数据结构课设(一)
作业要求
1、设计并实现一个使用哈夫曼算法对文件进行压缩的工具软件。
2、通过命令行参数指定操作模式(压缩/解压)、源文件名、目标文件名。
3、压缩操作将源文件按字节读入并统计字节频率,生成字节的哈夫曼编码,将编码树和用哈夫曼编码对字节重新编码后的结果保存到目标文件中。
4、解压操作将源文件中的编码树读出,用编码树对后续编码部分进行解码操作,将解码结果保存到目标文件中。
主要问题
基于哈夫曼算法的文件压缩要考虑的几个主要问题:
1、命令行参数的设计与识别。带参数的main函数应该怎么用;设计合适的命令行参数来表示要执行的操作、源文件名和目标文件名。
2、文件操作。C/C++的文件流库是不一样的,选择你喜欢的文件流库,学习怎么以正确的方式打开文件、逐字节读取文件、写入文件。
3、设计压缩文件的格式。压缩文件头部应该是存储生成的哈夫曼树,后续才是源文件的压缩(编码)结果。这里的关键是文件头的设计。
4、统计字节频率,创建哈夫曼树,构造字节哈夫曼编码。
5、对源文件逐字节进行编码,并重新组合成字节。
6、解析压缩文件的文件头,还原哈夫曼树。
7、对压缩文件的编码部分进行解码。
决定按问题顺序来一个个解决。
1.命令行参数的设计与识别
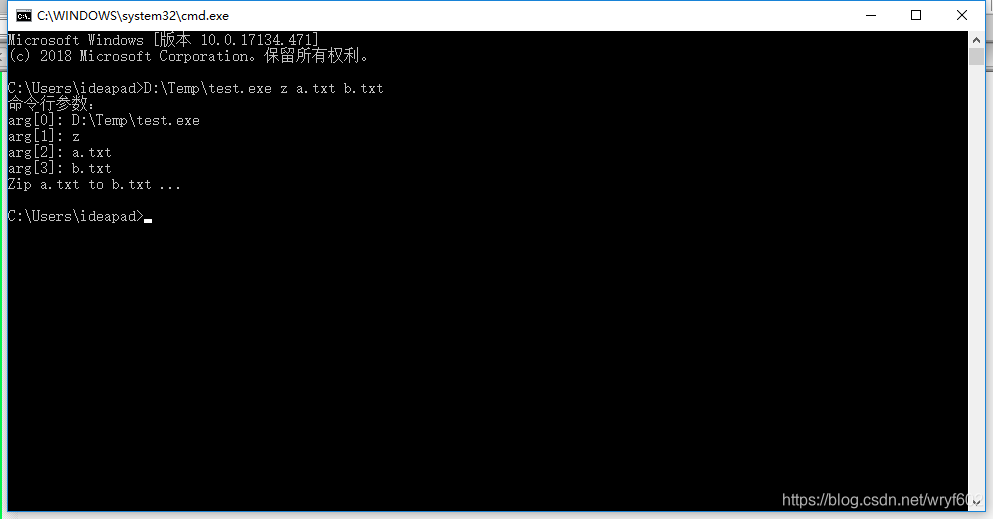
由于老师给出了demo代码,我就直接拿过来用了
int main(int argc, char *argv[])
{
cout << "命令行参数:" << endl;
for (int i = 0; i < argc; i++)
{
cout << "arg[" << i << "]: " << argv[i] << endl;
}
// 检查命令行参数,如果没有读到所需要的命令行参数,提示使用说明
if (argc != 4)
{
ShowHelp();
}
else if (stricmp(argv[1], "z") == 0)
{
cout << "Zip " << argv[2] << " to " << argv[3] << " ..." << endl;
Zip();
}
else if (stricmp(argv[1], "e") == 0)
{
cout << "Unzip " << argv[2] << " to " << argv[3] << " ..." << endl;
Unzip();
}
else
{
ShowHelp();
}
return 0;
}
演示
2.文件操作
这里用的是C++的iostream和fstream文件流库。用二进制的方式逐字节读取文件,可以读入文本图片或者音频等各种格式。
ifstream instr("in.txt", ios::in | ios::binary);//二进制方式
if (!instr)
{
cerr << "Open in.txt failure." << endl;
return 0;
}
ofstream outstr("out.txt", ios::out | ios::binary);
if (!outstr)
{
cerr << "Create out.txt failure." << endl;
instr.close();
return 0;
}
char ch;
while (instr.get(ch))
{
outstr.put(ch);
}
instr.close();
outstr.close();
return 0;
3.设计压缩文件的格式(重点)
这一步就是压缩文件的关键了,决定你压缩文件最后的大小,如果设计不合理的话压缩率和压缩速度就会极不理想(比如说我的就是),压缩完之后的压缩文件可能比原文件还要大。
首先压缩文件需要存你的哈夫曼树,然后就是你处理过的文件的哈夫曼编码。
文件压缩成编码这一步其实很简单,就是把原先的文件通过你构建的哈夫曼转成01序列的哈夫曼编码,然后把这些编码以二进制的形式存进压缩文件就行了。我是每8个字节转成一个unsigned char,然后存入文件。解压缩的时候再把这个还原成哈夫曼编码的形式就行了。
如果只需要存哈夫曼编码文件,不需要对应的哈夫曼树的话,那么大部分文件是可以压缩的更小的。但是,通常我们解压缩是只需要对压缩文件进行操作的,如果压缩文件里只存有哈夫曼编码的信息,那么我们是无法进行解码的。因此我们必须存进对应的哈夫曼树,这样才能解码还原成原文件。
