版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/winter_wu_1998/article/details/84978864
单周期CPU

- 单周期构造的缺陷
- 由于要保证所有指令在一个周期内完成,时钟周期会很长,也限制了时钟频率的提升
- 各种指令执行的长短时间不一(比如加法和存数据到内存)时间短的指令效率被浪费
- 指令类型
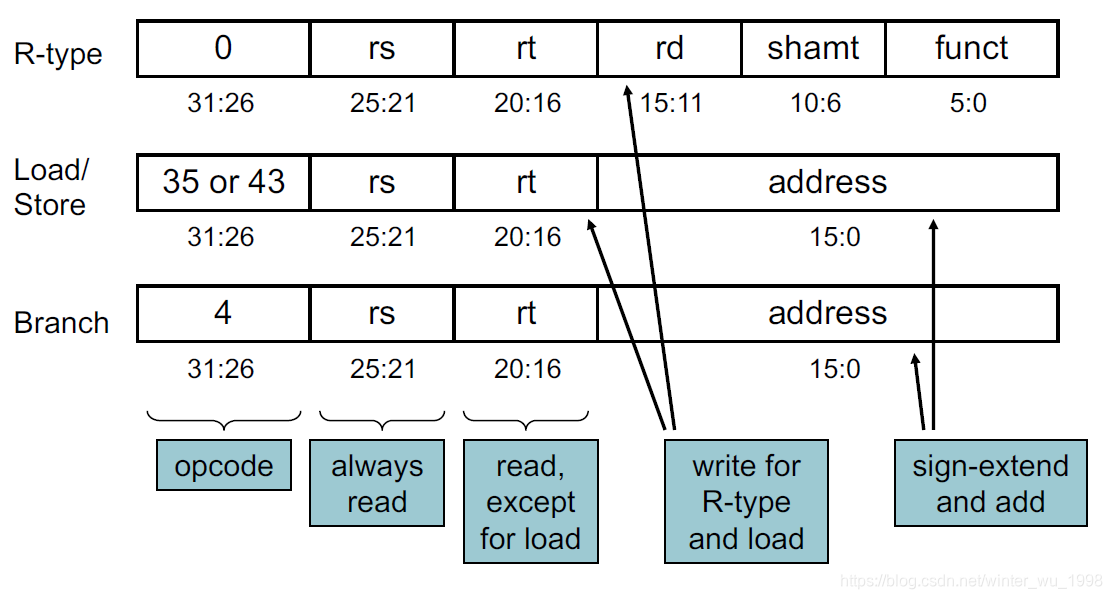
- 指令分为R-type,I-type和J-type
- 一般由最高6位区分
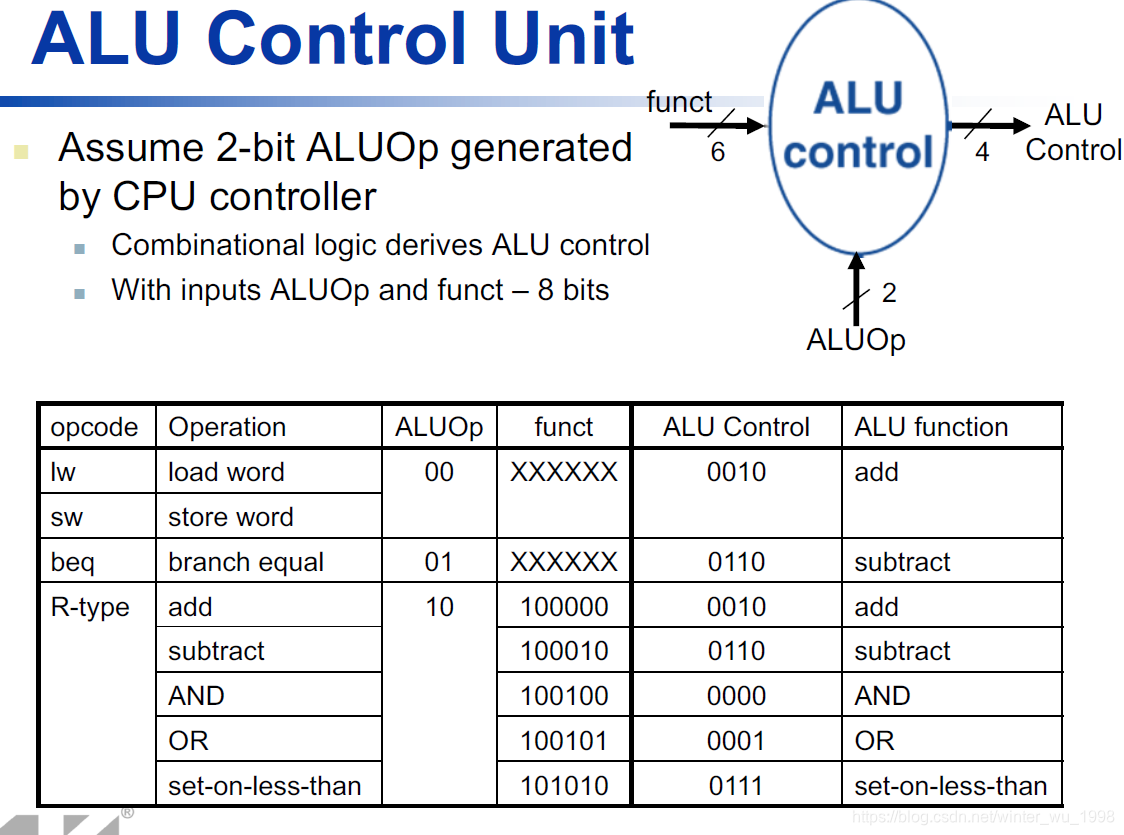
