互联网包括了至今为止最有效的数据集,并且大年夜大年夜局部能地下收费拜候。但这些数据根基上不克不及复用。它们被嵌入在网站的布局、样式中,得抽取出来才调应用。我们从网页中抽取数据的过程就是我们熟知的汇集爬虫,互联网期间每天都有大年夜大年夜量的信息被颁布发表到汇集上,汇集爬虫也愈来愈有效。

互联网包含了迄今为止最有效的数据集,并且大年夜大年夜局部可以收费地下拜候。

在这里相信有许多想要学习Python的同学,大家可以+下Python学习分享裙:叁零肆+零伍零+柒玖玖,即可免费领取一整套系统的 Python学习教程!
爬虫甚么时辰有效
假定我有一个服装店,并且想要及时知道竞争敌手的代价。

总之,我们不克不及仅仅依托于API去拜候我们所需的在线数据,而是该当进修一些汇集爬虫技能的相干常识。
本书基于Python 3
在本书中完全应用Python 3遏制开辟

关于初学者来讲,我引荐应用Conda,因为其需要的装配任务更少一些。

编写第一个汇集爬虫
抓取网站数据,我们起首得下载包含有感兴味数据的网页,这个过程称之为爬取(crawling)。

1、抓取与爬取的对比
根据我们所存眷的信息和站点内容、布局的不合,可以或许需要遏制汇集抓取或是网站爬取。
那么它们有甚么差别呢?

例如:可否只用于抓取?可否也合用于爬虫?

2、下载网页
我们要想抓取网页的话,起首需要将其下载上去。示例脚本应用urllib模块下载URL。

传入URL参数时,该函数将会下载网页并前去其HTML。不过,这个代码片段存在一个结果,当我们下载网页时,可以或许会碰着一些没法节制的缺点,比如恳求的页面可以或许不存在。这个时辰urllib会抛出异常,然撤离撤离出脚本。
安然起见,下面再给出一个更稳建的版本,可以捕获这些异常。

此刻,当呈现下载或URL缺点时,该函数可以或许捕获到异常,然后前去None。

3、重试下载
我们不才载时碰着的缺点通俗都是临时性的,例如处事器过载时前去的503 Service Unavailable缺点。

下面是支慎重试下载功用的新版本代码:
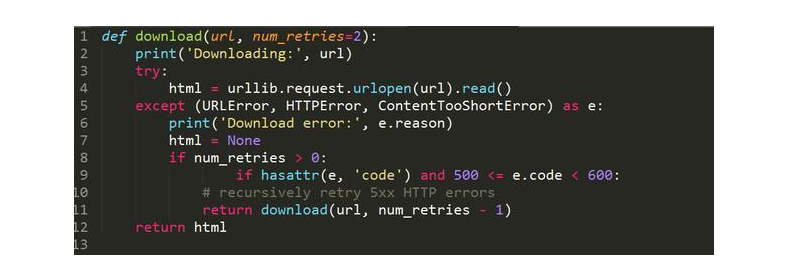
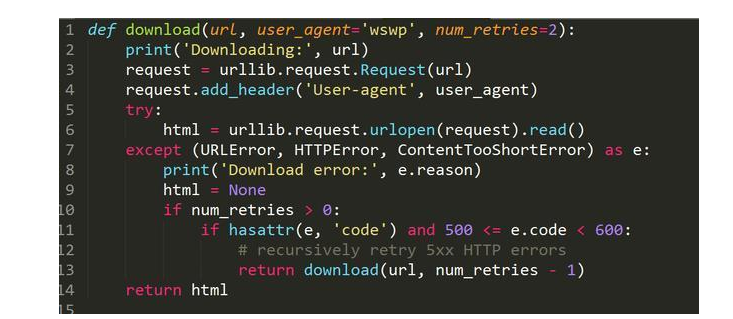
此刻,在download函数碰着5xx缺点码时,会递归调用函数本身来重试。该函数还增加了一个参数,用于设定重试下载的次数,默觉得两次。之所以在这里限制网页下载查验查验次数,可以或许是处事器缺点临时还木有恢复。想要测这个该函数,可以查验查验下载http://httpstat.us/500,这个网址会一向前去500缺点码。
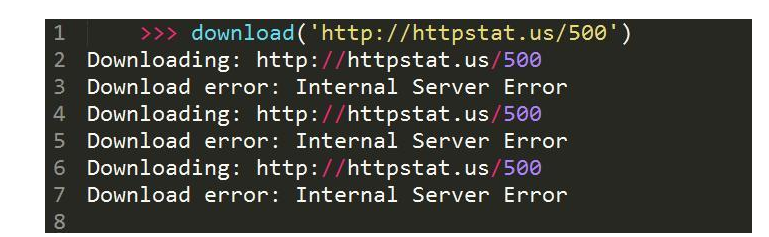
畴前去的结果可以看出,download函数的行动和预期不合,先查验查验下载网页,在采取到500缺点后,又遏制了两次重试才对峙。

