1,将全部数据分离成训练集和测试集(之前首先先将x和y分类出来才可以)
'''
分离数据集--
test_size :如果是整数则选出来两个测试集,如果是小数,则是选择测试集所占的百分比。
train_size :同理,都含有默认值0.25
shuffle :默认为True,表示 在分离之前是否将其打乱,如果不打乱就设为False
random_state:是随机数的种子。(感觉没什么用,因此每次都填1吧)
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
'''
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=4, random_state=42)
结果:
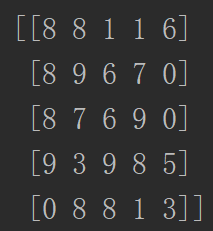
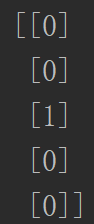
分离成train
[[8 8 1 1 6]] [[0]]
test
[[8 9 6 7 0]
[8 7 6 9 0]
[9 3 9 8 5]
[0 8 8 1 3]]
[[0]
[1]
[0]
[0]]
2,将训练集分离做交叉验证
就是将索引分离
from sklearn.cross_validation import KFold
kf = KFold(9, n_folds=3, random_state=2)
for train, test in kf:
print(train)
print(test)
'''
9:代表测试集的例子的个数
[3 4 5 6 7 8]
[0 1 2]
-----------------------
[0 1 2 6 7 8]
[3 4 5]
-----------------------
[0 1 2 3 4 5]
[6 7 8]
'''for train, test in kf:
# The predictors we're using the train the algorithm. Note how we only take the rows in the train folds.
train_predictors = (titanic[predictors].iloc[train,:])
# The target we're using to train the algorithm.
train_target = titanic["Survived"].iloc[train]
# Training the algorithm using the predictors and target.
alg.fit(train_predictors, train_target)
# We can now make predictions on the test fold
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)