此篇文章请花半小时阅读!

本章知识点:
a.scrapy-redis简介
b.开始项目前的准备
一、Scrapy-Redis 简介
scrapy-redis是一个基于redis数据库的scrapy组件,它提供了四种组件,通过它,可以快速实现简单分布式爬虫程序。
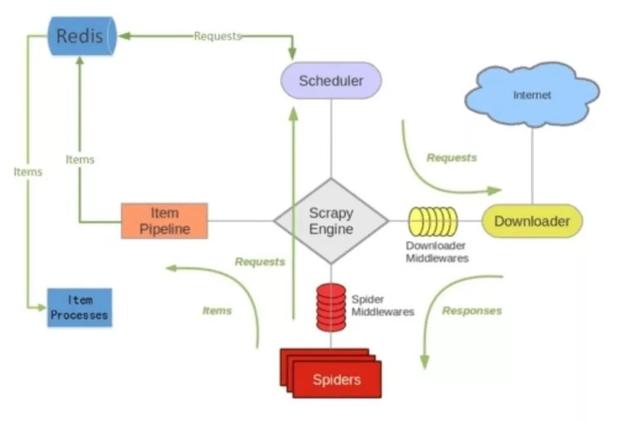

项目地址:
https://github.com/rmax/scrapy-redis
二、Scrapy-Redis 工作机制
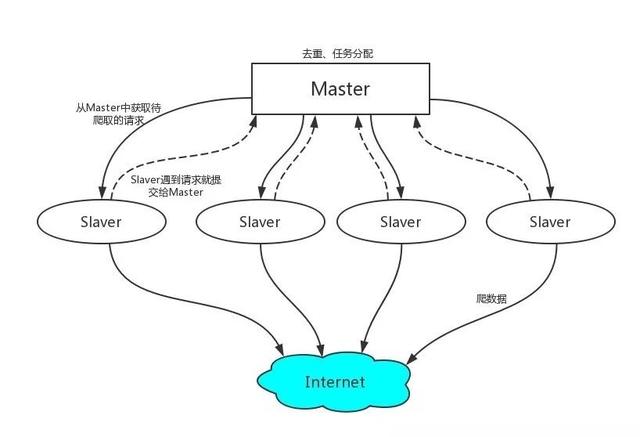
1、首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2、Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
三、开始项目前的准备
1、Redis配置安装:
工欲善其事必先利其器,既然是基于redis的服务,当然首先要安装redis了。
安装Redis服务器端
sudo apt-get install redis-server
修改配置文件 redis.conf
sudo nano /etc/redis/redis.conf
将bind 127.0.0.1注释掉。这样Slave端才能远程连接到Master端的Redis数据库。
将Ubuntu作为Master端,Windows10和Windows7作为Slaver端,在Master中开启redis-service服务。Slaver端也需要有redis。
redis-server
Slaver连接测试:
redis-cli -h MasterIP地址

至此,redis已经安装完成。
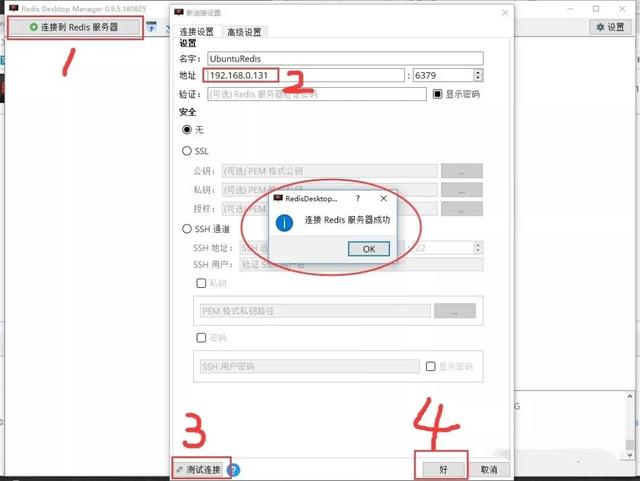
Redis可视化管理工具-Redis Desktop Manager
私信菜鸟007获取完整资料教程!
