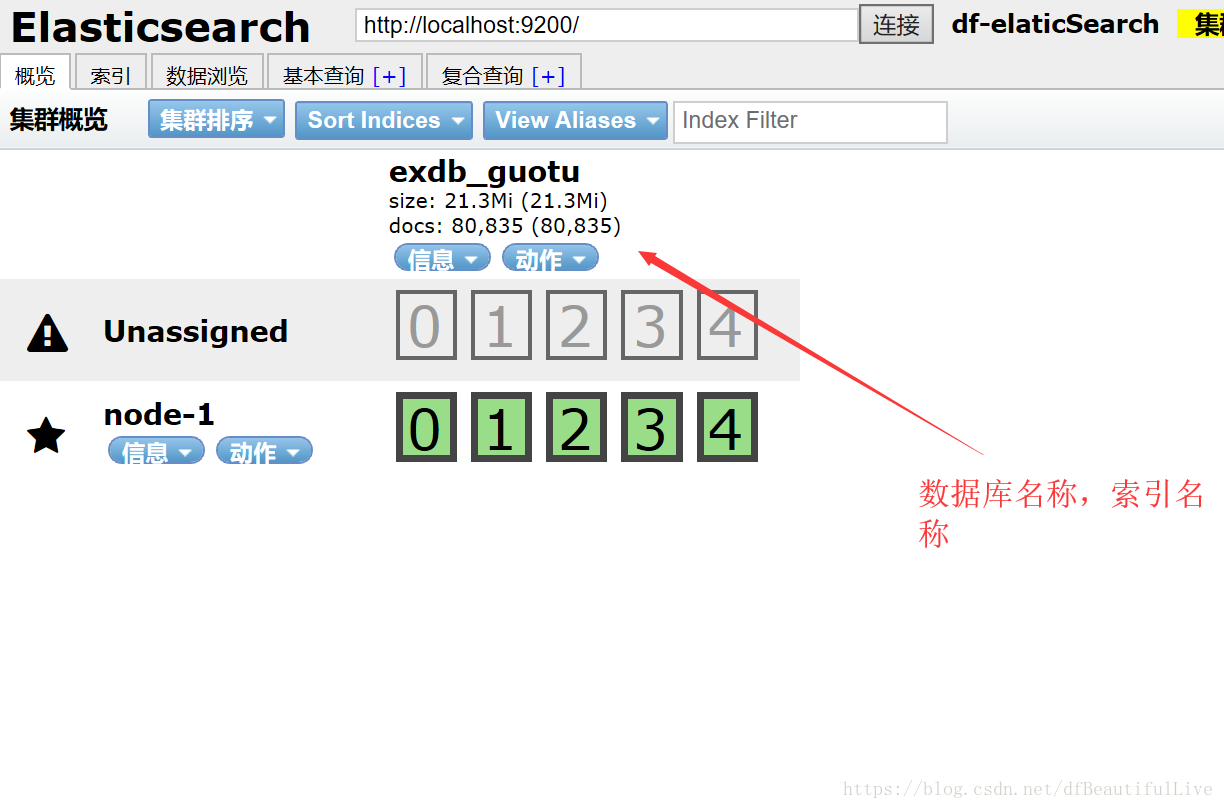
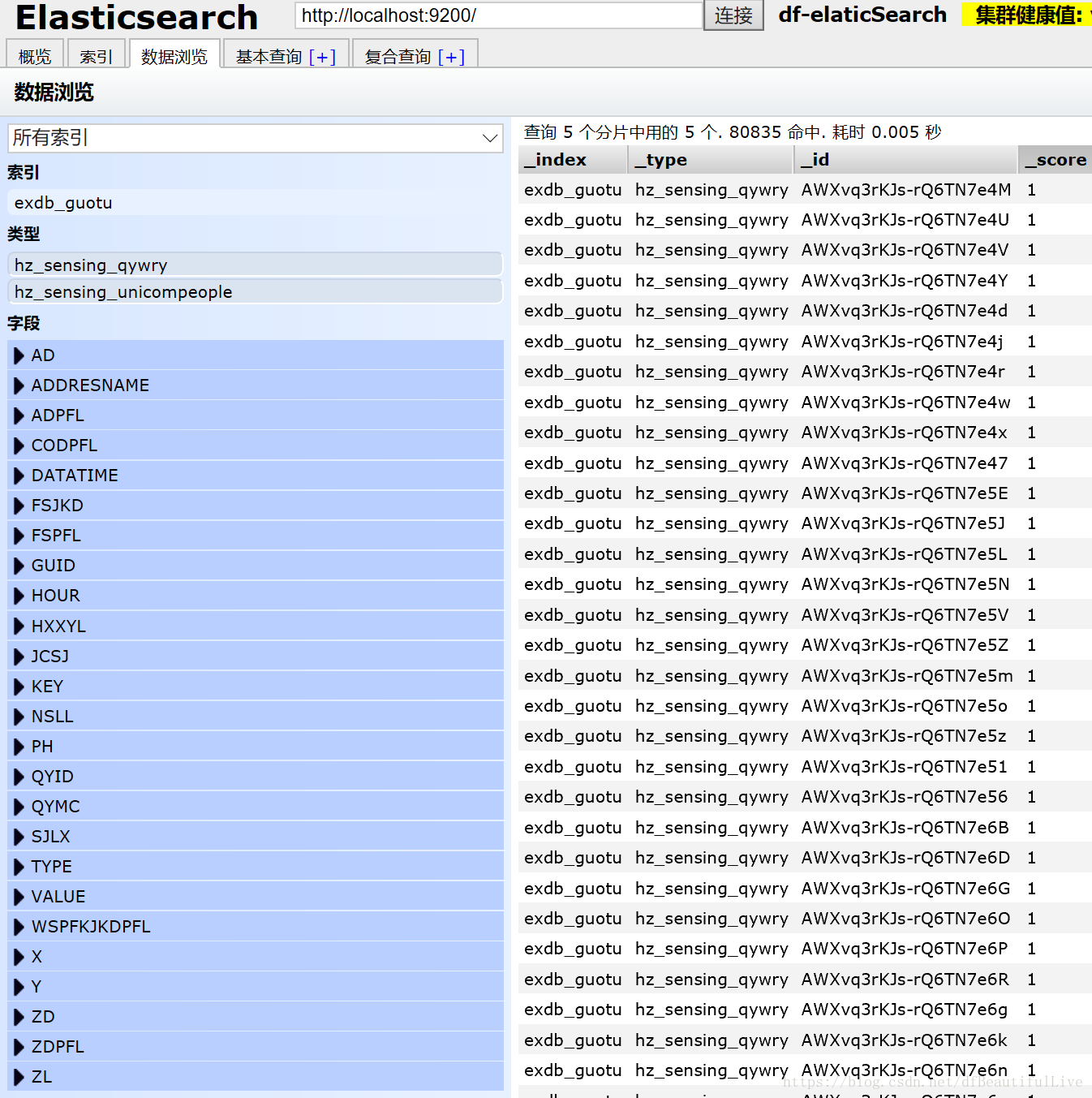
Elasticsearch查询搜索真的是非常快,所以企业数据量大的一般都存储到Elasticsearch里。用来分析,挖掘数据,
Elasticsearch的索引就相当于数据库,类型,就相当于表,文档就相当于数据库的row
索引-index
- 一个索引就是一个拥有几分相似特征的文档的集合
- 相当于数据库中的database
类型-type
- 一个类型是你的索引的一个逻辑上的分类/分区
- 通常,会为具有一组共同字段的文档定义一个类型
- 相当于数据库中的table
文档-document
- 一个文档是一个可被索引的基础信息单元
- 文档以JSON(Javascript Object Notation)格式来表示
- 相当于数据库中的row
分片-shard
- 一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎
- 一个索引可以有多个分片,必须在创建索引的时候指定分片数量,不能动态修改分片数量
- 多个分片主要是为了提高写入效率
副本-replicas
- 就是分片的副本,副本分片的主要目的就是为了故障转移
- 主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色
- 在索引写入时,新文档首先被索引进主分片然后再同步到其它所有的副本分片
- 副本分片可以服务于读请求,可以通过增加副本的数目来提升查询性能
废话少说,先实战吧
对了,一定要之前下载Elasticsearch,然后启动,才可以使用哦
首先引入Elasticsearch的依赖包,有很多不同的jar依赖,我目前就选择了jest客户端和transport客户端两种方式
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.5.3</version>
</dependency>配置文件:#jest连接方式需要的配置 配置elasticsearch
spring:
elasticsearch:
jest:
uris:
- http://127.0.0.1:9200
read-timeout: 5000
#连接数据源
datasource:
url: jdbc:oracle:thin:@192.168.0.86:1521:ORCL86
username: exdb_guotu
password: exdb_guotu
driver-class-name: oracle.jdbc.driver.OracleDriver
nitialSize: 5
maxWait: 60000
minIdle: 5transport连接方式,配置,写在代码里,不用transport可以不用这段代码 package com.config;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.stereotype.Component;
import java.net.InetAddress;
/**
* Created by df on 2018/9/19.
