作者:孙高飞
状态模式
状态模式之所以常用是因为在我们的很多业务逻辑中都会有不同状态的出现,比如订单的状态,任务的状态。而不同的状态下UI上会有不同的行为。 比如不同的控件的展示, 不同的报错信息等。 我们往往需要验证不同状态下的逻辑。 但是我们的状态往往比较多(一般怎么都会有个5,6种吧)。 所以我们需要一种合适的方法来组织和管理这些状态下的行为。
举个例子, 在我们的产品中,每一个算子都有:未配置,配置成功,等待运行,运行中,运行成功,运行失败和终止这6种状态。算子在每种状态下显示的控件和能操作的逻辑是不一样的。我们一个最简单的需求就是,在case中验证每一种状态下,UI控件的展示是符合需求的。 比如处于未配置状态的算子是不能运行和停止的, 运行中的算子是可以看见停止按钮但是无法显示运行按钮,相反的配置完成的算子是可以显示运行按钮但是不能展示停止按钮的。
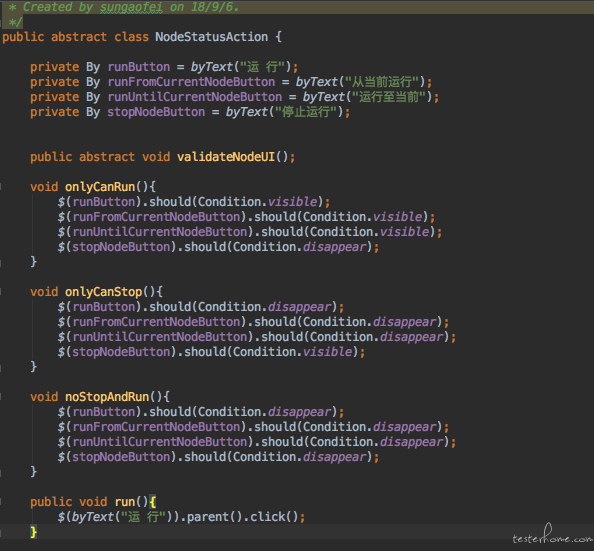
上面是我们的状态抽象类的一部分代码截图。 里面看到有一个抽象方法是validateNodeUI, 用来执行验证操作。 不同状态的子类有着不同的逻辑。 比如下面这个处于Running状态的子类。
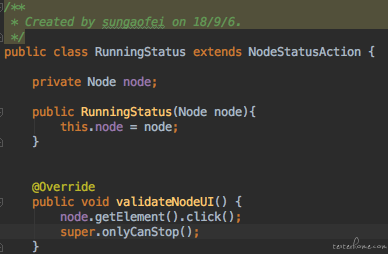
这个running状态的子类覆盖实现了父类的validateNodeUI方法,running状态的算子只能看到停止按钮。 然后我们再看看终止状态的算子和运行成功状态的算子。
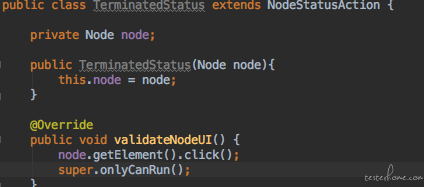
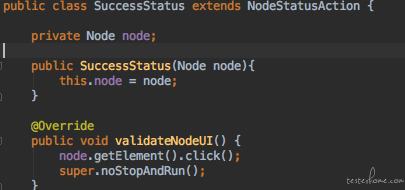
终于状态的算子是可以重新运行的但是看不到停止按钮, 而运行成功的算子因为已经到了算子的最终状态, 所以它既不能运行,也不能停止。 这样我们就有了我们的状态类。 接下来我们看怎么使用这些状态类。 我们需要在所有算子的父类(Node)里写一个查询当前状态的方法。意思是通过UI来查看当前算子的运行状态是哪一种并返回。然后在自己验证控件的方法中,使用相应的状态类。如下:
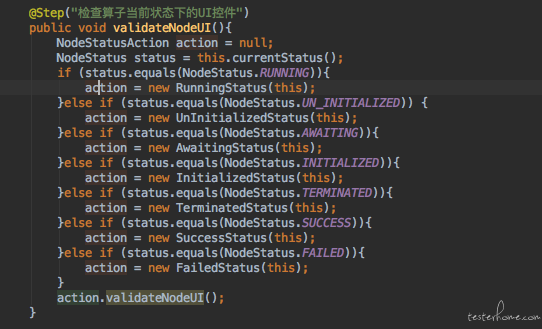