下载地址:
https://redisdesktop.com/download
配置方法:
2、获取自己的ip代理池
很多网站都有反爬虫机制,只用一个ip去频繁访问网站的话,很容易引起网站管理员的注意,如果管理员将这个ip加入黑名单,那么这个爬虫就废掉了。所以,想要做大型的爬虫的话,基本上是必须要面对ip的问题。
那么问题来了,我们去哪里搞代理ip呢??第一种方法就是买买买!!没有什么事情是用钱解决不了的,如果有,那就加倍。
当然,网上也有一堆免费的ip代理,但是,免费的质量参差不齐,所以就需要进行筛选。以西刺代理为例:用爬虫爬取国内的高匿代理IP,并进行验证。(只爬取前五页,后面的失效太多,没有必要去验证了。)
爬虫:
class XiciSpider(scrapy.Spider):
name = 'xici'
allowed_domains = ['xicidaili.com']
start_urls = []
for i in range(1, 6):
start_urls.append('http://www.xicidaili.com/nn/' + str(i))
def parse(self, response):
ip = response.xpath('//tr[@class]/td[2]/text()').extract()
port = response.xpath('//tr[@class]/td[3]/text()').extract()
agreement_type = response.xpath('//tr[@class]/td[6]/text()').extract()
proxies = zip(ip, port, agreement_type)
# print(proxies)
# 验证代理是否可用
for ip, port, agreement_type in proxies:
proxy = {'http': agreement_type.lower() + '://' + ip + ':' + port,
'https': agreement_type.lower() + '://' + ip + ':' + port}
try:
# 设置代理链接 如果状态码为200 则表示该代理可以使用
print(proxy)
resp = requests.get('http://icanhazip.com', proxies=proxy, timeout=2)
print(resp.status_code)
if resp.status_code == 200:
print(resp.text)
# print('success %s' % ip)
item = DailiItem()
item['proxy'] = proxy
yield item
except:
print('fail %s' % ip)
Pipeline:
class DailiPipeline(object):
def __init__(self):
self.file = open('proxy.txt', 'w')
def process_item(self, item, spider):
self.file.write(str(item['proxy']) + '
')
return item
def close_spider(self, spider):
self.file.close()
运行结果:

爬了500条数据,只有四条可以用………
1、定义爬取字段
import scrapy class DyttRedisSlaverItem(scrapy.Item): # 译名 name = scrapy.Field() # 年代 year = scrapy.Field() # 语言 language = scrapy.Field() # 上映日期 release_date = scrapy.Field() # 评分 score = scrapy.Field() # 文件大小 file_size = scrapy.Field() # 片长 film_time = scrapy.Field() # 简介 introduction = scrapy.Field() # 海报 posters = scrapy.Field() # 下载链接 download_link = scrapy.Field()
2、定义Rule规则
查看网页源码发现,电影链接为/i/[一串数字].html的形式,但是我们只需要类目中的电影而不需要推荐的电影:
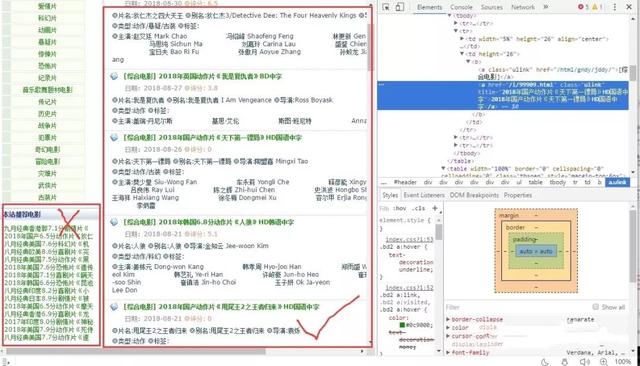
所以:
movie_links = LinkExtractor(allow=r'/i/d*.html', restrict_xpaths=('//div[@class="co_content8"]'))
rules = (
Rule(movie_links, callback='parse_item'),