4、设置用户代办代理
在默许状况下urllib应用Python-urllib/``3.x作为用户代办代理下载网页内容,3.x是正在应用的Python版本号。

即Web Scraping with Python的首字母缩写
此刻再次拜候meetup.com,便可以看到一个合法的HTML了。下载函数在后续代码中可以获得复用,这个函数可以或许捕获异常,在可以或许的状况下重试网站和设置用户代办代理。

5、网站地图爬虫
在第一个简单的爬虫中,我们将应用示例网站robots.txt文件中发现的网站地图来下载一切网页。为知道析网站地图,就用一个简单的正则表达式,从标签中提取出URL。需要更新代码以措置编码转换,因为今朝的download函数只是简单地前去了字节。
代码:

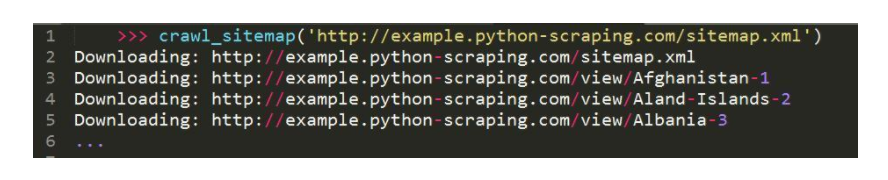
此刻运转网站地图爬虫,从示例网站中下载一切国度或地区页面。
正以下面代码中的download编制所示,我们必须更新字符编码才调应用正则表达式措置网站照顾。

