def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)]
- def reduceByKey(func: (V, V) ⇒ V, numPartitions: Int): RDD[(K, V)]
- def reduceByKey(partitioner: Partitioner, func: (V, V) ⇒ V): RDD[(K, V)]
- 对RDD[Key, Value]按照相同的key进行merge操作
- 可以在shuffle前对当前节点上的结果先进行merge操作
Example
- val scoreDetail = sc.parallelize(List("A", "B", "B", "D", "B", "D", "E", "A", "E"), 3) scoreDetail.map(w => (w, 1)).reduceByKey(_ + _).collect()
- scoreDetail: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[120] at parallelize res1: Array[(String, Int)] = Array((B,3), (E,2), (A,2), (D,2))
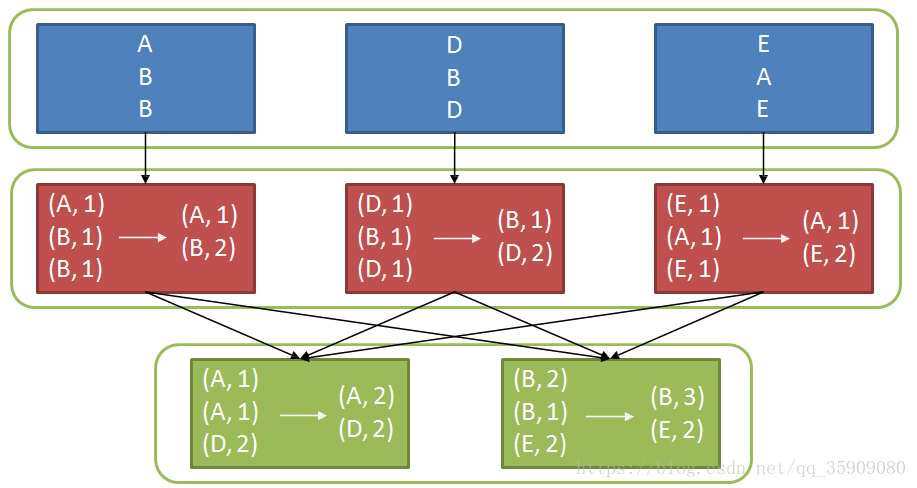
2.4.3 Transformation-join
join
- def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
- def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
- def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
- 对两个RDD根据key进行连接操作
Example
- val data1 = sc.parallelize(Array(("A", 1),("b", 2),("c", 3)))
- val data2 = sc.parallelize(Array(("A", 4),("A", 6),("b", 7),("c", 3),("c", 8)))
- val result = data1.join(data2)
- result.collect()
- data1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD data2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD result: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD
- res1: Array[(String, (Int, Int))] = Array((A,(1,4)), (A,(1,6)), (b,(2,7)), (c,(3,3)), (c,(3,8)))
2.5 Action 算子分类
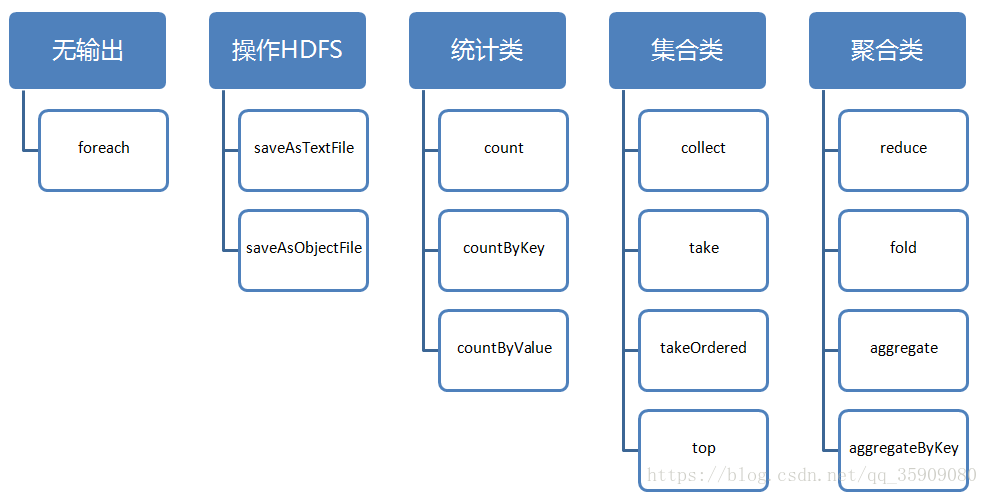
2.5.1 Action-count/countByKey/countByValue
count
- def count(): Long
- 从RDD中返回元素的个数
countByKey
- def countByKey(): Map[K, Long]
- 从RDD[K, V]中返回key出现的次数
- val c = sc.parallelize(List((3, "Gnu"), (3, "Yak"), (5, "Mouse"), (3, "Dog")), 2)
- c.countByKey
- res1: scala.collection.Map[Int,Long] = Map(3 -> 3, 5 -> 1)
countByValue
- def countByValue(): Map[T, Long]
- 统计RDD中值出现的次数
- val b = sc.parallelize(List(1,2,3,4,5,6,7,8,2,4,2,1,1,1,1,1))
- b.countByValue
- res1: scala.collection.Map[Int,Long] = Map(5 -> 1, 1 -> 6, 6 -> 1, 2 -> 3, 7 -> 1, 3 -> 1, 8 -> 1, 4 -> 2)
2.5.2 Action-collect/take/takeOrdered/top
collect
- def collect(): Array[T]
- 从RDD中返回所有的元素到Driver Program
take
- def take(num: Int): Array[T]
- 从RDD中取0到num – 1下标的元素,不排序
takeOrdered
- def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
