1 简介
自然场景下的属性识别,如人脸识别、目标识别,已经取得了良好的识别效果。但是,监控场景下图像分辨率小、模糊,包含大的姿势和光线变化,识别效果并不理想。
作者提出使用CNN模型进行行人属性识别。
核心点:
- 使用卷积神经网络(CNN)进行特征提取;
- 设计DeepSAR网络进行单个属性的识别;
- 设计DeepMAR网络多属性的联合识别,如长头发的行人性别更可能是女;
- 设计了加权sigmoid交叉熵损失解决属性标签的不均衡。
2 核心思想

2.1 符号表示
N幅图像,表示成
;
每幅图像L个属性;
图像
的标签向量是
,可以表示成
,
。如果
,则表示第
幅图像具有第
个属性。
2.2 DeepSAR
网络结构如Fig2(a)所示,其中卷积网络如Fig2©所示。
输入为图像,输出为二分类任务,表示输入图像具有某个属性的概率。
使用softmax loss。
输入图像的第
个属性的损失为:
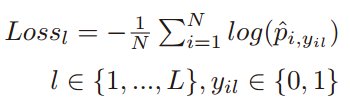
第
个属性的softmax输出概率为:
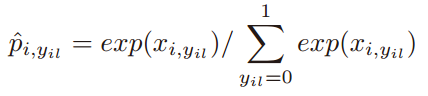
2.3 DeepMAR
网络结构如Fig2(b)所示,其中卷积网络如Fig2©所示。
多个属性联合训练,利用属性之间的关联关系。
输入为图像,输出为属性向量。
损失函数使用sigmoid交叉熵损失。

是样本
具有第
个属性的概率。
,表示样本
是否具有第
个属性。
由于在监控视频中,往往存在极端的属性分布不一致的情况。比如,有大量的样本具有“is male”的标签,但是只有很少样本具有“has no hair”的标签。因此,作者对上面的损失函数进行了改进,改进后的损失函数为:
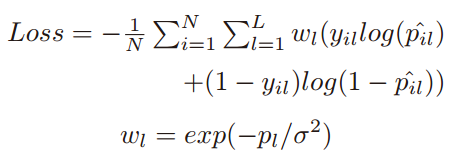
就是对每一个属性的损失添加了一个权重系数
,
为训练样本集中第
个属性为正的样本所占的比例。
为超参数,在论文的实验中设置为1。
3 实验
3.1 PETA数据集
监控视频中,19000个行人的图像;每个行人标注了61个二值的和4个多类别的属性。PETA的图像包含了大的背景、光线和视角的变化。
PETA的验证标准是计算每一个属性的平均识别准确率。
应用PETA时一般将数据集分为三部分,9500个行人目标用于训练,1900个用于验证,7600个用于测试。
3.2 实验详情
DeepSAR模型是用caffenet微调来的,只调整了最后一个全连接层的参数。
对样本进行随机的复制以保证正负训练样本集的均衡。图像先缩放到256256,然后再镜像和随机裁剪成227227。
DeepMAR也是在caffenet的基础上微调得到的。所有的层全部进行了调整。初始学习率0.001,权重衰减0.005。


对比算法MRFr2是基于手动设计的特征进行行人属性识别。
对于训练样本集中出现几率较小的属性,DeepSAR提升较大,这主要是由于CNN自动学习特征。DeepMAR平均识别准确率最高。