Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
Python学习资料或者需要代码、视频加Python学习群:960410445
1 启动Scrapy Shell
进入项目的根目录,执行下列命令来启动shell:
scrapyshell"https://hr.tencent.com/position.php?&start=0#a"
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及Selector 对象 (对HTML及XML内容)。
当shell载入后,将得到一个包含response数据的本地 response 变量,输入response.body将输出response的包体,输出response.headers可以看到response的包头。
输入response.selector时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用response.selector.xpath()或response.selector.css()来对 response 进行查询。
Scrapy也提供了一些快捷方式, 例如response.xpath()或response.css()同样可以生效(如之前的案例)。
2 Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
extract(): 序列化该节点为Unicode字符串并返回list
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
response.xpath('//title')
3 Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
验证爬取的数据(检查item包含某些字段,比如说name字段)
查重(并丢弃)
将爬取结果保存到文件或者数据库中
编写item pipeline很简单,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
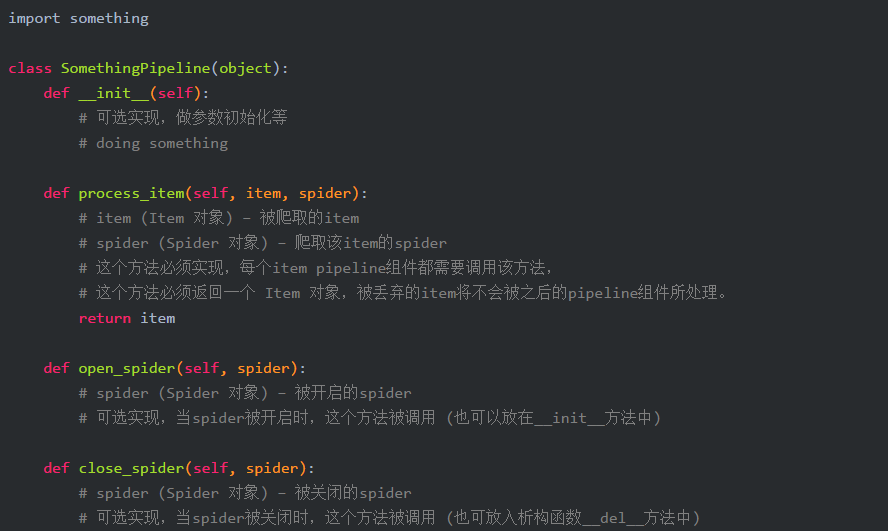
Pipeline实现文件的写入打开操作
以下pipeline将所有(从所有'spider'中)爬取到的item,存储到一个独立地txt文件

启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {'tianya.pipelines.TianyaPipeline':300,}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
4 Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__(): 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse(): 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
源码参考
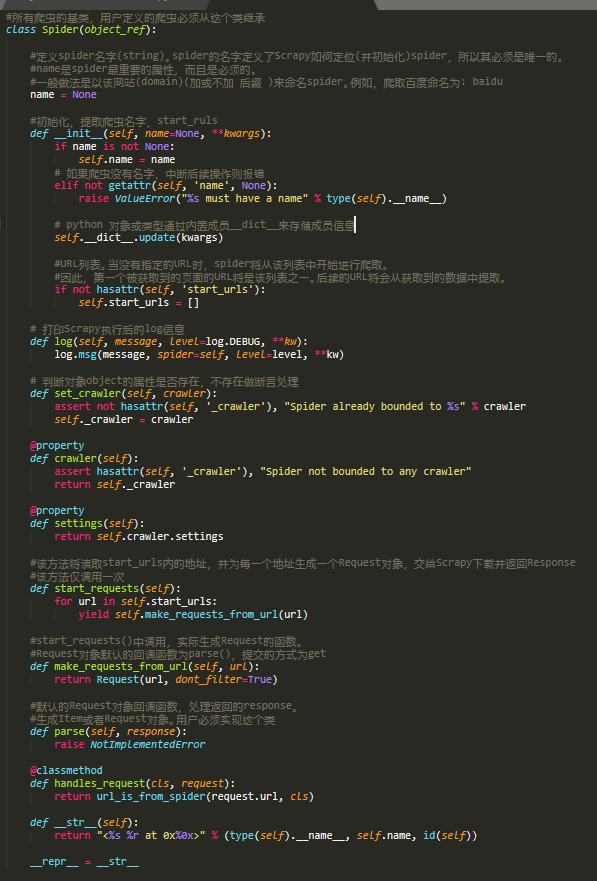
主要属性和方法
name
定义spider名字的字符串。
例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
start_urls
初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见logging
5 案例:腾讯招聘网自动翻页采集
创建一个新的爬虫:
scrapy genspider tencent "tencent.com"
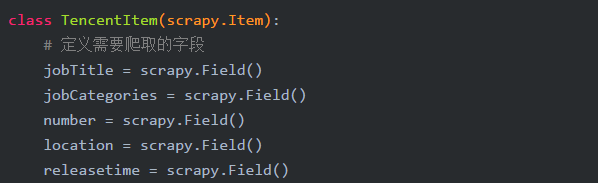
编写items.py
获取职位名称、详细信息、
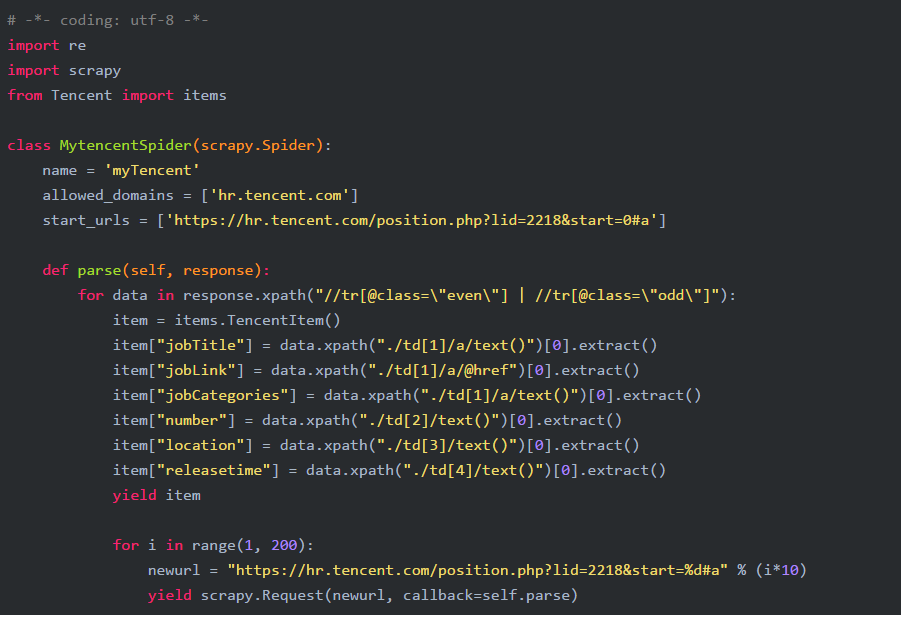
编写tencent.py
编写pipeline.py文件

在 setting.py 里设置ITEM_PIPELINES
ITEM_PIPELINES = {"mySpider.pipelines.TencentJsonPipeline":300}
执行爬虫:
scrapy crawl tencent.py