不过直接将整棵树全部存进去会使你的压缩文件变得极其大,对于原本体积小的文件比如只有几十字节的txt文本来说,压缩完之后一下子就变成几百字节的东西了。由于我一开始没考虑到这令人窒息的情况,等我全部写完已经提不起兴致去改了,最后做出来的程序对比较大的文件才能起到一定的压缩效果。
string Str(string s)//将01二进制数转换成字符
{
map<int,int> change;
change[7]=1;
change[6]=2;
change[5]=4;
change[4]=8;
change[3]=16;
change[2]=32;
change[1]=64;
change[0]=128;
unsigned char c;
int n=0;
string t;
for(int i=0;i<s.size();i++)
{
if(i%8==0&&i!=0)
{
c=n;
t+=c;
n=0;
}
if(s[i]=='1')
n+=change[i%8];
}
c=n;
t+=c;
return t;
}
int Compresses(vector<Hfm> T,string s,char *file)
{
cout<<"Zipping..."<<endl;
ofstream out(file,ios::out|ios::binary);
int num=T.size();
out.write((char*)&num,sizeof(int));//树的大小
out.write((char*)&T[0],T.size()*sizeof(Hfm));//哈夫曼树
int num2=s.size();
out.write((char*)&num2,sizeof(int));//文件的大小
out<<Str(s);//哈夫曼编码
cout<<"Zipped!"<<endl;
out.close();
return 0;
}
在这里我存了树的大小,然后存了树,然后是文件的大小,然后是哈夫曼编码。(极不可取,不要借鉴)
4.统计字节频率,创建哈夫曼树,构造字节哈夫曼编码。
这一步没什么好说的,会哈夫曼树就行了。比起找了半天都找不到如何二进制存文件来说,这个在网上随便一搜就能找到。
用vector<Hfm> T存的哈夫曼树,用map<char,int>统计各个二进制字符出现的次数。
struct Hfm
{
char name;//字节名
int val;//权值,也就是出现的次数
int parent,lchild,rchild;
/*Hfm(char n,int v,int p,int l,int r)
{
name=n;;
val=v;
parent=p;
lchild=l;
rchild=r;
}
void Show()
{
cout<<val<<" "<<parent<<" "<<lchild<<" "<<rchild<<endl;
}*/
};
int CreatTree(map<char,int> arr,vector<Hfm> &T)
{
int len=arr.size();
map<char,int>::iterator iter;
for (iter = arr.begin(); iter != arr.end(); iter++) {
Hfm tt;
tt.name=iter->first;
tt.val=iter->second;
tt.parent=-1;
tt.lchild=-1;
tt.rchild=-1;
T.push_back(tt);
}
for(int i=0;i<len-1;i++)
{
int m,n;
Select(T,m,n);
Hfm tt;
tt.name=-1;
tt.val=T[m].val+T[n].val;
tt.parent=-1;
tt.lchild=m;
tt.rchild=n;
T.push_back(tt);
//T.push_back(Hfm(-1,T[m].val+T[n].val,-1,m,n));
T[m].parent=T.size()-1;
T[n].parent=T.size()-1;
}
return 0;
}
5.对源文件逐字节进行编码,并重新组合成字节。
int Hfmcode(vector<Hfm> T,map<char,string> &Code)
{
for(int i=0;i<T.size();i++)
