本项目主要实现逻辑如下:
- 数据获取
- 数据处理
- 导入neo4j
本项目需要用到两种数据源:一种是公司董事的信息,另一种是股票的行业以及概念信息。
董事信息通过scrapy进行爬取,具体包含各个上市公司董事会成员姓名、职位、性别、年龄。股票的行业及概念信息通过Tushare信息进行获取。
1.董事信息获取
我们通过访问’http://pycs.greedyai.com/’ 来获取上市公司的董事信息,主要获取董事的姓名、职位、性别、年龄
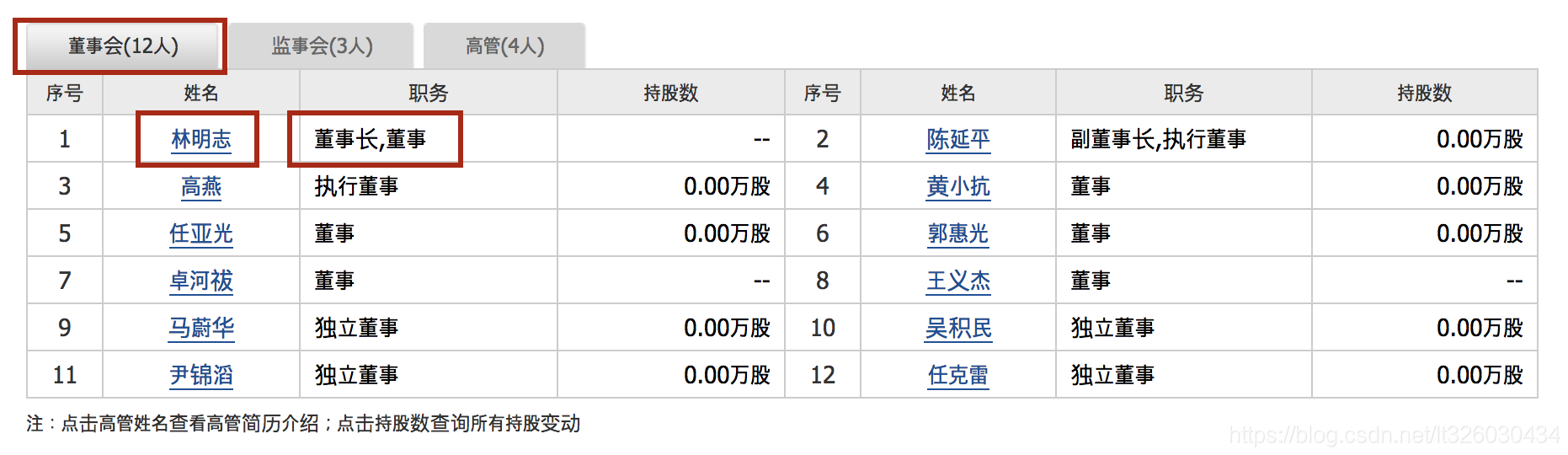
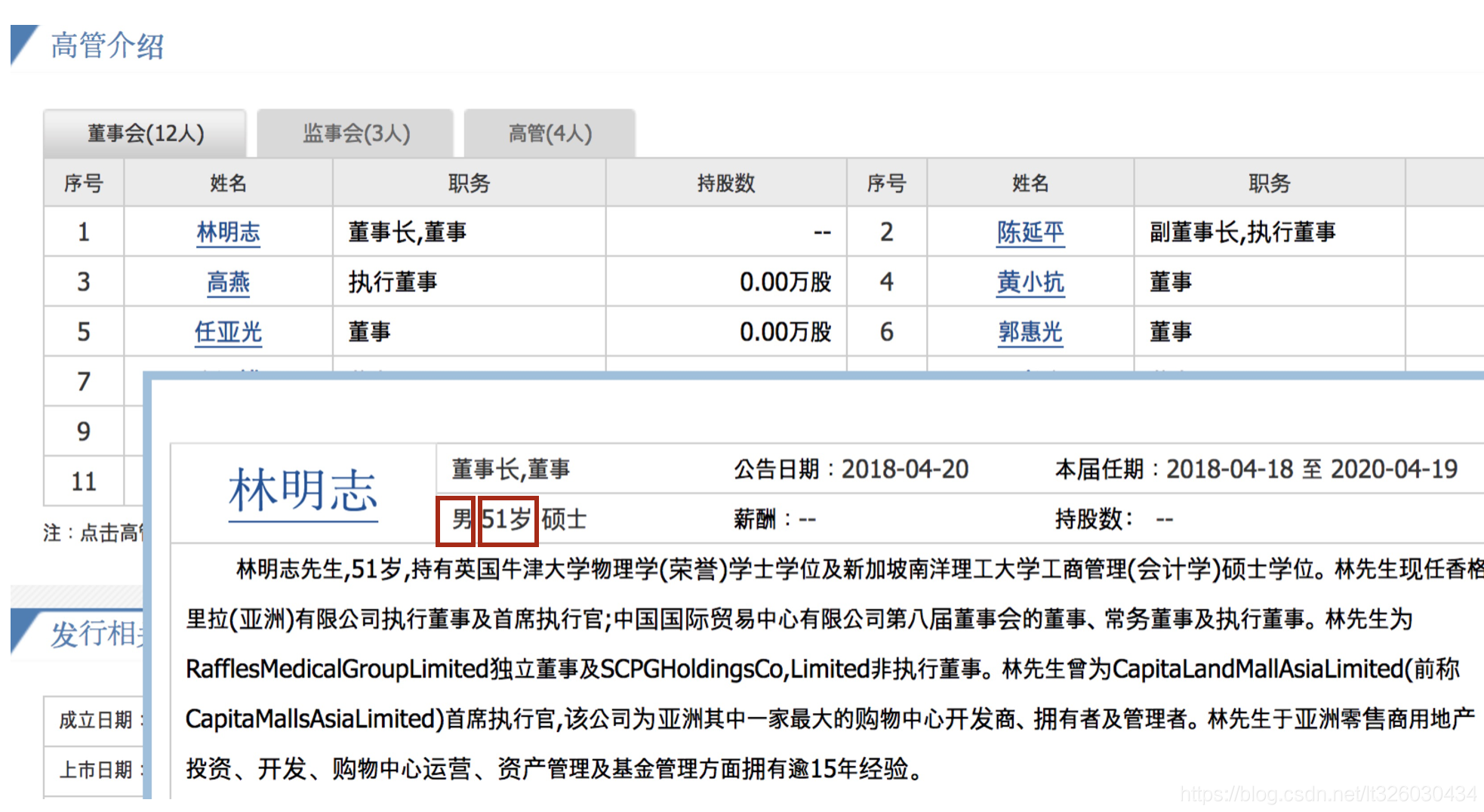
scrapy部分代码如下:
# -*- coding: utf-8 -*-
import scrapy
import re
from bs4 import BeautifulSoup
from securities.spiders.savecsv import save_csv
from securities.items import GetItem
class UserinfoSpider(scrapy.Spider):
name = 'userinfo'
allowed_domains = ['pycs.greedyai.com']
start_urls = ['http://pycs.greedyai.com']
def parse(self, response):
body = response.css('body').extract()
url = re.findall('"\.(.*?html)"', body[0])
for u in url:
yield scrapy.Request(url='http://pycs.greedyai.com' + u,callback=self.get_info)
def get_info(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
code = re.findall('\d{6}', soup.head.title.text)[0]
list = []