- R-type指令主要执行ALU运算,具体运算由最低6位的funct段决定
- I-type指令主要是和地址与常数相关的指令,如存存储,分支等
- J-type一般是跳转指令
流水线CPU
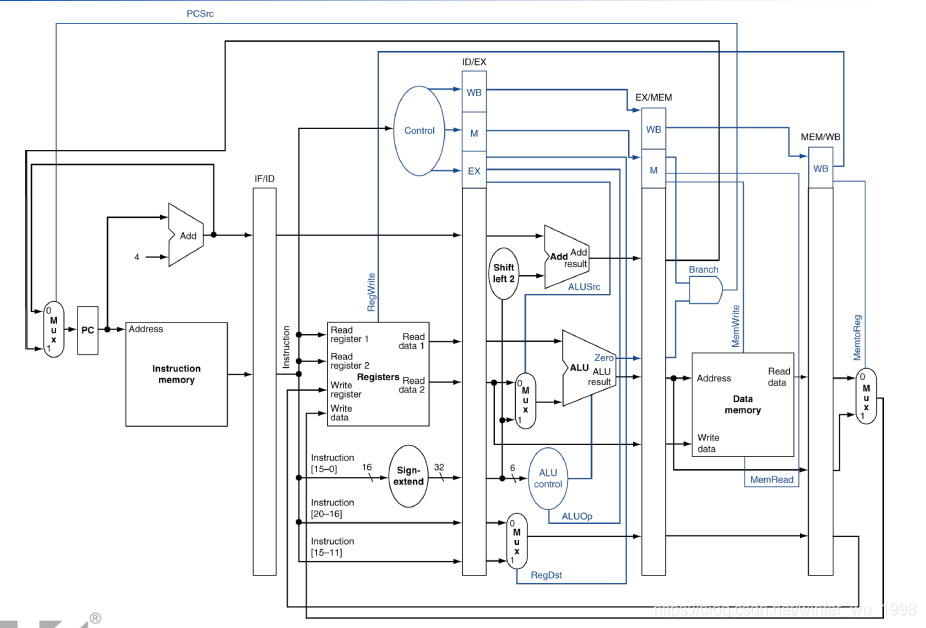
构造
-
stage数
- stage太少则无法发挥流水线优势
- stage太多,由于指令间的依赖性,则会更难处理数据和控制冒险,有更多的阻塞
-
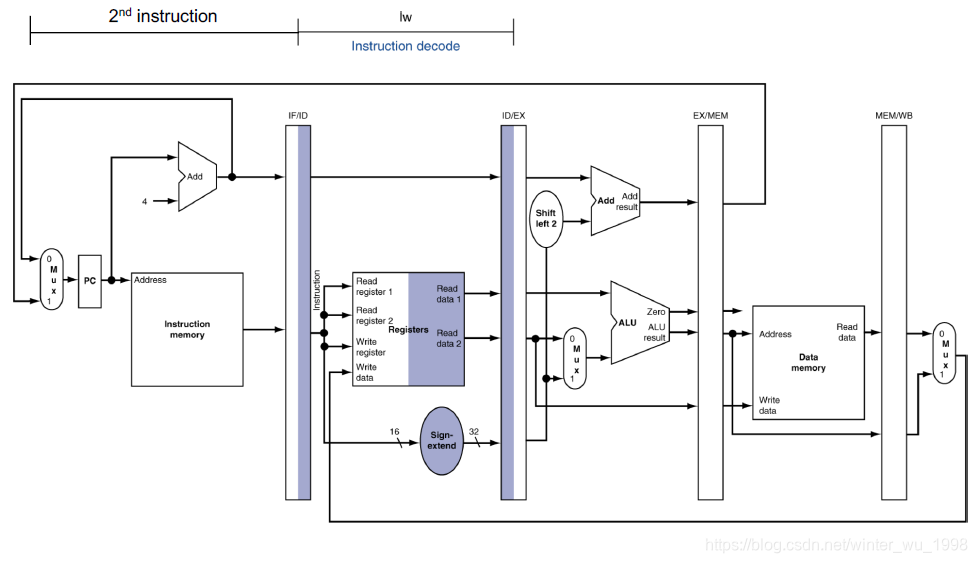
一般分为取指(IF),解码(ID),执行(EX),内存访问(MEM),写回(WB)5个周期
-
为了储存前面周期产生的数据,每个stage之间会有寄存器