{
string s;
stack<char> c;
if(T[i].lchild==-1&&T[i].rchild==-1)
{
int j=i;
while(T[j].parent>=0){
int temp=j;
j=T[j].parent;
if(T[j].lchild==temp)
{
c.push('0');
}
else c.push('1');
}
}
else break;
while(!c.empty())
{
s=s+c.top();
c.pop();
}
Code[T[i].name]=s;
}
return 0;
}
int main()
{
vector<Hfm> T;
map<char,string> Code;
CreatTree(arr,T);
Hfmcode(T,Code);
string Zip;//哈夫曼编码
for(int i=0;i<s.size();i++)
{
Zip+=Code[s[i]];
}
}
6.解压缩
老师给的6、7步我就一块说了,我的压缩效果太差,不好意思写了。
string Bin(string t,int n)//将0-256的数转换成8位二进制
{
map<int,int> change;
change[7]=1;
change[6]=2;
change[5]=4;
change[4]=8;
change[3]=16;
change[2]=32;
change[1]=64;
change[0]=128;
string s;
for(int j=0;j<t.size();j++)
{
unsigned char c=t[j];
int a=c;
for(int i=0;i<8;i++)
{
if(a>=change[i])
{
a-=change[i];
s+='1';
}
else s+='0';
}
}
int sur=8-n%8;
while(sur--)
{
s.erase(s.end()-1);
}
return s;
}
int Uncode(vector<Hfm> T,string t,int sur,char *file)
{
ofstream Un(file,ios::out|ios::binary);
int r=T.size()-1;
int temp=r;
string s=Bin(t,sur);
for(int i=0;i<s.size();i++)
{
if(s[i]=='0')
{
temp=T[r].lchild;
if(T[temp].lchild==-1&&T[temp].rchild==-1)
{
Un.put(T[temp].name);
r=T.size()-1;
}
else r=temp;
}
else
{
temp=T[r].rchild;
if(T[temp].lchild==-1&&T[temp].rchild==-1)
{
Un.put(T[temp].name);
r=T.size()-1;
}
else r=temp;
}
}
Un.close();
return 0;
}
int Uncode2(char *file1,char *file2)
{
ifstream ss(file1,ios::in|ios::binary);
int f;
ss.read((char*)&f,sizeof(int));
vector<Hfm> T0(f);
ss.read((char*)&T0[0],T0.size()*sizeof(Hfm));
int f2;
ss.read((char*)&f2,sizeof(int));
char x;
string t;
while(ss.get(x))
{
t+=x;
}
ss.close();
Uncode(T0,t,f2,file2);
cout<<"Unzipped!"<<endl;
return 0;
}
结束
这个算法写的不太好,不过也不想回头去改了,还有两个课设没写,而且期末考试还没复习。
大概总结一下,其实这个算法算是比较简单的,难点主要在如何进行二进制文件的操作,这些格式转换的乱七八糟的,网上找又不好找,没有统一的方法,只有自己慢慢摸索。经过这几天的学习,好歹熟悉了fstream/ifstream/ofstream这几个文件流的使用。
源码
以后源码都上传到我的GitHub上。(假装自己写了很多东西的样子)