)
3、定义提取影片信息规则
观察网页源码,发现页面结构并不是统一的:
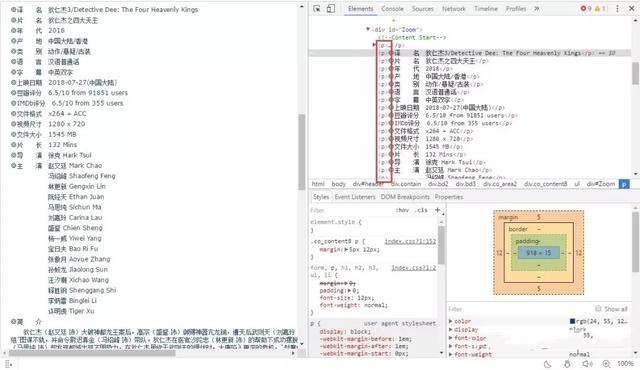
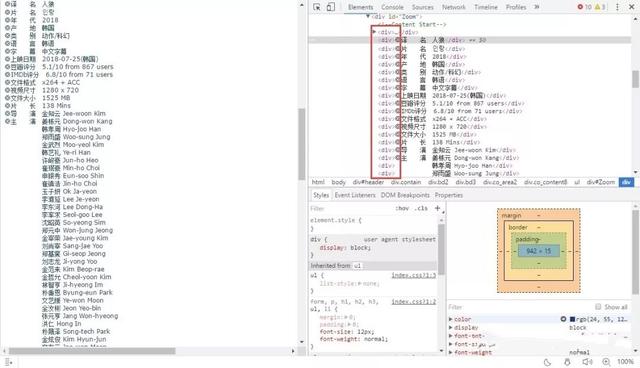
有的信息在p标签中包裹,但是也有一些信息在div标签中。而且,由于主演人数不同,标签个数也不确定。所以,用xpath进行提取不是那么的方便了。这种情况就需要选用正则表达式来进行筛选。
观察网页编码,为gb2312
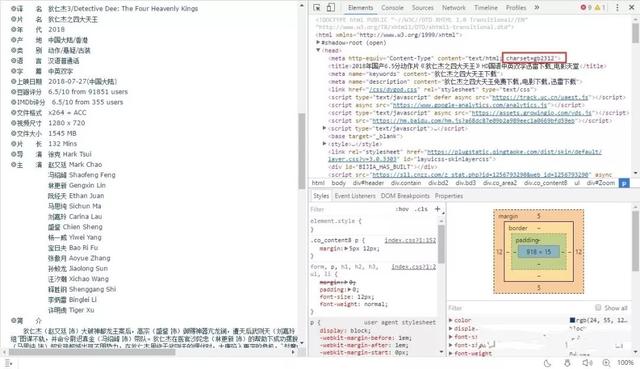
有些小众的电影并没有评分。
所以,筛选规则为:
str_resp = response.body.decode('gb2312', errors='ignore')
rep_chars = [' ', '·', '“', '”', '…']
for rep in rep_chars:
str_resp = str_resp.replace(rep, '')
title = re.search(r'◎片 名(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
translation = re.search(r'◎译 名(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 名字
items['name'] = title + "|" + translation
# 年代
items['year'] = re.search(r'◎年 代(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 评分
try:
items['score'] = response.xpath("//strong[@class='rank']/text()").extract()[0].replace(u'\u3000', '')
except:
items['score'] = '无评分'
# 语言
items['language'] = re.search(r'◎语 言(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 上映日期
items['release_date'] = re.search(r'◎上映日期(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 文件大小
items['file_size'] = re.search(r'◎文件大小(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 片长
items['film_time'] = re.search(r'◎片 长(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 简介
items['introduction'] = re.search(r'◎简 介</.+>
<.+>(.*?)</.+>', str_resp).group(1).replace(u'\u3000', '')
# 海报
items['posters'] = response.xpath("//div[@id='Zoom']/*[1]/img/@src").extract()[0]
经测试发现,网站的迅雷下载链接是用js动态生成的。这就要用到selenium了。
from selenium import webdriver
# 下载链接
items['download_link'] = self.get_download_link(response.url)
def get_download_link(self, url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get(url)
link = re.search(r'"(thunder:.*?)"', driver.page_source).group(1)
driver.close()
return link
最后,pipelines中保存数据:
class DyttRedisSlaverPipeline(object):
def __init__(self):
self.file = open('movie.json', 'w')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "
"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
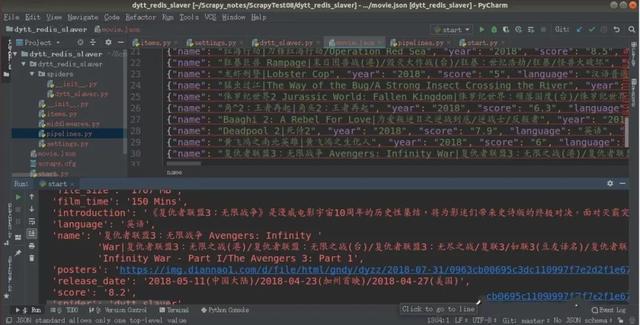
运行爬虫,得到第一页的30条数据:
二、修改项目为RedisCrawlSpider爬虫
1、首先修改爬虫文件
