作为剁手族的成员、资深吃货之一的我,在网购各种各样的零食是非常频繁的,可是要在浩瀚的商品库中找到合适的宝贝,大多数情况下只能参考评论!为了解决这个麻烦,就用Python做了个抓取淘宝商品评论的小小爬虫。今天就把这个爬虫分享给大家!

思路
我们就拿“德州扒鸡”做为参考目标吧~!如果想抓其他商品的话,自行更换目标即可!打开淘宝,搜索目标,随便点击一个商品进入,在点击累计评论,打开F12开发者工具——网络,先清除现有的所有内容,然后点击下一页评论,在弹出的内容中查找文件中开头为list_detail_rate.htm的html类型,如下图所示
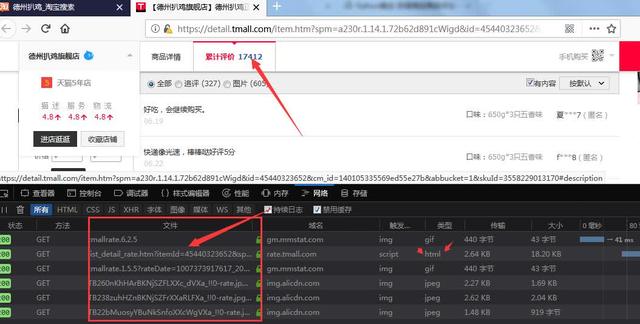
这个html中就含有我们需要的内容,左键点击然后选择响应,就可以看到具体响应内容了!
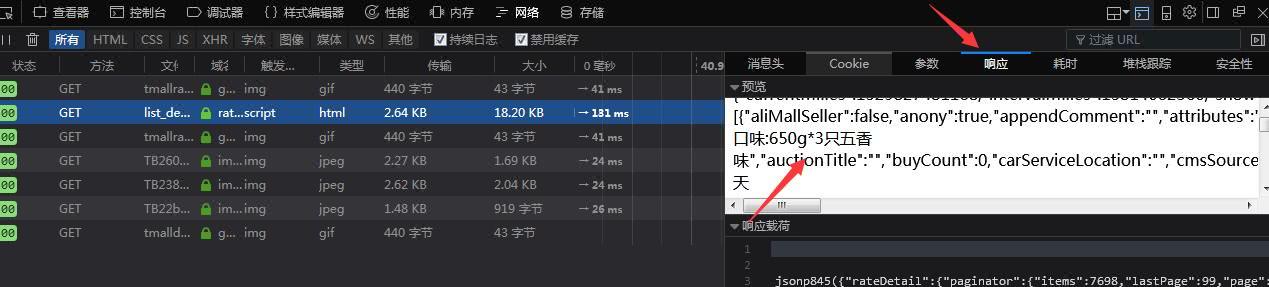
这里面是一大串包含我们需要的内容在内的源代码,如果大家有兴趣可以提取内容做成json数据,而我们这里只需要评论数据,所以,用正则匹配评论部分就可以了!
开始写代码
具体过程就赘述了,新建一个函数,接受店铺ID(唯一)作为参数,做一个无限循环来翻页,并以评论时间为判断是否重复,如果重复则跳出循环(return可以直接跳出循环),整个函数部分代码如下
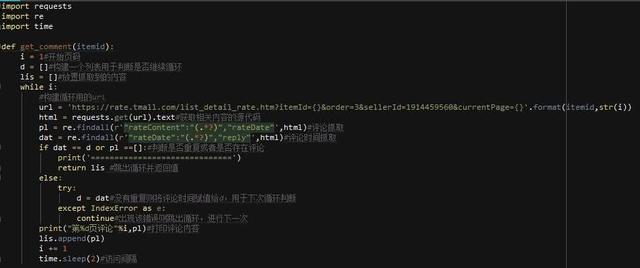
加入try是因为代码一直在抽风的跳出index错误,后续还可以改进!
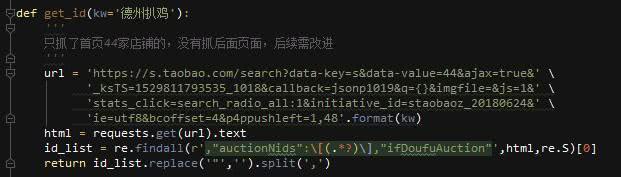
作为一个爬虫爱好者,必然要加深抓取的广度的,试着将整个页面的店铺ID抓取出来!这次简单,直接抓到json数据,然后用正则匹配,放回列表,因为时间有限,没有研究出url翻页的依据,就只抓取了一页!
然后开始写主函数,保存到文档!运行结果如下

emmm,看评论是可以入手的!哈哈!

总结
这个爬虫平时拿来小玩一下是可以的,用来分析也行,但是请切记不要外传扩散,不然很容易进坑!另外淘宝的反爬其实也不是很难,比如上面的爬虫,并没有做反爬措施,大家可以拿这个来练练手,玩一玩,记得加入sleep就可以,不要给对方服务器造成压力为最好!希望这个小小爬虫能给你带来会心一笑。
写在最后
喜欢本文的小伙伴或者觉得本文对你有帮助可以点播关注或转发。小编在此推荐一个学习与交流Python学习的地方,如果有想学Python的小伙伴可以加群959997225,另外没有装Python环境的小伙伴也可以联系小编,小编这里有免费的环境提供给大家!
本文来自网络,如有侵权,请联系小编删除!