吃鸡的火热程度相信大家都有所了解,今天小编就来带大家制作“简单的外挂”,相信能够帮助大家大吉大利,今晚吃鸡!
1、小岛上人越多我活得更久?
对game_size变量进行生存分析发现还是小规模的比赛比较容易存活。
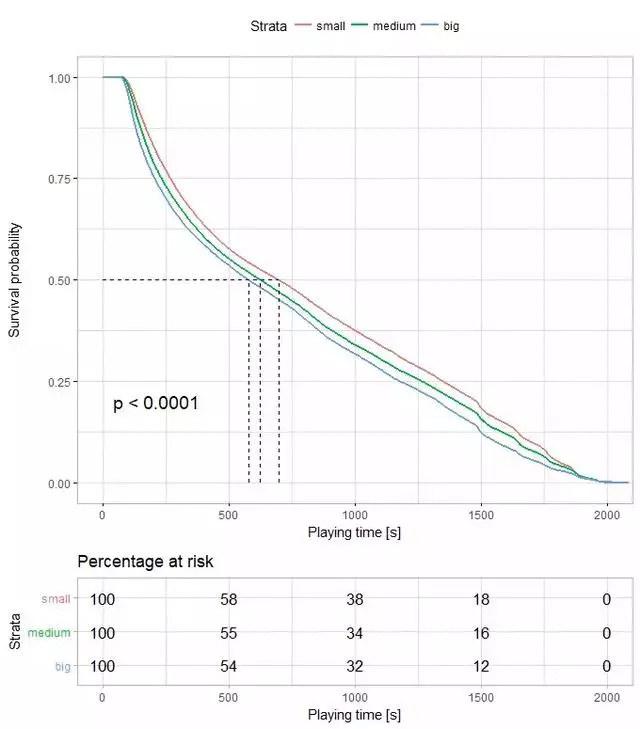
1# R语言代码如下:
2library(magrittr)
3library(dplyr)
4library(survival)
5library(tidyverse)
6library(data.table)
7library(ggplot2)
8library(survminer)
9pubg_full <- fread("../agg_match_stats.csv")
10# 数据预处理,将连续变量划为分类变量
11pubg_sub <- pubg_full %>%
12 filter(player_survive_time<2100) %>%
13 mutate(drive = ifelse(player_dist_ride>0, 1, 0)) %>%
14 mutate(size = ifelse(game_size<33, 1,ifelse(game_size>=33 &game_size<66,2,3)))
15# 创建生存对象
16surv_object <- Surv(time = pubg_sub$player_survive_time)
17fit1 <- survfit(surv_object~party_size,data = pubg_sub)
18# 可视化生存率
19ggsurvplot(fit1, data = pubg_sub, pval = TRUE, xlab="Playing time [s]", surv.median.line="hv",
20 legend.labs=c("SOLO","DUO","SQUAD"), ggtheme = theme_light(),risk.table="percentage")
21f
<- survfit(surv_object~drive,data=pubg_sub)
22ggsurvplot(fit2, data = pubg_sub, pval = TRUE, xlab="Playing time [s]", surv.median.line="hv",
23 legend.labs=c("walk","walk&drive"), ggtheme = theme_light(),risk.table="percentage")
24fit3 <- survfit(surv_object~size,data=pubg_sub)
25ggsurvplot(fit3, data = pubg_sub, pval = TRUE, xlab="Playing time [s]", surv.median.line="hv",
26 legend.labs=c("small","medium","big"), ggtheme = theme_light(),risk.table="percentage")
2. 击杀数与吃鸡概率的关系
- 玩过农药的的童鞋都会知道,收人头收得越多,技能加成越大,伤害越来越大,无人能挡时就是胜利在望。而在吃鸡里面,能活到最后一个就是王者,所以很明显击杀人头越多,吃到鸡的概率并不一定大。那一场游戏里面,击杀多少个算厉害来呢??
- 我们筛选比赛中所有排名第一的玩家,看看他们是击杀数分布:
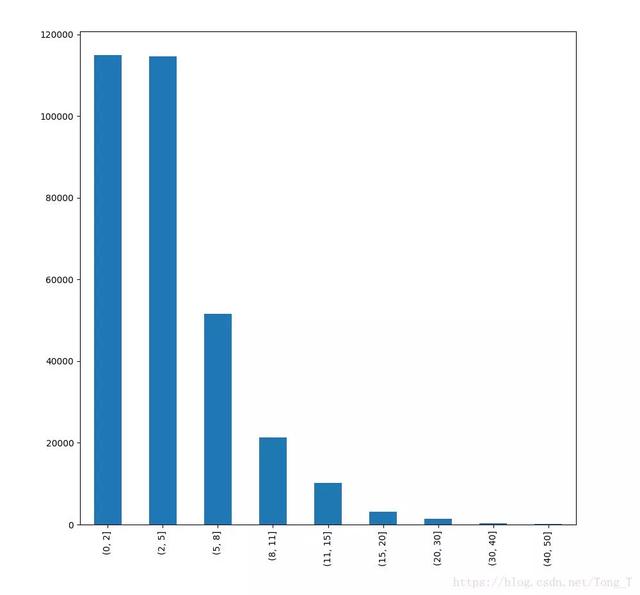
- 看上图是不是挺意外,单场比赛击杀2个以内的占多数,吃到鸡的人也不例外,他们并不追求人头,猥琐发育也很重要.
