python支持多线程,支持多进程。多线程操作显然比单线程耗时更低。
多线程实现中有gil锁,所以效率不会有想象的高。
然后有个猜想:在CPU密集型任务下,多进程更快,或者说效果更好;而IO密集型,多线程能有效提高效率。
import requests
import time
import queue
import threading
hosts = ['http://baidu.com','http://jianshu.com','http://taobao.com',
'http://tmall.com','http://jd.com']
queue = queue.Queue()
#这里定义队列
class ThreadUrl(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self.queue = queue #面向对象的优雅变量使用方式
#初始化,并调用queue
def run(self):
while True:
host = self.queue.get()#get()一次就是从队列中取了一次
res = requests.get(host)
print(res.text)
print(self.getName())
self.queue.task_done()
#配合join()使用,task_done一次,queue的长度减少1.当
#queue长度为0时,join()才会发生作用
start1 = time.time()
#这里是取时间
def main():
for i in range(5):
t = ThreadUrl(queue)
t.setDaemon(True)
t.start()
for host in hosts:
queue.put(host)
queue.join()
if __name__ == '__main__':
main()
print ('it use time:%s'%(time.time()-start1))
#计算用时
#和使用线程的程序进行比较
import requests
import time
hosts = ['http://baidu.com','http://jianshu.com','http://taobao.com',
'http://tmall.com','http://jd.com']
start1 = time.time()
for i in hosts:
res = requests.get(i)
print(res.text)
print('the time has used is %s'%(time.time()-start1))
两个的运行结果
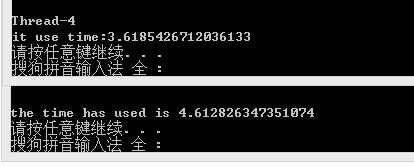
大概就是这样,不过多线程爬一般都用scrapy框架了,仅作了解。