在之前的文章中对多进程的一些基础概念,进程的生命周期和python进程操作的模块做了说明,本篇文章直接上代码,结束python中创建多进程的一些方法。
os.fork()(Linux)
fork()函数,只在Linux系统下存在。而且它非常特殊,普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后分别在父进程和子进程内返回。子进程永远返回0,而父进程返回子进程的PID。这样一个父进程可以fork()出很多子进程,所以父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID,调用os.getpid()函数可以获取自己的进程号。
代码示例:os.fork()
import os
print (os.getpid())
pid = os.fork() # 创建一个子进程
print (pid) #子进程id和0
if pid == 0:
print ('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print ('I (%s) just created a child process (%s).' % (os.getpid(), pid))

multiprocessing模块
multiprocessing模块就是跨平台版本的多进程管理包,支持子进程、通信和共享数据、执行不同形式的同步。该模块中有以下类/和方法:
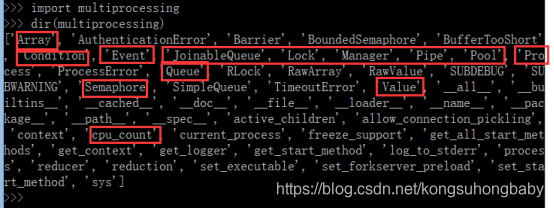
Process类
Multiprocessing模块创建进程使用的是Process类。
Process类的构造方法:
init(self, group=None, target=None, name=None, args=(), kwargs={})
参数说明:
group:进程所属组,基本不用。
target:表示调用对象,一般为函数。
args:表示调用对象的位置参数元组。
name:进程别名。
kwargs:表示调用对象的字典。
代码示例1:
#coding=utf-8
import multiprocessing
def do(n) :
#获取当前线程的名字
name = multiprocessing.current_process().name
print(name,'starting')
print("worker ", n)
return
if __name__ == '__main__' :
numList = []
for i in range(8) :
p = multiprocessing.Process(target=do, args=(i,))
numList.append(p)
p.start()#就绪状态
#子进程执行完毕了才会执行主进程后面的语句。p进程通过join方法通知主进程死等我结束再继续执行。
print("Process end.")
for i in numList:
i.join()#每个进程执行结束才会开始下一个循环
print(numList)#5个进程全部执行完毕才执行print语句,也就是主进程死等
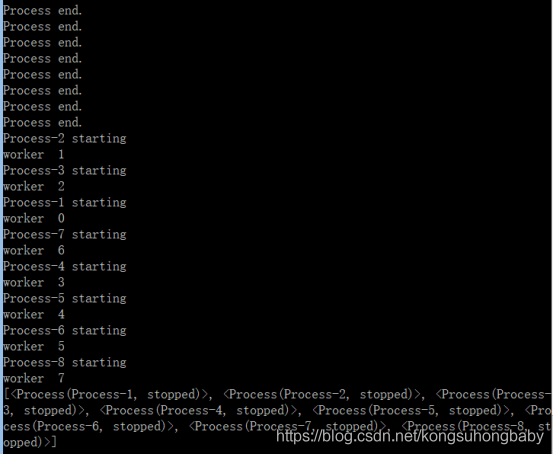
代码示例2:
# -*- coding: utf-8 -*-
from multiprocessing import Process
import os
import time
def sleeper(name, seconds):
print("Process ID# %s" % (os.getpid())) #获取当前进程ID
print("Parent Process ID# %s" % (os.getppid())) #获取父进程ID
print("%s will sleep for %s seconds" % (name, seconds))
time.sleep(seconds)
if __name__ == "__main__":
child_proc = Process(target = sleeper, args = ('bob', 5))
child_proc.start()
print("in parent process after child process start")
print("parent process about to join child process")
child_proc.join()
print("in parent process after child process join" )
print("the parent's parent process: %s" % (os.getppid()))
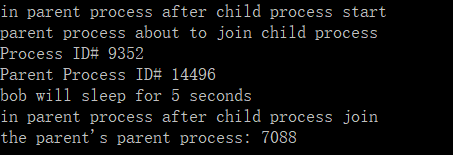
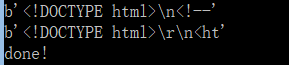
代码示例3: 多进程模板程序
#coding=utf-8
import urllib.request
import time
import multiprocessing
def func1(url) :
response = urllib.request.urlopen(url)
html = response.read()
print(html[0:20])
time.sleep(1)
def func2(url) :
response = urllib.request.urlopen(url)
html = response.read()
print(html[0:20])
time.sleep(1)
if __name__ == '__main__' :
p1 = multiprocessing.Process(target=func1,args=("http://www.sogou.com",),name="gloryroad1")
p2 = multiprocessing.Process(target=func2,args=("http://www.baidu.com",),name="gloryroad2")
p1.start()
p2.start()
p1.join()
p2.join()
time.sleep(1)
print("done!")
代码示例4: 单进程和多进程的执行效率对比
#coding: utf-8
import multiprocessing
import time
def m1(x):
time.sleep(0.05)
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool(multiprocessing.cpu_count())
i_list = range(1000)
time1=time.time()
pool.map(m1, i_list)
time2=time.time()
print('time elapse:',time2-time1)
time1=time.time()
list(map(m1, i_list))
time2=time.time()
print('time elapse:',time2-time1)