tbody_tag = soup.select('#ml_001 > table > tbody')[0]
m = 0
for cd in tbody_tag.children:
if m % 2 != 0:
n = 0
for user_tag in cd.children:
if n % 8 == 3:
thead_tag = str(user_tag.div.table.thead)
name = re.findall('target="_blank">(.*?)</a>', thead_tag)[0]
jobs = re.findall('<td class="jobs" style="width: 150px;">(.*?)</td>', thead_tag)[0]
intro = re.findall('<td class="intro">(.*?)</td>', thead_tag)[0]
sex = re.findall('\u7537|\u5973', intro)[0]
age = re.findall('(\d*?)\u5c81', intro)[0]
info = GetItem()
info['name'] = name
info['sex'] = sex
info['age'] = age
info['code'] = code
info['jobs'] = jobs
yield info
n += 1
break
m = 1
抓取完的信息保存至executive_prep.csv文件

2.获取股票的行业及概念信息
这部分直接通过Tushare获取
import tushare as ts
df = ts.get_industry_classified()
df = ts.get_concept_classified()
获取结果保存至stock_industry_prep.csv和stock_concept_prep.csv文件
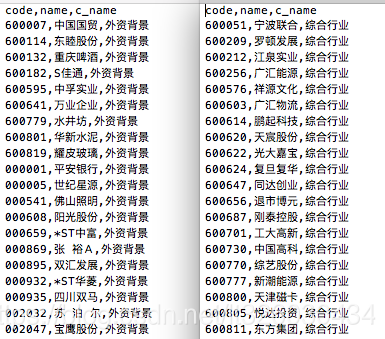
3.数据处理
前两步完成了数据的获取,这里要将获取到的数据转换成neo4j可识别的具体格式。