-
每个周期又分为前后两个半周期,用来处理对于寄存器和内存的分别的读和写
数据冒险
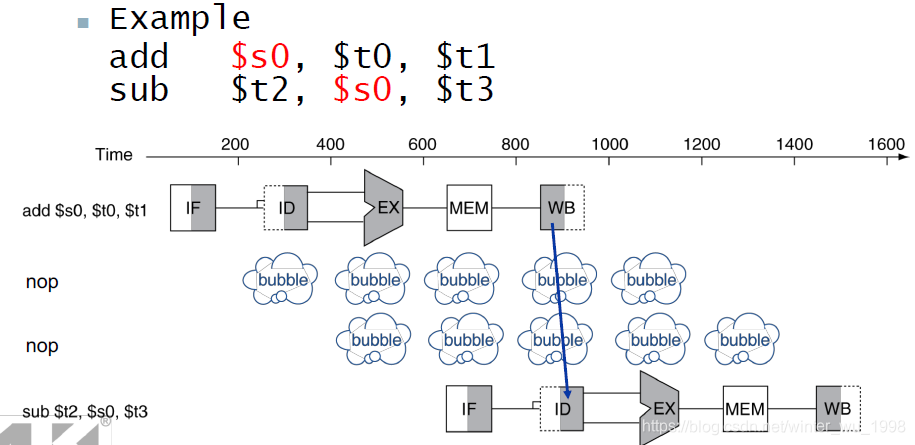
- 指令在IF阶段被读入,而在MEM甚至WB阶段才能返回最终的结果(被存入寄存器和内存中)
- 所以当连续的指令要使用到同一个寄存器或者内存地址的时候,会产生阻塞
- 但是其实在EX阶段结果就已经被计算完成了,只是没存入寄存器和内存中
- 此时通过预先转发就可以避免数据冒险的产生
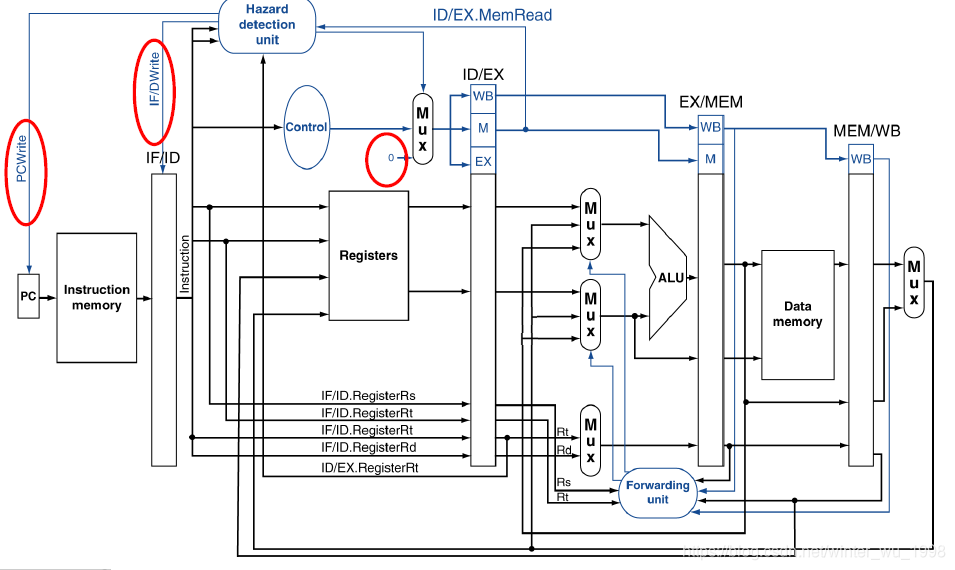
- 有时候即使通过转发任然不能解决数据冒险的问题,这个时候需要阻塞