下一节中,我们将会引见另外一个简单的爬虫,该爬虫不再依托于Sitemap文件。

6、ID遍历爬虫
本节中应用网站布局的弱点,加倍轻松地拜候一切内容。
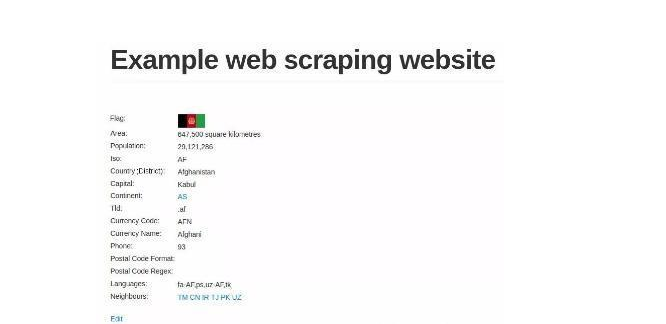
从上图可以看出,网页照样可以加载成功,也就是说这个别例是有效的。此刻我们便可以疏忽页面别号,只应用数据库ID来下载一切国度(或地区)的页面了。
来看看应用了该身手的代码片段
我们此刻可以应用该函数传入根基URL
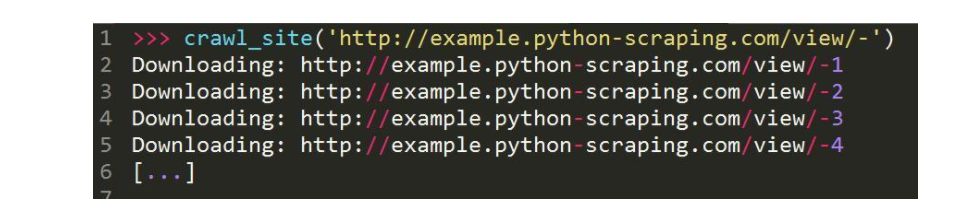
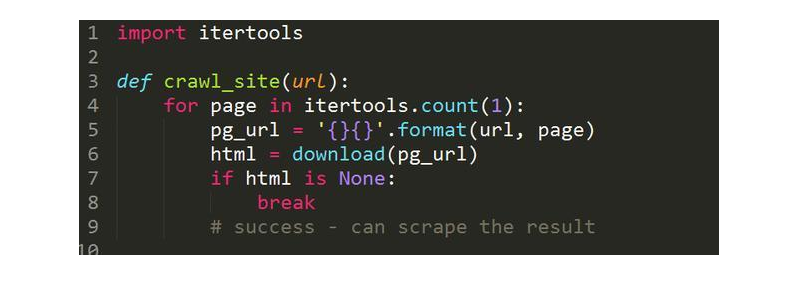
在这段代码中对ID遏制遍历,直到呈现下载缺点再中断,假定抓取已达到最后一个国度的页面。
但这类完成编制是出缺点的,那就是某些记录可以或许已被删除,数据库ID之间其实不是继续的。这个时辰只需拜候到某个距离点,爬虫就会立时参与。以下是这段代码的改进版本,在这个版本中继续产生多次下载缺点后才会参与法度典型。
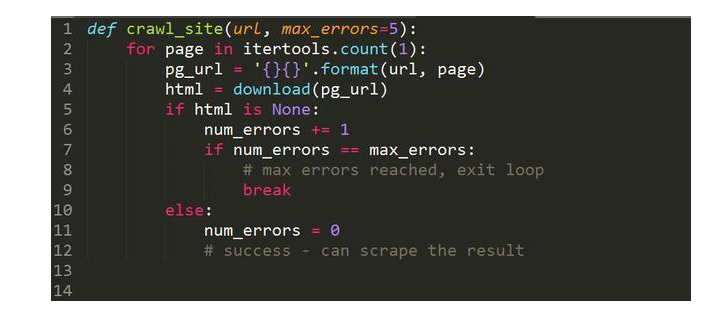
以上代码中完成的爬虫得继续5次下载缺点才会中断遍历,多么就极大年夜大年夜地降落了碰着记录被删除或埋没时过早中断遍历的风险。