PS: 也许会有小伙伴问上面写了那么多if else来创建各种不同的状态类, 为什么不用工厂模式来做? 那是因为整个项目中只有这一个地方使用了状态类, 也就没有必要专门封装一个工厂类了。 大家要小心过度设计哦~~
这样我们的每一种状态下的UI控件的验证就都写好了。 case中使用的时候入下:
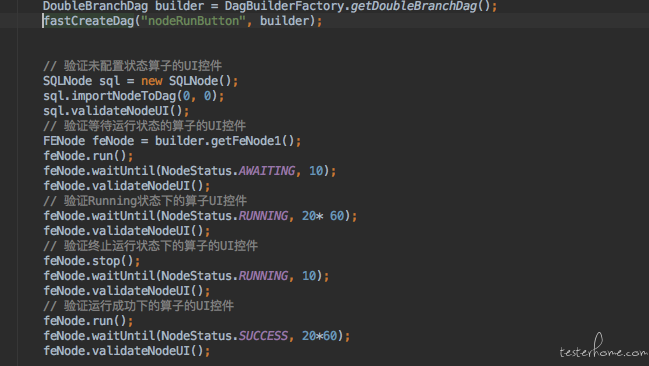
当然状态模式中不只有验证UI控件这一个功能。 由于不同的状态下拥有着不同的行为,假如由于case编写者的失误, 非要在终止状态下的算子上点击终止按钮, 那肯定会在查找控件超时后抛出一个element not found的error出来。 这样有两个不好的地方:
- element not found 的报错信息并不友好,尤其是有些控件的查找方式用xpath查找的,用非文案的方式查找的。 让会再看report的时候并不能很容易看出来错误出在了哪里。需要到代码里去看或者debug。
- 一般查找控件的API都是自旋等待并设定超时时间的,比如我再项目中设置的隐式等待时间是10s. 要等10s后才抛出这个异常也是满耗时的。我们希望立刻就抛出这个错误。
所以不同状态的子类中可以去实现不同的行为, 如下:
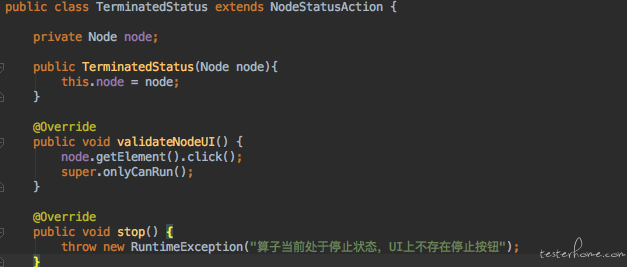
可以看到停止状态的子类的stop方法会直接抛出一个异常。 只要一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为,就可以使用状态模式
接下来分析一下状态模式的优点:
- 在产品复杂业务逻辑和状态流转下, 可以有效的以一种结构化的方式把我们的代码组织起来。 如果我们不使用状态模式,会导致在case或者page类中出现大量的if else。导致后期的维护成本和可读性都很差。
装饰器模式
装饰器,适配器和代理我觉得可以不用分得那么清, 都是为了使现有的类的行为满足我们新的需求,而做的一层封装。 最经典的例子就是java io中的高级流,低级流了。 感兴趣的同学可以去看看。 那么在UI自动化中会有什么情况会用到呢? 最常用的就是重试的功能。 UI自动化是出了名的不稳定的, 有很多公司都会启用失败重跑的功能。 记得我再外包那些年的时候, 经历过的国外公司几乎都会在UI自动化中实现失败重跑的功能。逻辑很暴力,当case运行失败的时候就重跑整个case。 这种暴力的做法优缺点很分明。
