类别不平衡(class-imbalance),是指分类任务中不同类别的训练样例数目差别很大的情况(例如,训练集正类样例10个,反类样例90个),本文假设正类样例较少,反类样例较多。
现有解决方案大体分为三类,如下文所示。
欠采样(undersampling)
欠采样方法,即去除一些反类样例,使得正、反类样例数量接近。
EasyEnsemble为欠采样的代表性算法,利用继承学习机制,将反例划分为若干个集合,供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。
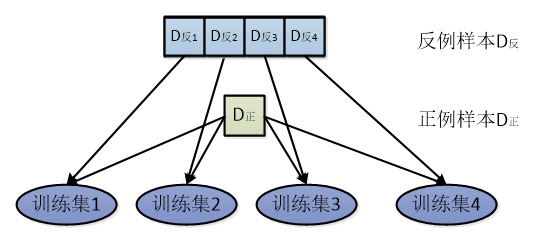
上图为EasyEnsemble示意图,若反例样本是正例样本数量的4倍,将反例样本随机划分成4个集合,每个集合分别和全部正例样本组成不同的训练集,每个训练集由不同学习器进行学习,这样,每个训练集的数据都是平衡的,全局来看又不会舍弃掉任何反例样本。
过采样(oversampling)
过采样,即增加一些正例,使得正、反类样例数量接近。
SMOTE,过采样的代表性算法,通过对训练集的正例进行插值,来产生额外的正例。
阈值移动(threshold-moving)
阈值移动,直接基于原始训练集进行学习,但是修改分类器预测时的决策过程;下面以逻辑回归(logistics regression)为例,进行说明。
逻辑回归(logistics regression),即对数几率回归,其模型可以表示为:
即:
其中,
为预测得到结果,
为输入样本数据,
和
为模型权值和偏置。
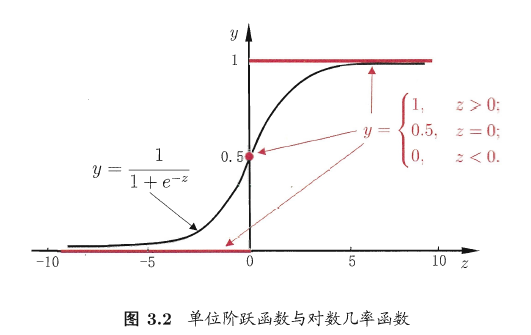
如上图所示,图中曲线为对数几率函数(Sigmoid 函数的一种),因此, 在0到1之间。
我们将 视为样本 为正例的可能性,那么 是其为反例的可能性,几率 反映了正例可能性和反例可能性之比。
一般情况下,
当样本平衡时,分类器的决策规则为:
- 若 ,则 预测为正例;
- 上条规则亦可以表示为,若 ,则 预测为正例。
当样本不平衡时,记 为正例样本数量, 为反例样本数量,分类器决策规则变为:
- 若 ,则 预测为正例;
- 上条规则亦可以表示为,若 ,或 ,则 预测为正例。
这种类别不平衡学习的策略也叫“再缩放”(rescaling)或“再平衡”(rebalance)