① RedisCrawlSpider修改很简单,首先需要引入RedisCrawlSpider:
from scrapy_redis.spiders import RedisCrawlSpider
② 将父类中继承的CrawlSpider改为继承RedisCrawlSpider:
class DyttSlaverSpider(RedisCrawlSpider):
③ 因为slaver端要从redis数据库中获取爬取的链接信息,所以去掉allowed_domains() 和 start_urls,并添加redis_key
redis_key = 'dytt:start_urls'
④ 增加__init__()方法,动态获取allowed_domains(),[理论上要加这个,但是实测加了爬取的时候链接都被过滤了,所以我没加,暂时没发现有什么影响]
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(DyttSlaverSpider, self).__init__(*args, **kwargs)
2、修改setting文件
① 首先要指定redis数据库的连接参数:
REDIS_HOST = '192.168.0.131' REDIS_PORT = 6379
② 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
③ 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
④ 指定排序爬取地址时使用的队列
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue' # 可选的 按先进先出排序(FIFO) # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue' # 可选的 按后进先出排序(LIFO) # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'
⑤ 设置断点续传,也就是不清理redis queues
SCHEDULER_PERSIST = True
⑥ 默认情况下,RFPDupeFilter只记录第一个重复请求。将DUPEFILTER_DEBUG设置为True会记录所有重复的请求。
DUPEFILTER_DEBUG =True
⑦ 配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item
ITEM_PIPELINES = {
'dytt_redis_slaver.pipelines.DyttRedisSlaverPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
3、增加爬虫信息字段(可选)
由于会有多个slaver端,所以可加一个爬虫名字的字段和时间字段来区分是哪个爬虫在什么时间爬到的信息。
① item中增加字段
# utc时间 crawled = scrapy.Field() # 爬虫名 spider = scrapy.Field()
② pipelines中新增类:
class InfoPipeline(object): def process_item(self, item, spider): #utcnow() 是获取UTC时间 item["crawled"] = datetime.utcnow() # 爬虫名 item["spider"] = spider.name return item
③ setting中设置ITEM_PIPELINES
ITEM_PIPELINES = {
'dytt_redis_slaver.pipelines.DyttRedisSlaverPipeline': 300,
'dytt_redis_slaver.pipelines.InfoPipeline':350,
'scrapy_redis.pipelines.RedisPipeline': 400
}
至此,项目修改完毕,现在可以爬取某一分类下的第一页的电影信息。
以Windows10为slaver端运行一下:
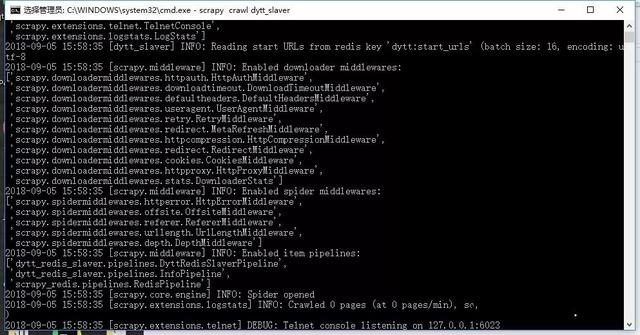
因为请求队列为空,所以爬虫会停下来进行监听,直到我们在Master端给它一个新的连接:

爬虫启动,开始爬取信息:
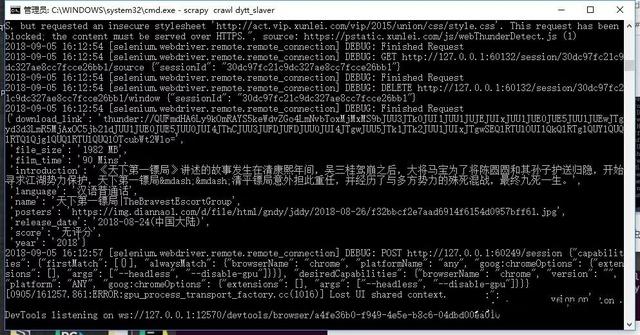
爬取完成后,项目不会结束,而是继续等待新的爬取请求的到来,爬取结果:

本章小结:
本章将一个crawlspider爬虫改为了RedisCrawlSpider爬虫,可以实现分布式爬虫,但是由于数据量较小(只有30条)所以只用了一个slaver端。并且没有去设置代理ip和user-agent,下一章中,针对上述问题,将对项目进行更深一步的修改。
一、使用代理ip
在 中,介绍了ip代理池的获取方式,那么获取到这些ip代理后如何使用呢?