优点:
- 实现简单,一些测试框架比如testng已经支持这种功能 缺点:
- 失败的case也会进入report中,要对report单独处理
- 暴力的不管三七二十一,只要失败就重跑的策略会在很多时候大大的增加了测试的执行时间。 比如本来就是bug引起的失败还是会去重新运行的话,最终还是会失败的,白白的浪费了执行的时间和资源。尤其是在像我们这种有很多长时间的异步任务的产品,这种策略更加无法忍受。
鉴于上面说的缺点, 我们希望可以有重试的功能, 但是还比较希望能够控制重试的执行粒度。比如运行时间短的,成本较低的,容易出错的,UI操作复杂的是可以重试的, 但是那些运行时间长的,不容易出错的非UI任务我们是不重跑的。 比如对于我们的产品来说,在UI上设置算子的配置,组件算子的dag图,这些都是UI操作,运行时间较短,但是大量的UI操作是比较容易出错的。 但是这些算子一旦运行起来,就都是后台的操作,UI上没有任何变化,这时候case就是在那里自旋等待,轮询算子状态而已,一般来说,只要算子运行失败了,那基本就是真失败了,就算再跑一次也大概率还是会失败的,即便不是bug,那不管是因为环境问题还是集群问题,都不是一个失败重试能解决的。 所以我们要重试的就是组装Dag的操作。 还记得上一次说建造者模式中的DAGBuilder么? 是的,我们现在就是要对它进行失败重试,dagBuilder只负责构建UI上的复杂操作,并不负责执行和等待后台的任务结束,正是把构建和执行拆分了开来,正合适进行失败重跑的场景(这里也体现出设计原则中的一个类只负责一件事的好处)。 那么问题来了, 原本的DagBuilder就只是一个在UI上构建DAG图的操作,并没有失败重跑的操作。 而我们也并不希望把失败重跑的功能加到DAGBuilder里面, 一来是因为我们要遵循设计原则,只让一个类负责尽量少的事情。 二来是有些情况下,我们也希望没有失败重跑的功能,直接将异常抛出来。由调用方处理。 所以我们使用装饰器模式, 封装一个装饰器类。 如下:
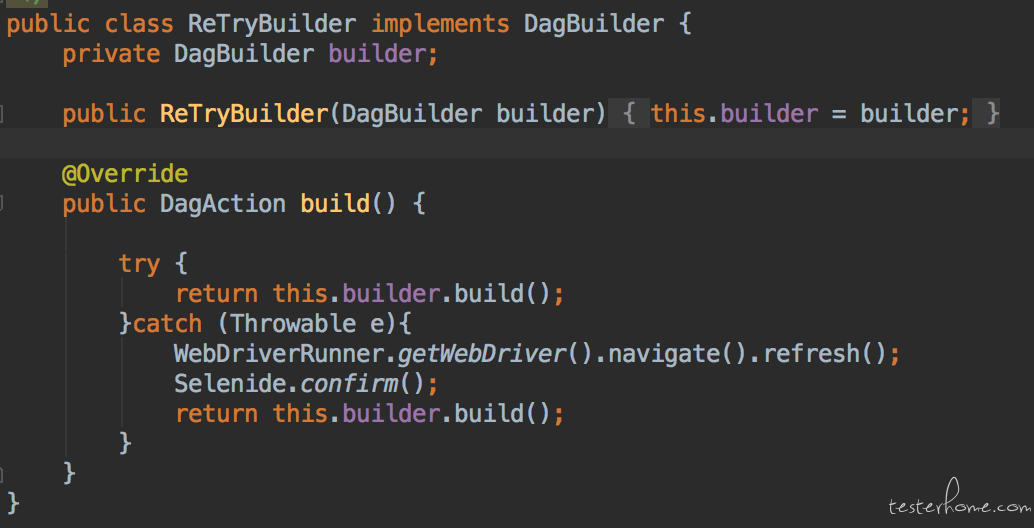
- 装饰器类可以实现被装饰的DagBuilder的接口,保持接口兼容和使用方式一致