- 从RDD中返按从小到大(默认)返回num个元素
top
- def top(num: Int)(implicit ord: Ordering[T]): Array[T]
- 和takeOrdered类似,但是排序顺序从大到小
2.5.3 Action-reduce
reduce
- def reduce(f: (T, T) => T): T
- 对RDD中的元素进行聚合操作
- 注意:reduceByKey是Transformation
- 如果集合为空则会抛出Exception
Example
- val item = sc.parallelize(1 to 100, 3) item.reduce((first, second) => first + second) item.reduce(_ + _)
- res1: Int = 5050
- val item = sc.parallelize(List(1, 2, 3)) item.filter(_ > 4).reduce(_ + _)
- java.lang.UnsupportedOperationException: empty collection
2.5.4 Action-reduce
reduce
- def reduce(f: (T, T) => T): T
- 对RDD中的元素进行聚合操作
- 注意:reduceByKey是Transformation
- 如果集合为空则会抛出Exception
Example
- val item = sc.parallelize(1 to 100, 3) item.reduce((first, second) => first + second) item.reduce(_ + _)
- res1: Int = 5050
- val item = sc.parallelize(List(1, 2, 3)) item.filter(_ > 4).reduce(_ + _)
- java.lang.UnsupportedOperationException: empty collection
2.5.5 Action-fold
fold
- def fold(zeroValue: T)(op: (T, T) ⇒ T): T
- 类似于reduce,对RDD进行聚合操作
- 首先每个分区分别进行聚合,初始值为传入的zeroValue,然后对所有的分区进行聚合
Example
- val item = sc.parallelize(1 to 100, 3) item.fold(0)(_ + _)
- res1: Int = 5050
- val item = sc.parallelize(List(1, 2, 3)) item.filter(_ > 4).fold(0)(_ + _)
- res198: Int = 0
2.5.6 Action-aggregateByKey
aggregate
- def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
- 允许传入两个function:seqOp和combOp
- seqOp负责对每个分区进行聚合,初始值为zeroValue
- combOp负责对每个分区聚合的结果进行合并
Example
- val rdd = sc.parallelize(Seq( ("A",110),("A",130),("A",120),("B",200),("B",206),("B",206),("C",150),("C",160),("C",170)))
- val agg_rdd = rdd.aggregateByKey((0,0))((acc, value) => (acc._1 + value, acc._2 + 1),(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2))
- val avg = agg_rdd.mapValues(x => (x._1/x._2))
- avg.collect
- (B,204) (A,120) (C,160)
3,spark内存模型

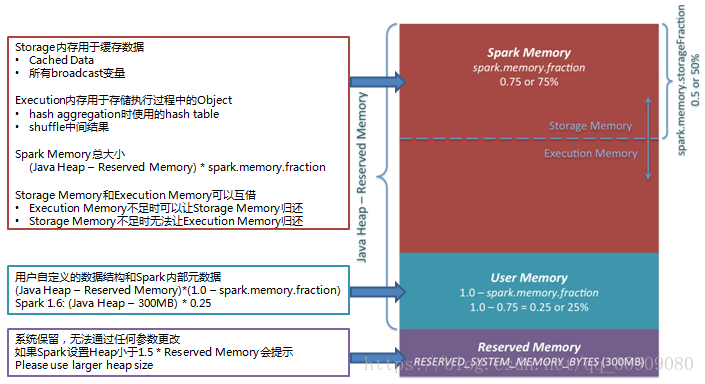
Spark内存优化
Executor最大任务并行度
- TP = N/C
- 其中N=spark.executor.cores, C=spark.task.cpus
- 任务以Thread方式执行
- 活跃线程可使用内存范围(1/2n, 1/n) why?
出现Executor OOM错误(错误代码137,143等)
原因:Executor Memory达到上限,解决办法:
- 增加每个Task内存使用量
- 增大最大Heap值
- 降低spark.executor.cores数量
- 或者降低单个Task内存消耗量
- 每个partition对应一个任务
- 非SQL类应用 spark.default.parallism
- SQL类应用 spark.sql.shuffle.partition
数据倾斜问题:可以采用对key值加盐的方式解决。