版权声明:author:Old Monster ,qq:767267711 ,email:[email protected] https://blog.csdn.net/qq_42259469/article/details/84971995
step 1:在cmd中切换到你想把项目创建的磁盘.我是要创建到d盘中.

step 2:创建项目,在cmd中输入:scrapy startproject csdn
scrapy startproject 项目名称

step 3:cd命令切换到你创建的项目下,然后创建爬虫项目文件:scrapy genspider -t crawl shua csdn.net
cd csdn
scrapy genspider -t crawl 项目名称 博客域名

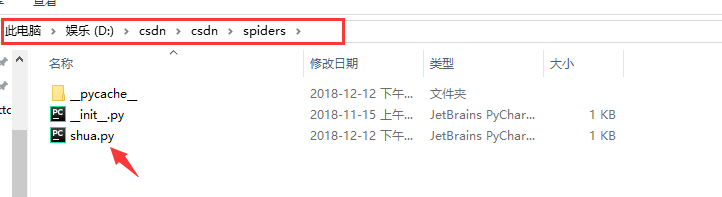
step 4:找到你创建的爬虫项目文件
在你最开始选择的盘下(我的是D盘)
然后找到你的项目(我创建的名称是csdn)
接着找到你项目里的spiders下的爬虫文件(我的爬虫项目名称取的是shua)
step 5:右键你的爬虫项目文本编辑
class ShuaSpider(CrawlSpider):
name = 'shua'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/qq_42259469'] #博客主页地址
rules = (
Rule(LinkExtractor(allow=r'https://blog.csdn.net/qq_42259469/article/details/\d+'), follow=False),
#博客地址,结尾的数字改成正则表达式\d+
#/article 前面这一段就是你的博客主页
)
step 6:创建一个bat后缀的文件并右键编辑打开输入以下代码:

d:
cd csdn
set a=0
:loop
set /a a+=1
echo. %a%
scrapy crawl shua
if %a% == 10000 goto end
goto loop

end :双击csdn.bat 文件就可以刷取访问量了.(温馨提示:仅供娱乐,过多访问会封ip哦~~)