首先,在setting.py文件中创建USER_AGENTS和PROXIES两个列表:
USER_AGENTS = [
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36'
]
PROXIES = [
{'ip_port': '118.190.95.43:9001', "user_passwd": None},
{'ip_port': '61.135.217.7:80', "user_passwd": None},
{'ip_port': '118.190.95.35:9001', "user_passwd": None},
]
我们知道,下载中间件是介于Scrapy的request/response处理的钩子,每个请求都需要经过中间件。所以在middlewares.py中新建两个类,用于随机选择用户代理和ip代理:
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
#print useragent
request.headers.setdefault("User-Agent", useragent)
# 随机的代理ip
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
# 没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
在setting.py中开启下载中间件:
DOWNLOADER_MIDDLEWARES = {
'dytt_redis_slaver.middlewares.RandomUserAgent': 543,
'dytt_redis_slaver.middlewares.RandomProxy': 553,
}
二、Master端代码
Scrapy-Redis分布式策略中,Master端(核心服务器),不负责爬取数据,只负责url指纹判重、Request的分配,以及数据的存储,但是一开始要在Master端中lpush开始位置的url,这个操作可以在控制台中进行,打开控制台输入:
redis-cli 127.0.0.1:6379> lpush dytt:start_urls https://www.dy2018.com/0/
也可以写一个爬虫对url进行爬取,然后动态的lpush到redis数据库中,这种方法对于url数量多且有规律的时候很有用(不需要在控制台中一条一条去lpush,当然最省事的方法是在slaver端代码中增加rule规则去实现url的获取)。比如要想获取所有电影的分类。
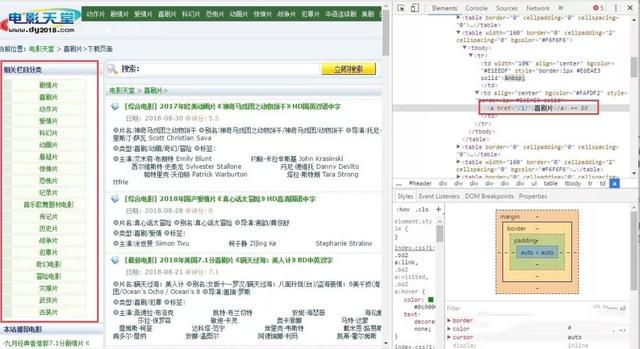
链接就是一个或者两个数字,所以rule规则为:
rules = (
Rule(LinkExtractor(allow=r'/d{1,2}/$'), callback='parse_item'),
)
在parse_item中返回这个请求链接:
def parse_item(self, response): # print(response.url) items = DyttRedisMasterItem() items['url'] = response.url yield items
piplines.py中,将获得的url全部lpush到redis数据库:
import redis
class DyttRedisMasterPipeline(object):
def __init__(self):
# 初始化连接数据的变量
self.REDIS_HOST = '127.0.0.1'
self.REDIS_PORT = 6379
# 链接redis
self.r = redis.Redis(host=self.REDIS_HOST, port=self.REDIS_PORT)
def process_item(self, item, spider):
