Scrapy的介绍:
Scrapy是基于Twisted的异步处理框架,是纯python语言实现的爬虫框架,特点是架构清晰,模块间耦合度低、扩展性强较为灵活。
框架结构如图所示:
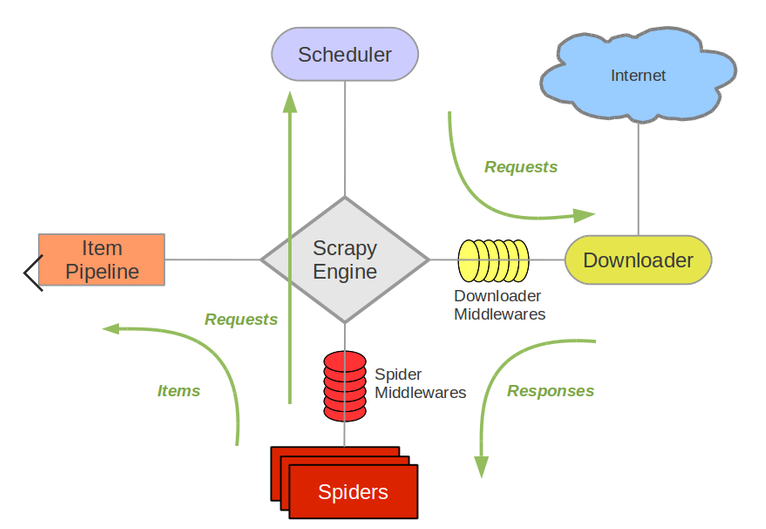
Engine:引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
Item:项目,定义爬虫结果的数据结构,爬去的数据被赋值为该item对象。
Scheduler:调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求时将请求提供给引擎。
Downloader:下载器,下载网页内容,并将内容返还给蜘蛛。
Spiders:蜘蛛,定义爬取的逻辑和网页的解析规则,主要负责解析响应并生成提取结果和新的请求。
Item Pipline:项目管道,负责处理由蜘蛛从网页抽取的项目,主要任务是清洗、验证和存储数据。
Downloader Middlerwares:下载中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
Spider Middlewares:蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
---恢复内容结束---