*/
@Component
public class TransportClientUitl {
private TransportClient transportClient;
//transportClient的加载配置
public TransportClient getClient() throws Exception{
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "df-elaticSearch").build();// 集群名
//集群名称就是我们Elasticsearch的名称,我的是我自己起的
//创建client
transportClient = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
return transportClient;
}
}
先来个测试,添加个实体,实体里边放索引和类型,还有存储的字段
package com.entity;
/**
* Created by df on 2018/9/17.
*/
public class entity {
public static final String INDEX_NAME = "df_index";//相当于数据库名称
public static final String TYPE = "df_tstype";//相当于表名
private String key;
private String Value;
public entity(){
super();
}
public entity(String key,String Value){
this.key=key;
this.Value=Value;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public String getValue() {
return Value;
}
public void setValue(String value) {
Value = value;
}
}
然后就可以对Elasticsearch做增删改查了
package com.service;
import com.config.TransportClientUitl;
import com.entity.entity;
import com.sqlSource.SqlHadle;
import io.searchbox.client.JestClient;
import io.searchbox.client.JestResult;
import io.searchbox.core.*;
import io.searchbox.indices.DeleteIndex;
import io.searchbox.indices.mapping.GetMapping;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* Created by df on 2018/9/17.
*/
@Service
public class testServiceImpl implements testService {
private static final Logger LOGGER = LoggerFactory.getLogger(testServiceImpl.class);
@Autowired
private JestClient jestClient;
/**
* 插入单个数据
*/
@Override
public void saveEntity(entity en) {
Index index = new Index.Builder(en)
.index(entity.INDEX_NAME).type(entity.TYPE).build();
try {
jestClient.execute(index);
LOGGER.info("ES 插入完成");
} catch (IOException e) {
e.printStackTrace();
LOGGER.error(e.getMessage());
}
}
SqlHadle sqlHadle = new SqlHadle();
/**
* 批量插入多个
* index 索引名(数据库名)
* type 类型(表)
*/
@Override
public void insertBatch(String index, String type) {
//从数据库查询出来的数据 然后在存储到Elasticsearch里
List<Map<String, Object>> entityList = sqlHadle.queryTest();
long startTime = System.currentTimeMillis();
boolean result = false;
try {
//Bulk方式
Bulk.Builder bulk = new Bulk.Builder().defaultIndex(index).defaultType(type);
for (Map map : entityList) {
Index index1 = new Index.Builder(map).build();
bulk.addAction(index1);
}
BulkResult br = jestClient.execute(bulk.build());
result = br.isSucceeded();
} catch (IOException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("批量新增:" + result + " 消耗了" + (endTime - startTime) + "ms");
}
/**
* 查询某一个字段
* searchContent 查询的属性值
* key 字段名称
*/
@Override
public List<entity> searchEntity(String searchContent, String key) {
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery(key, searchContent));
Search search = new Search.Builder(builder.toString()).addIndex(entity.INDEX_NAME)
.addType(entity.TYPE).build();
try {
JestResult result = jestClient.execute(search);
return result.getSourceAsObjectList(entity.class);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 删除某个id下的文档,想知道id可以去Elasticsearch的共工具里看,也可以用程序获取
* id 文档id
* index 索引名(数据库名)
* type 类型(表)
*/
@Override
public void deleteDoc(String id, String index, String type) {
Delete delete = new Delete.Builder(id).index(index).type(type).build();
JestResult result = null;
try {
result = jestClient.execute(delete);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除某个索引
* index 索引名(数据库名)
*/
@Override
public void deleteIndex(String index) {
