


私信菜鸟007获取源码哦!
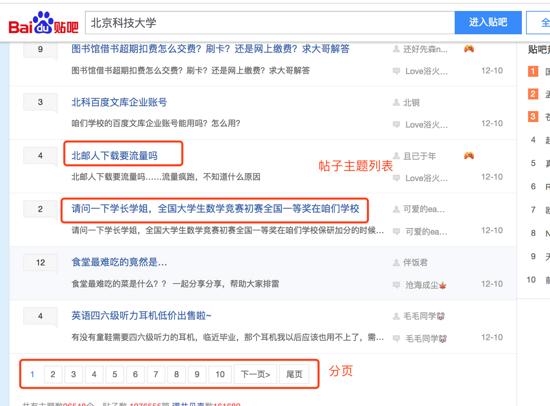
我们的目标是关注帖子的标题名称,比如这个: “北邮人下载需要流量吗” , “请问一下学长学姐,全国大学生数学竞赛初赛全国一等奖在咱们学校” 。
还有就是我们肯定不能只爬取一页的信息,这里我们将要爬取前1000页的信息。
页面分析
首先我们打开Chrome开发者工具看一下列表如何解析。
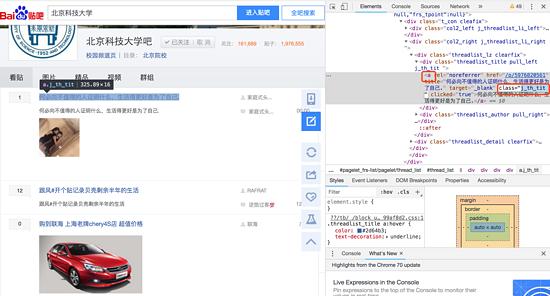
这里我们选中一个标题名称后,可以直接看到一个 a 标签,它的class为 j_th_tit 。
所以使用以下代码就可以打印出所有的标题来。
进群:960410445 即可获取数十套PDF!
soup = BeautifulSoup(resp.content, "html.parser")
items = soup.find_all("a", {"class", "j_th_tit"})
for a in items:
title = item.get_text()
print(title)
分页分析
页面分析完了之后就可以分析一下分页了,我们把小箭头晃到底部分页的位置。

可以发现分页对应的网址主要是pn的值不一样。第2页对应50,第3页对应100,第4页对应150。
也就是,
pn=(page−1)∗50这样的关系。
爬虫编写
完成以上的分析工作之后,就可以开始实现我们的爬虫了。
数据库操作
首先是数据库的操作,这里使用到 tieba 数据库的 beike 集合。然后保存文档的话就直接insert就好了。
def init_collection(): client = pymongo.MongoClient(host="localhost", port=27017) db = client['tieba'] return db["beike"] def save_docs(docs): beike.insert(docs) beike = init_collection()
任务初始化
下面,我们不编写worker,而是先进行任务的初始化。
if __name__ == '__main__':
crawler = SimpleCrawler(5)
crawler.add_worker("worker", worker)
for i in range(1, 11):
crawler.add_task({"id": "worker", "page": i})
crawler.start()
这里我们首先初始化 SimpleCrawler ,然后给添加 worker 以及 task 。
关于task,可以看到上面的代码通过循环,添加了10个任务,每个任务的page属性不一样。worker肯定是爬取某一页并解析加入数据库的代码,我们这里其实就是添加了爬取前10页的任务。
这里虽然也可以写直接添加爬取前1000页的任务,但是考虑到实际情况下任务可能会非常多,为了让任务队列不溢出,开始可以少添加一些。
Worker编写
接下来是 worker 的编写。
首先worker肯定要有三个基础部分:下载页面、解析页面、保存数据。除此之外,因为要爬取1000页,所以还要添加新的任务来爬取剩下的990。
这里可以判断当前页码+10是否大于1000,如果不大于的话把当前页码+10的网页添加到新的任务队列中。
def worker(queue, task, lock):
offset = (task["page"] - 1) * 50
print("downloading: page %d" % task["page"])
# 1. 下载页面
resp = requests.get("http://tieba.baidu.com/f?kw="
"%E5%8C%97%E4%BA%AC%E7%A7%91%E6%8A%80%E5%A4%A7%E5%AD%A6&ie=utf-8&pn=" + str(offset))
soup = BeautifulSoup(resp.content, "html.parser")
# 2. 解析页面
items = soup.find_all("a", {"class", "j_th_tit"})
docs = []
for index, item in enumerate(items):
docs.append({"page": task["page"], "index": index, "title": item.get_text()})
print(task["page"], index, item.get_text())
# 3. 保存数据
with lock:
save_docs(docs)
# 4. 添加新任务
if (task["page"] + 10) > 1000:
queue.put({"id": "NO"})
else:
queue.put({"id": "worker", "page": task["page"] + 10})
运行效果
以上就是爬虫的全部代码,运行后可以看到类型下面的结果。
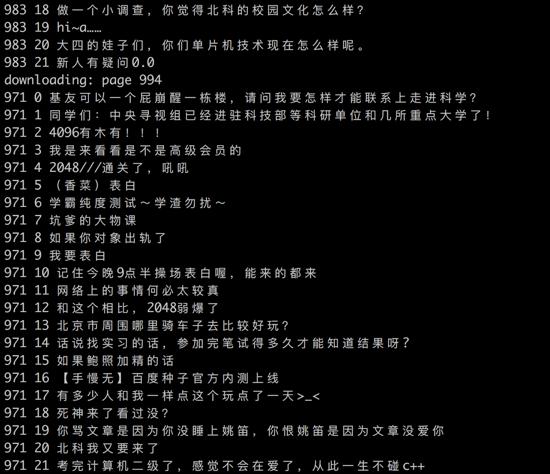
通过以上代码大概爬了4万多条数据,之后的两章我们将把这些标题当做语料库,做一个简单的相关帖子推荐系统。
说明
网站可能会经常变化,如果上述爬虫不能用的话,可以爬取我保存下来的贴吧网页: http://nladuo.cn/beike_tieba/1.html 。
分页的格式类似于1.html、2.html、…、1000.html。