- 阻塞是将IF,ID,EX阶段已经产生的内存都要清空,并且让PC重复上一个指令地址
- 数据冒险是由访问同一寄存器或内存地址产生的,因此更换代码的顺序可以避免很多数据冒
- 当然这些是由编译器优化的
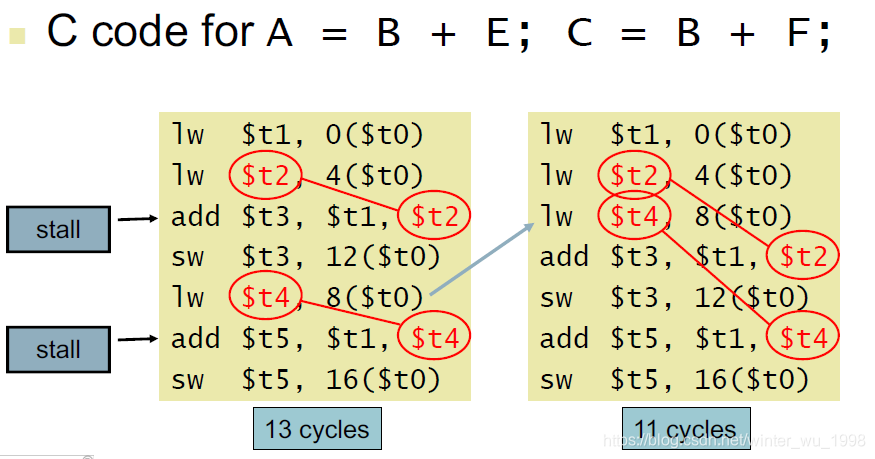
- 当然这些是由编译器优化的
控制冒险
-
由于分支的存在,有时候会产生控制冒险
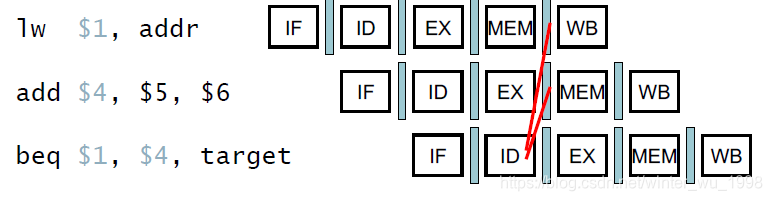
- 对于上面的流水线,分支的确定需要等到MEM才能决定,然而后一条指令在分支指令进行到ID级就读入了
- 堵塞了3个周期
-
假定分支不发生
- 一种解决控制冒险的方式就是一直假定分支不发生