- 小白玩家也不必担心一场游戏里没人头,击杀一两个机器人也算是收获不小来。
match_stats = pd.read_csv('F:/pubg-match-deaths/aggregate/agg_match_stats_0.csv')
winer = match_stats.loc[(match_stats['team_placement'] == 1), :].dropna()
labels = [0, 2, 5, 8, 11, 15, 20, 30, 40, 50]
winer['kill'] = pd.cut(winer['player_kills'], bins=labels)
winer['assist'] = pd.cut(winer['player_assists'], bins=labels)
winer['kill'].value_counts().plot.bar(figsize=(10, 10))
plt.savefig('out7.png', dpi=100)
3、最后毒圈有可能出现的地点?
- 面对有本事能苟到最后的我,怎么样预测最后的毒圈出现在什么位置。从表agg_match_stats数据找出排名第一的队伍,然后按照match_id分组,找出分组数据里面player_survive_time最大的值,然后据此匹配表格kill_match_stats_final里面的数据,这些数据里面取第二名死亡的位置,作图发现激情沙漠的毒圈明显更集中一些,大概率出现在皮卡多、圣马丁和别墅区。绝地海岛的就比较随机了,但是还是能看出军事基地和山脉的地方更有可能是最后的毒圈。
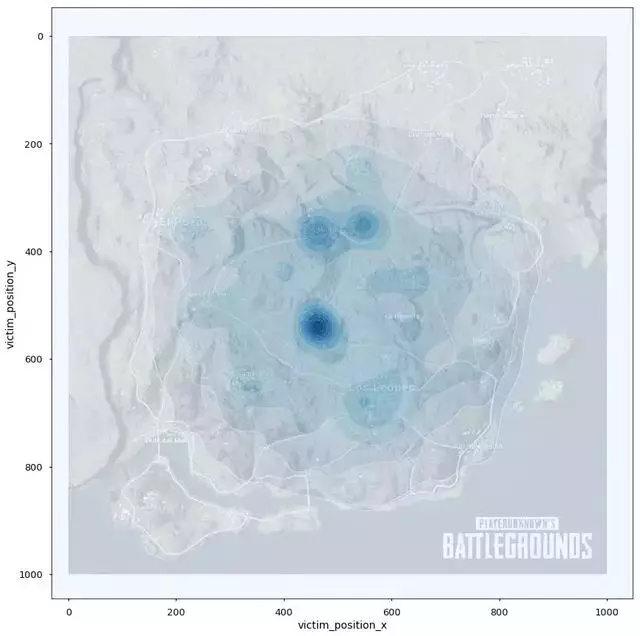

分析结果
1. 平均用户日在线时长2小时
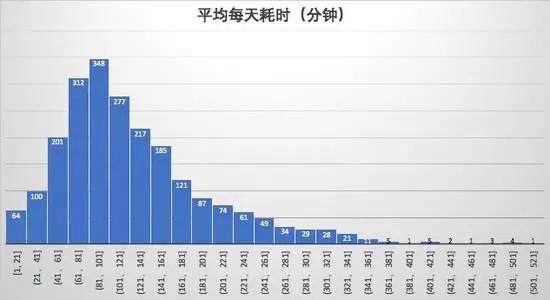
- 从分布图上看大部分用户都在1小时以上,最猛的几个人超过8小时。
- 注:我这里统计的是每一局的存活时间,实际在线时长会比我这个更长。
2. 女性角色被救次数高于男性
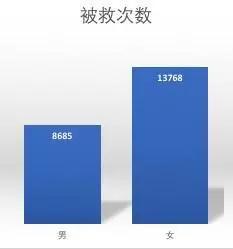
- 终于知道为什么有那么多人妖了,原来在游戏里面可以占便宜啊。
3. 女性角色救人次数高于男性
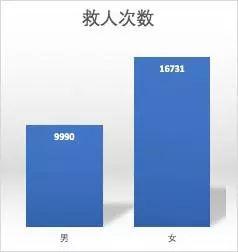
- 给了大家一个带妹上分的好理由。
4. 周五大家最忙
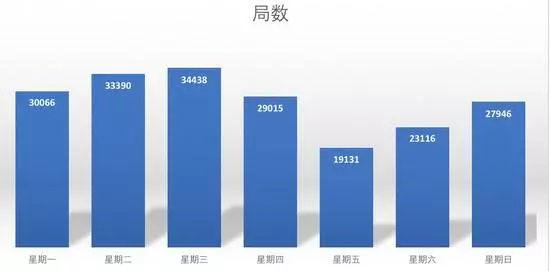
- 估计周五大家都要忙着交差和写周报了。
5. 晚上22点是游戏高峰
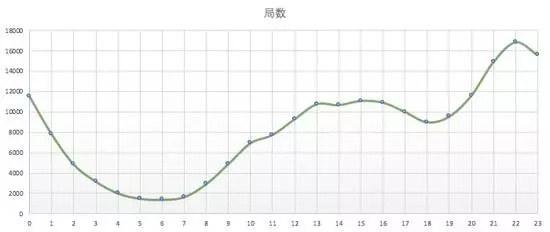
- 凌晨还有那么多人玩,你们不睡觉吗?