DeleteIndex deleteIndex = new DeleteIndex.Builder(index).build();
JestResult result = null;
try {
result = jestClient.execute(deleteIndex);
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 查询所有 结果Elasticsearch默认只能查出10条,最多的size也只能10000条
* index 索引名(数据库名)
* type 类型(表)
*/
@Override
public void searchAll(String index, String type) {
GetMapping getMapping = new GetMapping.Builder().addIndex(index)
.addType(type).build();
try {
JestResult jr = jestClient.execute(getMapping);
System.out.println(jr.getJsonString());
} catch (IOException e) {
e.printStackTrace();
}
// SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// sourceBuilder.query(QueryBuilders.matchAllQuery());
// Search search = new Search.Builder(sourceBuilder.toString()).addIndex("df_index").build();
// SearchResult result = null;
// List his = null;
// try {
// result = jestClient.execute(search);
// System.out.println("本次查询共查到:" + result.getTotal() + "个关键字!");
// his = result.getHits(Object.class);
// } catch (IOException e) {
// e.printStackTrace();
// }
// return his;
}
/**
* 全文搜索 根据某个字段全篇搜索
* indexName 索引名(数据库名)
* typeName 类型(表)
* query 字段
* query数据是这种格式
* query="{\n" +
" \"from\" : 0,\n" +
" \"size\" : 9999,\n" +
" \"query\" : {\n" +
" \"query_string\" : {\n" +
" \"query\" : \"惠州\"\n" +
" }\n" +
" }\n" +
"}\n";
*/
@Override
public String search(String indexName, String typeName, String query) {
long startTime = System.currentTimeMillis();
Search search = new Search.Builder(query).addIndex(indexName).addType(typeName).build();
JestResult jr = null;
try {
jr = jestClient.execute(search);
long endTime = System.currentTimeMillis();
System.out.println("Elasticsearch中查询消耗:" + (endTime - startTime) + "ms");
} catch (IOException e) {
e.printStackTrace();
}
return jr.getJsonString();
}
@Autowired
private TransportClientUitl clientUitl;
/**
* 滚动分页,采用的是TransportClient客户端方式操作
* 这个滚动分页其实是查询索引里的全部数据,这个效率最高,最快,每一次滚动设置查询多少页,
* 然后下一次找到这一次记录的id然后继续滚动,直至数据都没有为止
* 采用条件:数据量大,
* query 查询需要的配置,如下query变量所示
* indexName 索引名(数据库名)
* typeName 类型(表)
*/
String query= "\"{\" +\n"+
" \" \\\"query\\\":{\" +\n"+
" \" \\\"match\\\":{\\\"srv_content\\\":\\\"google\\\"}}\" +\n"+
" \" }\" +\n"+
" \"}\"";
public void searchScroll(String query, String indexName, String typeName) {
long startTime = System.currentTimeMillis();
try {
SearchRequestBuilder searchBuilder = clientUitl.getClient().prepareSearch(indexName);
searchBuilder.setTypes(typeName);
//设置每批读取的的数据量
searchBuilder.setSize(10000);
//默认是查询所有
searchBuilder.setQuery(QueryBuilders.queryStringQuery("*:*"));
//设置 search context 维护1分钟的有效期
searchBuilder.setScroll(TimeValue.timeValueMillis(3));
//获得首次查询结果
SearchResponse searchResponse = searchBuilder.get();
System.out.println("命中总数量:" + searchResponse.getHits().getTotalHits());
//打印计数
int count = 1;
do {
System.out.println("第" + count + "次打印数据:");
for (SearchHit hit : searchResponse.getHits().getHits()) {
// System.out.println(hit.getSource());
}
count++;
//将scorllId循环传递
searchResponse=clientUitl.getClient().prepareSearchScroll(searchResponse.getScrollId())
.setScroll(TimeValue.timeValueMillis(1)).execute().actionGet();
//当searchHits的数组为空的时候结束循环,至此数据全部读取完毕
} while (searchResponse.getHits().getHits().length != 0);
long endTime = System.currentTimeMillis();
System.out.println("Elasticsearch中查询所有的数据消耗:" + (endTime - startTime) + "ms");
} catch (Exception e) {
e.printStackTrace();
}
}
}对Elasticsearch做基本的增删改查就弄好了,附赠两个Elasticsearch做完操作的图片