当需要对两个集合进行相互操作的时候,一般需要进行双层For循环,但我们知道双层For在数量越大的时候性能影响越大
这时候我们会想到的其中一种解决方法就是利用Hashmap在查找数据的高效上来优化双层For
我利用下面的代码来模拟测试两种情况的性能:
public static void main(String[] args) { for (int i = 0; i < 10000; i += 10) { List<String> loopList1 = getLoopList(i); List<String> loopList2 = getLoopList(i); long loopBy2forTimes = doBy2ForLoop(loopList1, loopList2); long loopByHashMapForTimes = doByHashmapForLoop(loopList1, loopList2); System.out.println("size:" + i + ": " + loopBy2forTimes + "," + loopByHashMapForTimes); } for (int i = 10000; i < 100000; i += 10000) { List<String> loopList1 = getLoopList(i); List<String> loopList2 = getLoopList(i); long loopBy2forTimes = doBy2ForLoop(loopList1, loopList2); long loopByHashMapForTimes = doByHashmapForLoop(loopList1, loopList2); System.out.println("size:" + i + ": " + loopBy2forTimes + "," + loopByHashMapForTimes); } } private static List<String> getLoopList(int size) { List<String> list = new ArrayList<>(); for (int i = 0; i < size; i++) { list.add(String.valueOf(i)); } return list; } private static long doBy2ForLoop(List<String> loopList1, List<String> loopList2) { long startTime = System.currentTimeMillis(); for (String str1 : loopList1) { for (String str2 : loopList2) { if (str1.equals(str2)) { continue; } } } long endTime = System.currentTimeMillis(); return endTime - startTime; } private static long doByHashmapForLoop(List<String> loopList1, List<String> loopList2) { long startTime = System.currentTimeMillis(); Map<String, String> loopListMap = loopList2.stream().collect(Collectors.toMap(k -> k, Function.identity())); for (String str1 : loopList1) { String str2 = loopListMap.get(str1); } long endTime = System.currentTimeMillis(); return endTime - startTime; }
结果: 第一个表格为1~10000, 第二个表格为10000~100000,
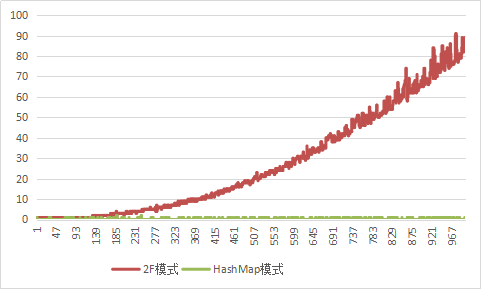

可以看到双层For数据量越大,执行时间越长,而使用了Hashmap,纵使数据量增长到了10w,执行时间也几乎为0(3-4ms)
嘛当然我们也可以算出上述代码的双层For的时间复杂度为O((1+N)/2),而使用Hashmap的时间复杂度为O(1),也可以发现List转Map几乎不耗时间
但是也要注意到,在数据量低(<2000)的情况下,两者没有区别,而hashmap还需要占用多余的空间
结论:选择哪个来遍历还是需要看具体的场景的数据量(但是数据量不清又嫌麻烦的咱大部分情况还是会用hashmap大法了233)