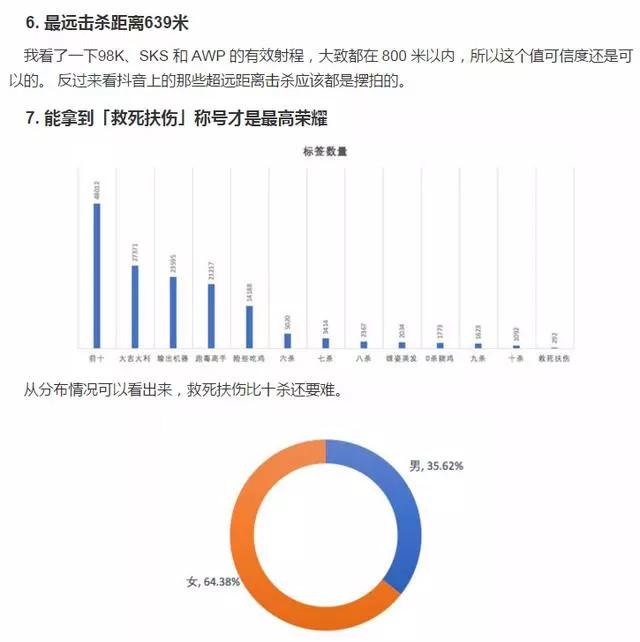
- 能拿到救死扶伤称号的大部分都是女性角色,再一次证明玩游戏要带妹。 回归到这个游戏的本质,那就是生存游戏,没什么比活下来更重要的了。
结尾
- 这次查看了陌生人数据的场景才能提取到这么多数据。我们可以通过同样的手段来分析王者荣耀和其它游戏的数据,有兴趣的同学可以尝试一下。 最后再说一下,98k是把好枪,配8 倍镜非常爽。
1#最后毒圈位置2import matplotlib.pyplot as plt3import pandas as pd4import seaborn as sns5from scipy.misc.pilutil import imread6import matplotlib.cm as cm78#导入部分数据9deaths = pd.read_csv("deaths/kill_match_stats_final_0.csv")10#导入aggregate数据11aggregate = pd.read_csv("aggregate/agg_match_stats_0.csv")12print(aggregate.head())13#找出最后三人死亡的位置1415team_win = aggregate[aggregate["team_placement"]==1] #排名第一的队伍16#找出每次比赛第一名队伍活的最久的那个player17grouped = team_win.groupby('match_id').apply(lambda t: t[t.player_survive_time==t.player_survive_time.max()])1819deaths_solo = deaths[deaths['match_id'].isin(grouped['match_id'].values)]20deaths_solo_er = deaths_solo[deaths_solo['map'] == 'ERANGEL']21deaths_solo_mr = deaths_solo[deaths_solo['map'] == 'MIRAMAR']2223df_second_er = deaths_solo_er[(deaths_solo_er['victim_placement'] == 2)].dropna()24df_second_mr = deaths_solo_mr[(deaths_solo_mr['victim_placement'] == 2)].dropna()25print (df_second_er)2627position_data = ["killer_position_x","killer_position_y","victim_position_x","victim_position_y"]28for position in position_data:29 df_second_mr[position] = df_second_mr[position].apply(lambda x: x*1000/800000)30 df_second_mr = df_second_mr[df_second_mr[position] != 0]3132 df_second_er[position] = df_second_er[position].apply(lambda x: x*4096/800000)33 df_second_er = df_second_er[df_second_er[position] != 0]3435df_second_er=df_second_er36# erangel热力图37sns.set_context('talk')38bg = imread("erangel.jpg")39fig, ax = plt.subplots(1,1,figsize=(15,15))40ax.imshow(bg)41sns.kdeplot(df_second_er["victim_position_x"], df_second_er["victim_position_y"], cmap=cm.Blues, alpha=0.7,shade=True)4243# miramar热力图44bg = imread("miramar.jpg")45fig, ax = plt.subplots(1,1,figsize=(15,15))46ax.imshow(bg)47sns.kdeplot(df_second_mr["victim_position_x"], df_second_mr["victim_position_y"], cmap=cm.Blues,alpha=0.8,shade=True)it2
文章就到这里啦~