对于格式的要求,请参考:https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/
代码部分只是简单的csv文件操作,在此不做过多阐述,处理完的数据,分别保存不同的csv文件:“executive.csv”, “stock.csv”, “concept.csv”, “industry.csv”, “executive_stock.csv”, “stock_industry.csv”, “stock_concept.csv”。
在此只挑一个节点和一条关系做简单演示。

executive节点,保存董事姓名、性别、年龄、股票代码、职位信息
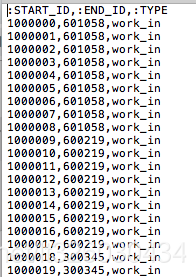
executive_stock关系,声明董事与公司的关系为work_in
4.导入neo4j
将上述所有文件导入neo4j
bin/neo4j-admin import --nodes import/executive.csv --nodes import/stock.csv --nodes import/concept.csv --nodes import/industry.csv --relationships import/executive_stock.csv --relationships import/stock_industry.csv --relationships import/stock_concept.csv
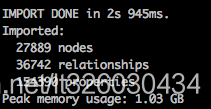
能看到我们一共导入了27889个节点和36742个关系,然后启动neo4j,就可以看到我们导入的数据了。
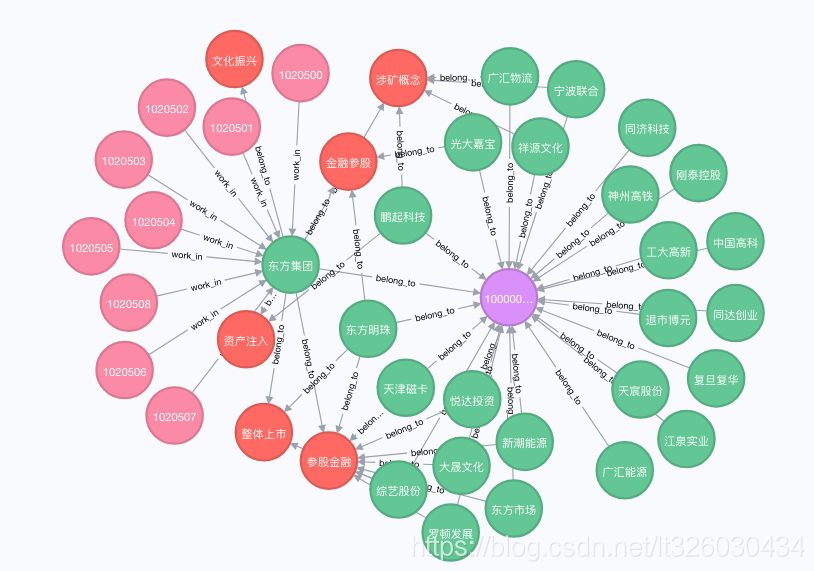
比如我们随便查看一支股票相关联的信息,比如“东方集团”
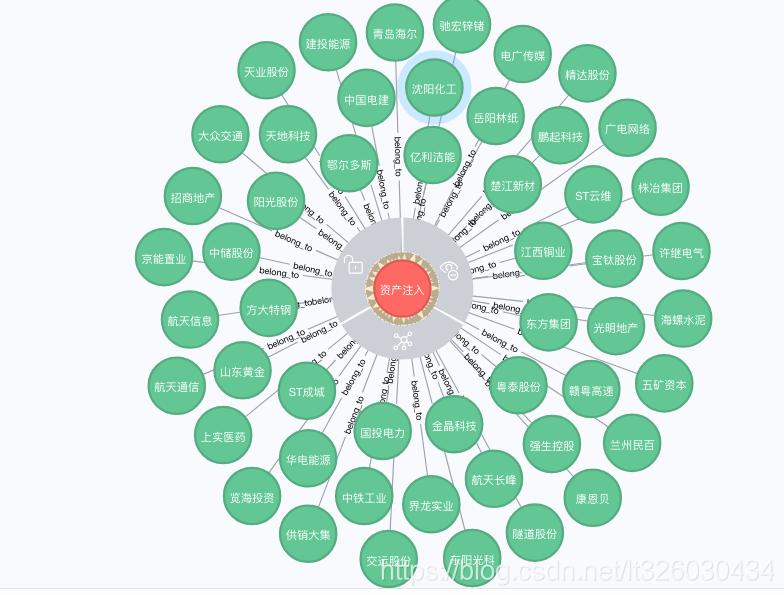
或者随便看一个概念“资产注入”
小型的证券知识图谱搭建到这里就结束了,所有源码及测试数据已上传至git,点击这里可直接查看,有疑问的同学请在博客下方留言或提Issuees,谢谢!