7、链接爬虫
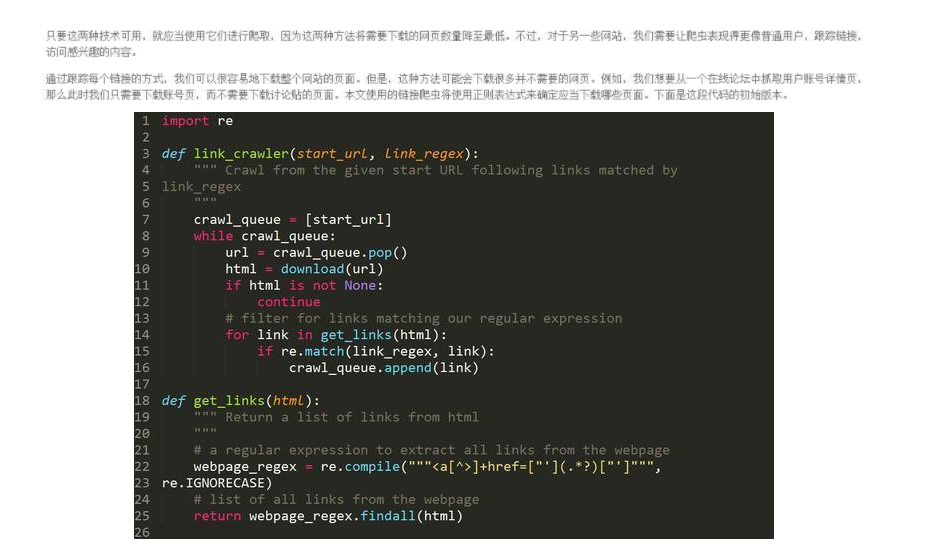
要运转这段代码,只需要调用link_crawler函数,并传入两个参数。
要爬取的网站URL
用于婚配你想跟踪的链接的正则表达式
关于示例网站来讲,我们想要爬取的是国度(或地区)列表索引页和国度(或地区)页面。
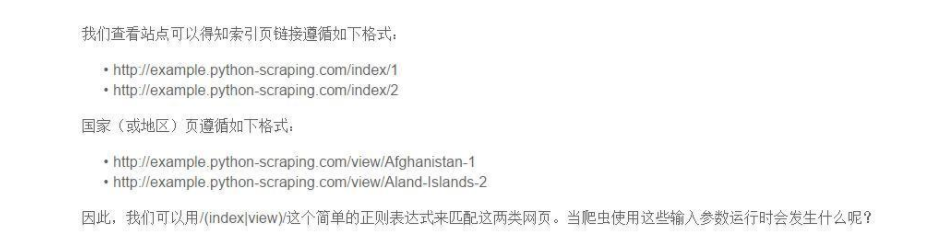
你会获得以下所示的下载缺点:
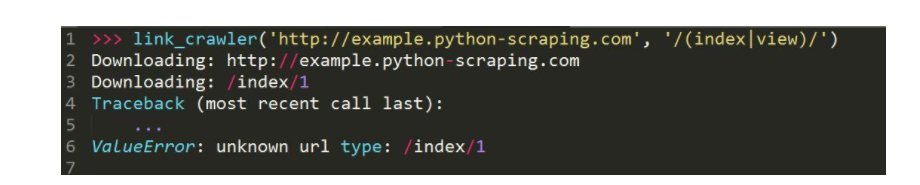
可以看出,结果出不才载/index/1时,链接只要网页的路子局部没有和谈和处事器局部,这是一个相对链接。
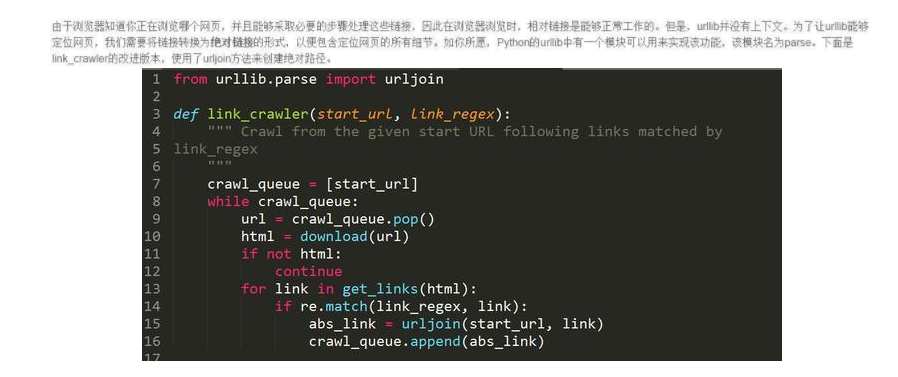
我们在运转这段代码时,当然下载了婚配的网页,然则异常的地址会被赓续反复下载到。
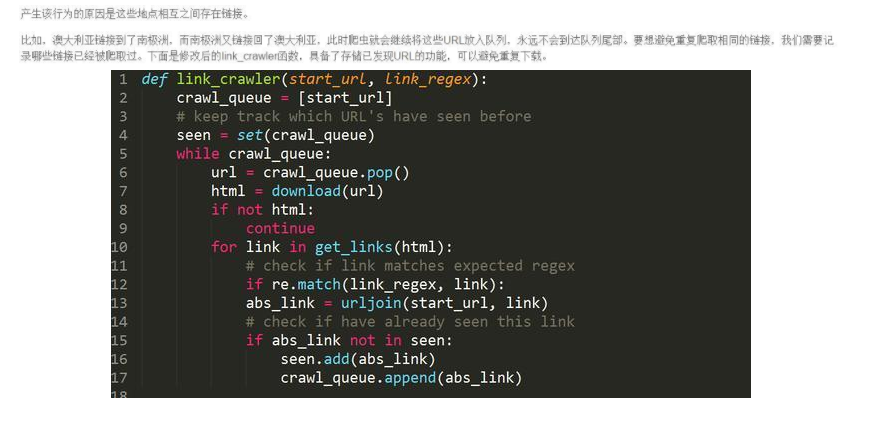
我们运转这个脚本的时辰它会爬取一切地址,并且可以或许如期中断。终究获得了一个可用的链接爬虫。