经常会听到Unicode是用两个字节表示世界上所有语言的编码,那么问题来了两个字节不过65535个符号,怎么能表示所有语言?也经常搞不清楚Unicode和UTF-8到底有什么区别。也曾听说内存中都是Unicode统一表示,然后传输和存储的时候转换成UTF-8。总之网络时代就是这样——众说纷纭。这里,我仅把此刻认为正确的说法记录下来。
一. Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字所表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。所以到这里,我们可以明确的指出,Unicode是用两个字节表示字符这种说法是错误的。
误区:java使用Unicode编码,所以一个汉字用两个字节表示。
来解释一下,首先明确java使用Unicode编码的意思,所谓的java使用Unicode编码其实是一个比较复杂的事情,说来话真的很长。
比如说,我们在.java源文件中申请一个字符串 String str = "中文"; 那么当这个.java文件被运行起来的时候,str在内存中为了表示"中文"这两个汉字就会有一个对应的值,而这个对应的值使用的是Unicode编码规则对应的。
但是,我们上面指出了,Unicode编码里中文并不是两个字节,可能是更多字节来表示的,那么java是怎么做到只用两个字节来表示一个中文的?
其实,正确来讲,java使用Unicode编码,准确来说其实是使用UTF-16,一个中文字符绝大多数情况下都是两个字节。
这里就有必要说一下UTF
二.UTF
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了。为什么会出现?因为如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
再说UTF-16,即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。UTF-16 使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
误区:内存和传输、存储使用的是一种编码
搞清楚了Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
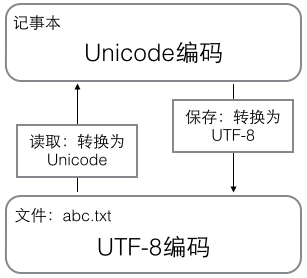
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
搞清楚UTF-8解决的问题和一种语言所使用的编码(内码)是什么意思,对上面的说法就很容易理解
首先UTF出现就是为了在网络上传输和存储中使用的,因此硬盘上或传输流上使用UTF-8没有问题。
那么为什么内存中要统一使用一种编码呢?其实也很简单:.java源码文件这个文件本身也是有编码的,不同.java源文件这个编码可以不同,当JVM去编译这个源文件的时候,根据这个编码去识别才能够正确编译出.class文件,并且把它们统一编码成UTF-16在JVM中运行才不会因为各个源文件编码不同而出错。
因此,同样的道理,浏览网页的时候,服务器也用这种思路统一以Unicode编码去运行程序,然后用UTF-8去传输。
最后在编写程序中的例子去理解
python3使用Unicode编码
str = ord('中') #ord获取字符整数表示 这个整数表示也就是Unicode编码去映射的 也就是'中'字在内存中真正表示的值
print(str)
#在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes
str = '中文'.encode('utf-8') #把Unicode字符串编码成utf-8的bytes
print(str)
#decode把utf-8编码的bytes解码成Unicode字符串
str = b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') #'中文'的utf-8编码的bytes
print(str)output:
20013
b'\xe4\xb8\xad\xe6\x96\x87'
中文