进程池Pool
Pool类可以提供指定数量(一般为CPU的核数)的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
如果操作的对象数目上百个甚至更多,那手动去限制进程数量就显得特别的繁琐,此时就可以交给进程池自动管理多个进程。
注意:进程池中的进程是不能共享队列和数据的,而Process生成的子进程可以共享队列
Pool类中常用方法

- apply():
函数原型:apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不再使用)。阻塞的,和单进程没有什么区别 - apply_async():
函数原型:apply_async(func, args=(), kwds={}, callback=None, error_callback=None)
异步非阻塞的,不用等待当前进程执行完毕,随时根据系统调度来进行进程切换(建议使用)
注意:apply_async每次只能提交一个进程的请求 - map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。
注意:
虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程;
map返回的是一个列表,由func函数的返回值组成 - close()
关闭进程池(Pool),使其不再接受新的任务。 - terminate()
立刻结束工作进程,不再处理未处理的任务 - join()
使主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。
代码示例1:简单的进程池apply_async+map
#encoding =utf-8
import time
import multiprocessing
def mul(x):
return x*x
if __name__ =="__main__":
pool = multiprocessing.Pool(multiprocessing.cpu_count())# start 4 worker processes
result = pool.apply_async(mul, [10])
print(result)#multiprocessing.pool.ApplyResult object
print(dir(result))
print(result.get(timeout = 1))#用get方法取出返回结果
print(pool.map(mul,range(10)))

代码示例2:map借助类实现传递多个参数的情况
from multiprocessing import Pool
def f(object):
return object.x * object.y
class A:
def __init__(self,a,b):
self.x =a
self.y =b
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
params = [A(i,i) for i in range(10)]
print(pool.map(f,params)) # prints "[0, 1, 4,..., 81]"

说明:调用map的时候不需要先执行close关闭进程池,但是join不调用close的话会报错
代码示例3:多进程与单进程执行时间比较
#encoding=utf-8
import time
from multiprocessing import Pool
import os,multiprocessing
def run(num):
time.sleep(1)
return num * num
if __name__ == "__main__":
testList = [1,2,3,4,5,6,7]
print('单进程执行')#顺序执行
t1 = time.time()
for i in testList:
run(i)
t2 = time.time()
print('顺序执行的时间为:',int(t2-t1))
print('多进程执行')#并行执行
pool = Pool(multiprocessing.cpu_count())#创建拥有4个进程数量的进程池
result = pool.map(run,testList)
pool.close()#关闭进程池,不再接受新的任务
pool.join()#主进程阻塞等待子进程的退出
t3 = time.time()
print('并行执行的时间为:',int(t3-t2))
print(result)

说明:
并发执行的时间明显比顺序执行要快很多,但是进程是要耗资源的,所以进程数也不能开太大。
程序中的result表示全部进程执行结束后全局的返回结果集,run函数有返回值,所以一个进程对应一个返回结果,这个结果存在一个列表中,也就是一个结果堆中,实际上是用了队列的原理,等待所有进程都执行完毕,就返回这个列表(列表的顺序不定)。
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),让其不再接受新的Process。
代码示例4:进程池中的进程不能共享队列
#encoding=utf-8
import time
from multiprocessing import Pool,Queue,Process
def func( q):
print('*'*30)
q.put('1111')
if __name__ == "__main__":
queue = Queue() #直接用multiprocessing.Queue生成队列
pool = Pool(4)#生成一个容量为4的进程池
for i in range(5):
pool.apply_async(func, (queue,))#向进程池提交目标请求
pool.close()
pool.join()
print(queue.qsize())

说明:
print(queue.qsize())输出的结果是0,而且func函数中的print也没有执行,如果不传入q的话,func函数就能正确执行,原因是进程池中每个进程都有自己独立的队列,是不共享的,解决方法有两种:一是用Process生成进程,二是用multiprocessing.Manager.Queue()生成共享队列。修改后的代码如下:
方法一:Process生成进程
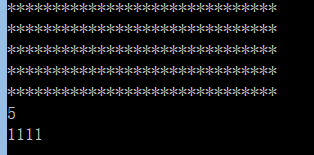
#encoding=utf-8
import time
from multiprocessing import Pool,Queue,Process
import multiprocessing
def func( q):
print('*'*30)
q.put('1111')
if __name__ == "__main__":
queue = Queue()
p_list = []
for i in range(5):
p = Process(target = func, args=(queue,))
p_list.append(p)
for p in p_list:
p.start()
for p in p_list:
p.join()
print(queue.qsize())
print(queue.get())
方法二:multiprocessing.Manager.Queue()
#encoding=utf-8
import time
from multiprocessing import Pool,Queue,Process
import multiprocessing
def func( q):
print('*'*30)
q.put('1111')
if __name__ == "__main__":
m = multiprocessing.Manager()
queue = m.Queue()
pool = Pool(4)#生成一个容量为4的进程池
for i in range(5):
pool.apply_async(func, (queue,))#向进程池提交目标请求
pool.close()
pool.join()
print(queue.qsize())