- 继续执行后面的指令,如果分支发生,就丢弃已经读取的指令
-
减少堵塞周期
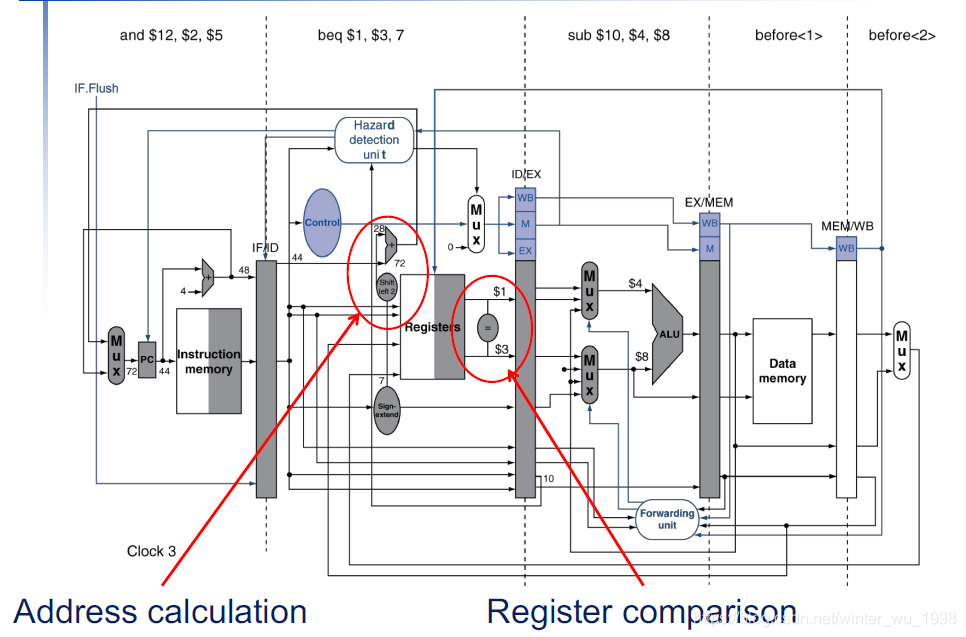
- 其实在ID阶段就可以确定分支跳转相对地址,只需将绝对地址的计算从EX提前到ID,而分支判断结果也可以很方便的计算出来
- 所以可以将分支的判断从MEM提前到ID阶段
- 由此只需堵塞1个周期
- 然而这种构造的改变又会引入新的数据冒险

-
分支预测
- 根据先前的和典型的分支动作,预测此次分支是否发生
- 前者为前者为动态预测,后者为静态预测
-
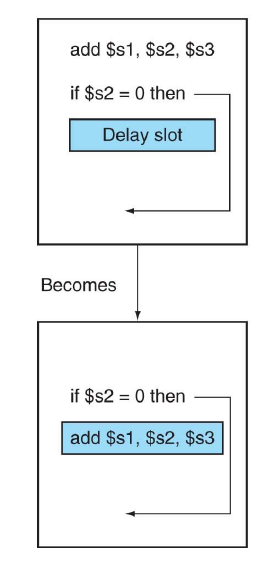
延迟分支发生
- 改变指令的执行顺序从而隐藏堵塞