高维数组
如二维数组: int a[10][20]
数组名是数组的首地址,就是第一个元素的地址,是一个常量,常量是不能放在=左边的,数组和指针的区别在于,指针是变量,是用来存储指向数据的地址的变量,而数组名是常量。一般情况下申明一个数组,比如char a[10]; 之后 数组名a都是数组的首地址,是一个地址常量。但是在函数申明的形参列表中除外,比如:
int fo(char []);
在这种情况下的申明与
int fo(char a[]);
int fo(char *a);
是等价的,就是说在这种情况下,就算你写的是数组的形式,编译器实际处理的时候也是当做指针来处理的,(此时,指针是变量,形参也是变量,二者刚好对应。)所以在函数fo内部,我们队a ++ – += -= = 之类的带赋值的操作是完全合法的,因此a就是一个指针,不是数组名,当我们向fo里面传入我们一个已经事先申明的数组的首地址,指针a里面的值就是已经申明的数组进行操作。
指针数组
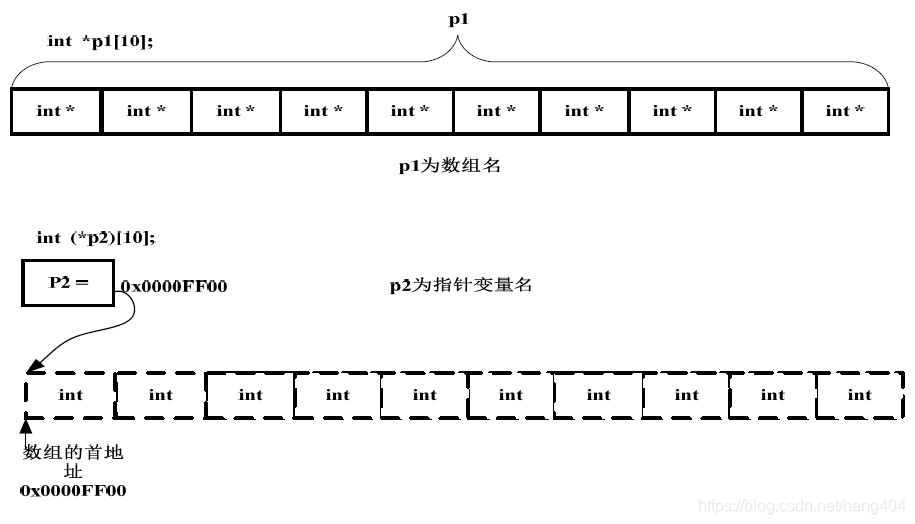
元素为指针的数组,如:int* p[n],p是一个数组,数组中元素为int*,且有n个元素。
数组指针(行指针)
指向数组的指针,如:int (*p)[n],p是一个指针,指向数组的指针,且数组中有n个int元素。由于[]的优先级比*高,所以需要加括号,不加括号就变成了指针数组。p+1要跨过n个元素。
int num[3]; //num的值与&num的值相同,但是两者类型不同,
//num 为指向第一个元素的指针,num+1表示下一个元素的地址,
//&num 为数组指针,int (*) [3], &num+1就会跳过这三个元素。
//num++ 或者num = num + 1;会报错。
//&(num + 1) 也会报错。
int a[3][4];
int (*p)[4];
p = a; // a自身为数组指针, int (*)[4],指向a[0]那一行;
// &a : 仍为数组指针,只不过是一个指向二维数组的指针, int (*) [3][4]。
// a + i : 数组指针, int (*) [4]。
// *(a + i):数组,int *。
// *(*(a + i) + j):数字 int ,a[i][j]。
// *(a + i) = a[i];
// *(*(a + i) + j) = *(a[i] + j) = a[i][j];
p = p + 1; // 此时p仍是一个数组指针,指向a[1]那一行。
int *p1[3]; //p1为指针数组,含有3个整形指针的数组。
for(i = 0; i < 3; i++)
p1[i] = a[i];
内存布局:
int main() {
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
上面对p3 和p4 的使用,哪个正确呢?p3+1 的值会是什么?p4+1 的值又会是什么?毫无疑问,p3 和p4 都是数组指针,指向的是整个数组。&a 是整个数组的首地址,a是数组首元素的首地址,其值相同但意义不同。在C 语言里,赋值符号“=”号两边的数据类型必须是相同的,如果不同需要显示或隐式的类型转换。p3 这个定义的“=”号两边的数据类型完全一致,而p4 这个定义的“=”号两边的数据类型就不一致了。左边的类型是指向整个数组的指针,右边的数据类型是指向单个字符的指针。在Visual C++6.0 上给出如下警告:
warning C4047: ‘initializing’ : ‘char (*)[5]’ differs in levels of indirection from ‘char *’。
还好,这里虽然给出了警告,但由于 &a 和a 的值一样,而变量作为右值时编译器只是取变量的值,所以运行并没有什么问题。不过我仍然警告你别这么用。
既然现在清楚了p3 和p4 都是指向整个数组的,那p3+1 和p4+1 的值就很好理解了。
甚至还可以把代码再修改,把数组大小改大点:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[10] = &a;
char (*p4)[10] = a;
return 0;
}
这个时候又会有什么样的问题?p3+1 和p4+1 的值又是多少?