# 向redis中插入需要爬取的链接地址
self.r.lpush('dytt:start_urls', item['url'])
return item
运行slaver端时,程序会等待请求的到来,当starts_urls有值的时候,爬虫将开始爬取,但是一开始并没有数据,因为会过滤掉重复的链接:

毕竟有些电影的类型不止一种:

scrapy默认16个线程(当然可以修改为20个啊),而分类有20个,所以start_urls会随机剩下4个,等待任务分配:

当链接过滤完毕后,就有数据了:
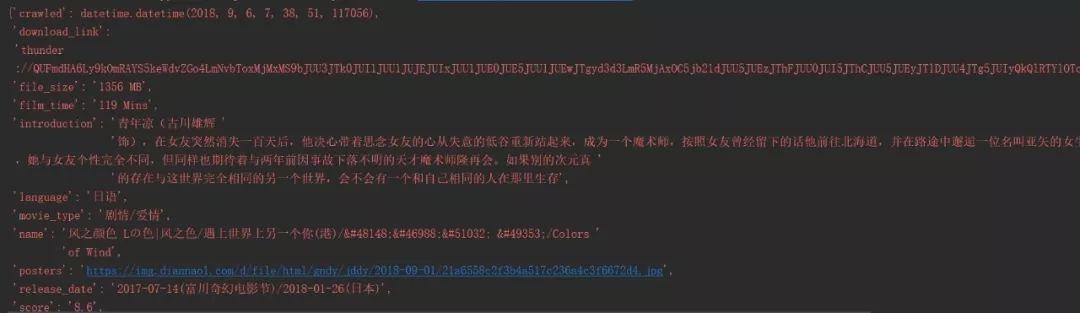
因为在setting.py中设置了:
SCHEDULER_PERSIST = True
所以重新启动爬虫的时候,会接着之前未完成的任务进行爬取。在slaver端中新增rule规则可以实现翻页功能:
page_links = LinkExtractor(allow=r'/index_d*.html') rules = ( # 翻页规则 Rule(page_links), # 进入电影详情页 Rule(movie_links, callback='parse_item'), )
三、数据转存到Mysql
因为,redis只支持String,hashmap,set,sortedset等基本数据类型,但是不支持联合查询,所以它适合做缓存。将数据转存到mysql数据库中,方便以后查询:

创建数据表:
代码如下:
# -*- coding: utf-8 -*-
import json
import redis
import pymysql
def main():
# 指定redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定mysql数据库
mysqlcli = pymysql.connect(host='127.0.0.1', user='root', passwd='zhiqi', db='Scrapy', port=3306, use_unicode=True)
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["dytt_slaver:items"])
item = json.loads(data)
try:
# 使用cursor()方法获取操作游标
cur = mysqlcli.cursor()
# 使用execute方法执行SQL INSERT语句
cur.execute("INSERT INTO dytt (name, year, language, "
"movie_type, release_date, score, file_size, "
"film_time, introduction, posters, download_link) VALUES "
"(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s )",
[item['name'], item['year'], item['language'],
item['movie_type'], item['release_date'], item['score'],
item['file_size'], item['film_time'], item['introduction'],
item['posters'], item['download_link']])
# 提交sql事务
mysqlcli.commit()
#关闭本次操作
cur.close()
print ("inserted %s" % item['name'])
except pymysql.Error as e:
print ("Mysql Error %d: %s" % (e.args[0], e.args[1]))
if __name__ == '__main__':
main()
最终结果:
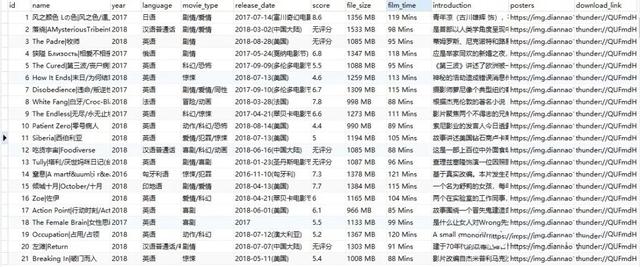
下次再见!