- 装饰器类在创建时传递被装饰的对象,然后在方法中调用被装饰的DagBuilder的方法。并添加自己的新功能, 也就是失败重跑。
上面截图中,就是在dagBuilder抛出异常后,捕获异常,然后重置页面初始状态(刷新页面)重新调用DagBuilder的方法。 使用的时候入下:
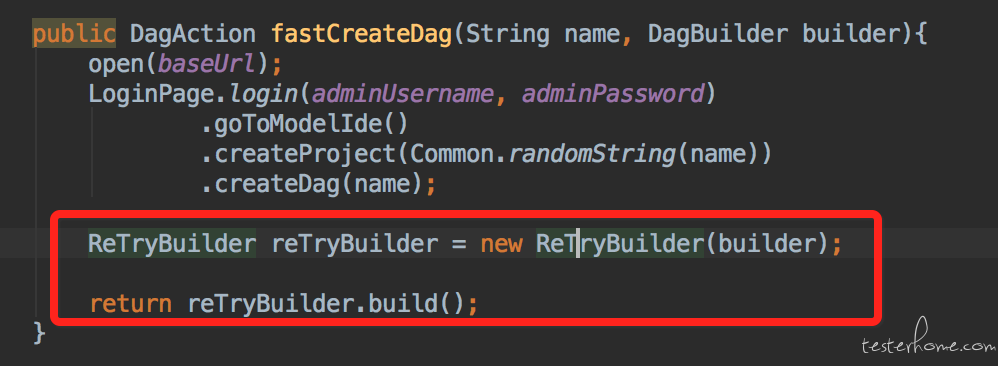
PS: 这里发现我们只对dagBuilder做了失败重试, 大家会发现上面的登录,页面切换,创建project等操作并没有重试的功能。 因为这些操作简单,并且足够稳定, 一旦失败,除开bug的原因就是环境发生了问题或者是UI发生了变化而脚本没有及时更新。不论哪种情况都不是重试能解决的, 当然也有一种情况是环境的服务出现了一些性能问题, 比如我们曾经遇见过集群IO负载过高,导致一个接口请求就数秒甚至10几秒。 所以有时这些稳定简单的操作会超时,这时候重试是有可能会让这些操作跑过去,但是我们是不会这么做的。 因为环境本身就出现了问题,这里我们是希望case就这么直接失败的,减少不必要的运行时间。所谓失败了也要快速的失败,快速的反馈。
PS2:使用python的同学实现失败重试就简单多了, python自带装饰器的语法糖。
原型模式
原型模式是一个很简单的模式,它适用于我们要复制一个对象的时候。 那在UI自动化中,有什么场景需要我们复制一个对象呢。 以我们产品为例,在执行测试的时候,一个DAG中会出现两个相同的算子, 比如一般会有两个特征抽取算子,一个连接训练数据,一个连接测试数据。 但他们两个的配置是相同的(在机器学习中,如果这俩哥们不一样,就出问题了)。 那么问题来了, 我们看要设置一个特征抽取算子都需要哪些参数。
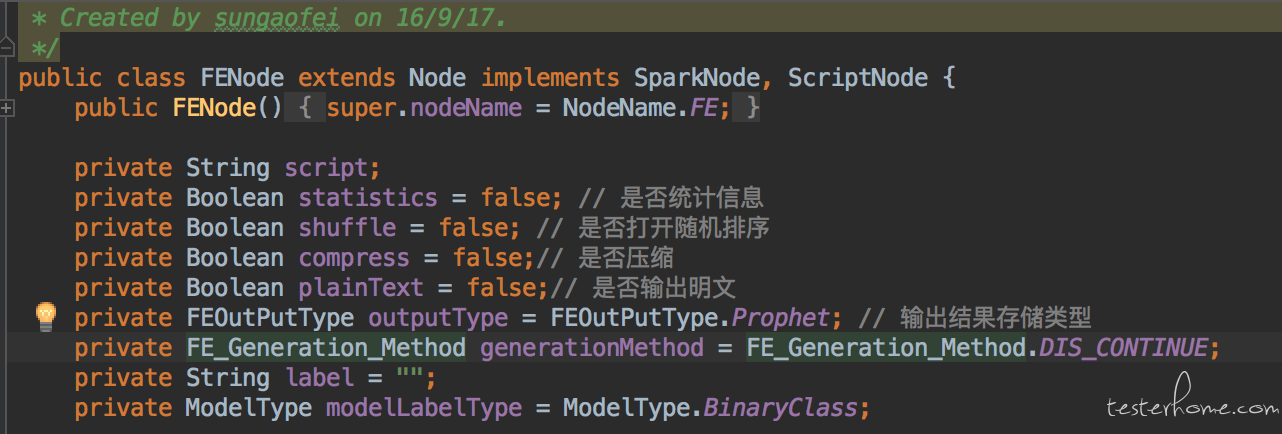
这样就很烦了,我要手动创建两个FENode的对象,把完全相同的参数set进去。也许有小伙伴会说你可以就用一个FENode作为参数,重复利用么。 这也是不行的, 虽然他们的配置相同,但是有一样是不同的。 那就是在UI上搜寻控件的方式。 由于这是两个完全一样的算子,他们拥有相同的文案,相同的控件。唯一能区分他们的方式就是在DOM树中他们的下标[index]。 所以在每个Node里都会有一个额外的属性叫index,表明他们在UI上是第几个同类算子。 如下:

所以如果我们重复使用一个FENode,你会发现你操作的还是同一个FE。 所以这时候我们希望能有一个clone方法, 能够帮我们创造出一个新的对象的同时,还拥有原始对象中一样的属性。 这在java中比较容易实现。 在java中object有clone方法,而所有对象都是集成object的。 所以我们只需要实现一个名字叫Cloneable的空接口,标记本类是可以clone的,就可以直接调用object的clone来完成复制对象的目的了。 如下:

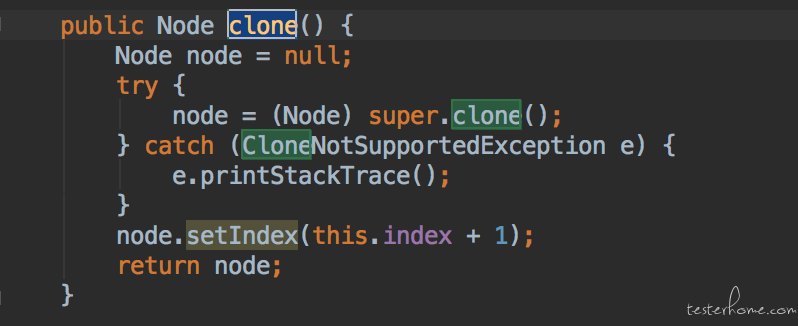
看上面我们直接调用了object的clone来复制对象, 然后让index属性自增1。这样就满足了我们的需要。
原型模式在UI自动化中常见的场景都是类似这种,我们要在UI上做很多相似的UI操作, 这些操作需要传递很多配置。 这些配置大多数是相同的,但是有一小部分是不同的。而我们又不能直接通过不停的改变一个对象的属性来完成这项任务(因为之后还要使用这些对象做其他操作)。 所以需要原型模式出马。比如我们要在项目中导入很多数据。 这些数据的导入方式是差不多的,比如格式,数据源等等, 可能只有数据的路径和名字不一样。 当然我们也可以只使用一个对象,引入一个数据后,立马改变这个对象的数据路径和名字,去引入下一个对象。 这样做也是可以的,但是这样做的坏处是你之后就不能使用这个对象操作之前的那些数据了。 比如我们引入数据后需要等待数据引入结束, 但是你的当前对象的名字和都变成最后一次操作的配置了。 你已经失去了跟踪之前的数据导入的能力了。 所以这时候原型模式就很有用了, 迅速为你clone出一个符合你需求的对象使用。
PS:上面讲的使用object的clone的方式都是浅拷贝, 什么是浅拷贝呢? 比如我们对象中的属性如果有引用类型,例如list,map或者另一个对象。 这时候是不会复制一个新的,而是直接把这些引用类型属性的引用地址复制过来。也就是说,虽然外层对象已经是新的了,但是里面的引用属性使用的还是一个对象。 而如果是深拷贝的话,它是会把引入类型也clone一份出来。 当然如果要实现深拷贝,那就需要我们自己编写逻辑了。 但是大多数情况下浅拷贝是可以满足我们的需求的。 例如上面的关于特征抽取算子的例子,不一样地方只是一个int类型的index。 所以这时候浅拷贝完全够用。