上述几个问题,希望读者能仔细考虑考虑,并且上机测试看看结果。
测试结果:
(1).char (*p2)[5]=a;必须使用强制转换,如:char (p2)[5]=(char ()[5])a;
(2).把数组大小改变,都会编译不通过,提示:
error C2440: ‘initializing’ : cannot convert from ‘char ()[5]’ to 'char ()[3]’
error C2440: ‘initializing’ : cannot convert from ‘char ()[5]’ to 'char ()[10]’
地址的强制转换
先看下面这个例子:
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假设p 的值为0x100000。如下表表达式的值分别为多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
还记得前面表达式“a+1”与“&a+1”之间的区别吗?其实这里也一样。指针变量与一个整数相加减并不是用指针变量里的地址直接加减这个整数。这个整数的单位不是byte 而是元素的个数。所以:p + 0x1 的值为0x100000+sizof(Test)*0x1。至于此结构体的大小为20byte,前面的章节已经详细讲解过。所以p +0x1 的值为:0x100014。
(unsigned long)p + 0x1 的值呢?这里涉及到强制转换,将指针变量p 保存的值强制转换成无符号的长整型数。任何数值一旦被强制转换,其类型就改变了。所以这个表达式其实就是一个无符号的长整型数加上另一个整数。所以其值为:0x100001。
(unsigned int*)p + 0x1 的值呢?这里的p 被强制转换成一个指向无符号整型的指针。所以其值为:0x100000+sizof(unsigned int)*0x1,等于0x100004。
上面这个问题似乎还没啥技术含量,下面就来个有技术含量的:在x86 系统下,其值为多少?
int main()
{
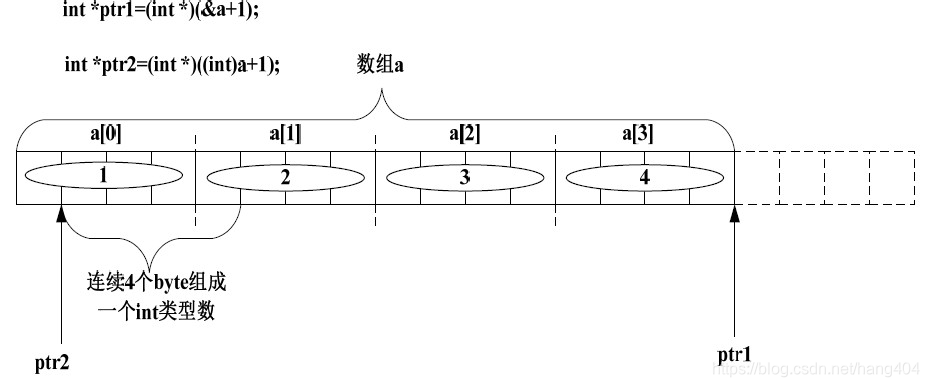
int a[4]={1,2,3,4};
int *ptr1=(int *)(&a+1);//指向a数组后面的内存单元,&a+1表示向后移16个存储单元
int *ptr2=(int *)((int)a+1);//表示a的存储单元的地址增加一个字节
printf("%x,%x",ptr1[-1],*ptr2);//ptr1[-1]其实指向的是a数组的最后一个单元,
//*ptr1则表示a数组的地址后移一个字节之后的4个连续存储单元所存储的值
return 0;
}
根据上面的讲解,&a+1 与a+1 的区别已经清楚。
ptr1:将&a+1 的值强制转换成int类型,赋值给int 类型的变量ptr,ptr1 肯定指到数组a 的下一个int 类型数据了。ptr1[-1]被解析成*(ptr1-1),即ptr1 往后退4 个byte。所以其值为0x4。
ptr2:按照上面的讲解,(int)a+1 的值是元素a[0]的第二个字节的地址。然后把这个地址强制转换成int类型的值赋给ptr2,也就是说ptr2 的值应该为元素a[0]的第二个字节开始的连续4 个byte 的内容。
其内存布局如下图:
好,问题就来了,这连续4 个byte 里到底存了什么东西呢?也就是说元素a[0],a[1]里面的值到底怎么存储的。这就涉及到系统的大小端模式了,如果懂汇编的话,这根本就不是问题。既然不知道当前系统是什么模式,那就得想办法测试。大小端模式与测试的方法在第一章讲解union 关键字时已经详细讨论过了,请翻到彼处参看,这里就不再详述。我们可以用下面这个函数来测试当前系统的模式。
int checkSystem()
{
union check
{
int i;
char ch;
} c;
c.i = 1;
return (c.ch == 1);//如果当前系统为大端模式这个函数返回0;如果为小端模式,函数返回1。
}
如果当前系统为大端模式这个函数返回0;如果为小端模式,函数返回1。也就是说如果此函数的返回值为1 的话,*ptr2 的值为0x2000000。如果此函数的返回值为0 的话,*ptr2 的值为0x100。
参考原文:https://blog.csdn.net/u013634862/article/details/26853789
参考原文:http://c.biancheng.net/cpp/html/476.html