vim编辑器(文本编辑器):
vi可以执行输出、删除、查找、替换、块操作等众多文本操作。而且用户可以根据自己的需要对其进行定制
vi的工作模式
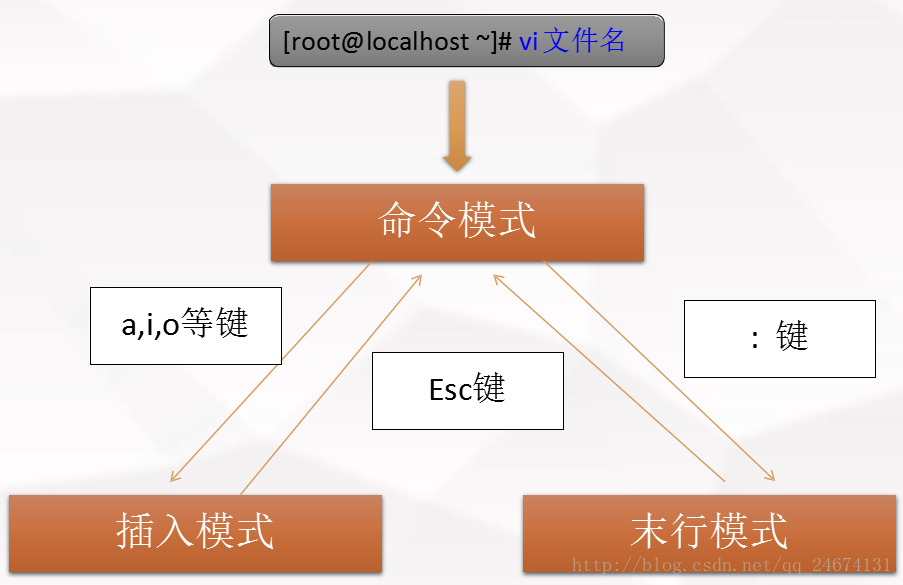
命令模式中的基本操作
插入命令:
i:再当前字符的左边插入
I:在当前行首插入
a:再当前字符的右边插入
A:在当前行尾插入
o:在当前行下面插入新行
O:在当前行上面插入新行
删除命令:
dd:删除当前行
ndd:删除当前行光标所在的位置后面的字符
D:删除当前行光标所在的位置后面的字符
x:向后删除光标所在位置的字符
X:向前删除光标前面的字符
nX:删除前面的n个字符,光标所在的字符将不会被删
复制和粘贴命令:
yy或Y:复制当前行
nyy或nY:复制以下n行
p:在光标后面插入buffer中的内容
P:在光标前面插入buffer中的内容
替换和撤销命令:
r:渠道光标所在处的字符
R:从光标所在处开始替换字符,按esc结束
u:撤销上一步操作
定位命令:
h:左移一个字符
l:右移一个字符
j:下移一行
k:上移一行
$:移至行尾
0:移至行首
gg:移到第一行
G移到最后一行
nG:移到第n行
末行模式中的基本操作:
查找操作:set nu 设置行号
set nonu 取消行号
n 移到第n行
/查找关键字
替换操作:
s/old/new 将当前行中查找的第一个字符"old" 串替换为"new"
s/old/new/g 将当前行中查找的所有字符串"old"替换为"new"
#,# s/old/new/g 在行号"#,#" 范围内替换所有的字符串"old"为"new"
% s/old/new/g 在整个文件范围内替换所有的字符串"old"替换为"new"
%s/old/new 查找文件中所有行第一次出现的old,替换为new
其他命令:
W[文件路径] 保存当前文件
q如果未对文件做改动则退出
q!放弃存储名退出
wq 或x 保存退出
可视模式:
v:可视模式(一个一个选择)
V:可视行模式(一行一行选择)
Ctrl+v:可视块模式
在所有可视模式中。d和x可以用删除选定的内容
用户和组
用户:
用户在系统中是分角色的,通过UID来识别角色
root用户,系统唯一,可以操作系统任何文件和命令,拥有最高权限,UID=0
虚拟用户(系统账户),不具有登录系统能力,但却是系统运行不可缺少的用户。如:bin、daemon、ftp、mail等,UID为1---499之间
普通真实用户,可以登录系统,权限有限 靠管理员创建,UID为500-60000之间
为了更好的管理用户,出现组group
基本组(私有组)当用户创建文件和文件夹时,默认属于私有组
附加组(公共组)
用户管理:
用户账号文件: --/etc/passwd
每行对应一个用户的账号记录,一行有7个段位,用:隔开
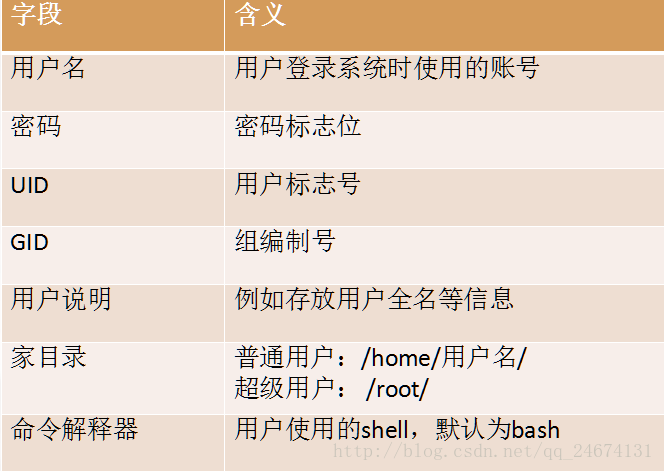
每行的具体信息
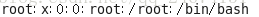

用户密码文件:--/etc/shadow(用于保存密码子串、密码有效期等信息)
每一行对应一个用户的密码记录

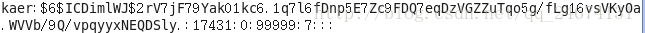

用户管理命令:
添加用户账号:
命令格式:useradd[选项] 用户名
常用选项
-u:指定UID标记号
-d:指定数主目录,缺省为/home/用户名
-e:指定账号失效时间,格式YYYY-MM-DD
-g:指定用户的基本组名
-G:指定用户的附加组名
-M:不为用户建立并初始化宿主目录
-s:指定用户的登录Shell
-n:取消建立以用户名称为名的群组
设置密码:
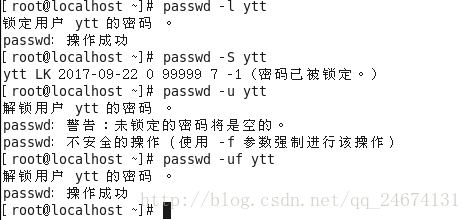
命令格式:passwd[选择]<用户名>
-d:清空用户名的密码,使之无需密码即可登录
-l:锁定用户账号(usermod中为 -L)
-S:查看用户账号的状态(是否被锁定)
-u:解锁用户账号(usermod中为 -U)
-x:最大密码使用时间(天)
-n:最小密码使用(天)
修改已有用户的属性:
usernod [选项] <用户名>
常用命令选项:
-l:更改用户的账号名称
-L:锁定用户账户
-U:解锁用户账户
-u -d -e -g -G -s 和useradd命令中的含义相同
删除用户账号:
命令格式:userdel [选项] 用户名
常用命令选项 -r: 把用户的宿主目录一并删除
组管理:
组管理配置文件:
用户组文件:/etc/group

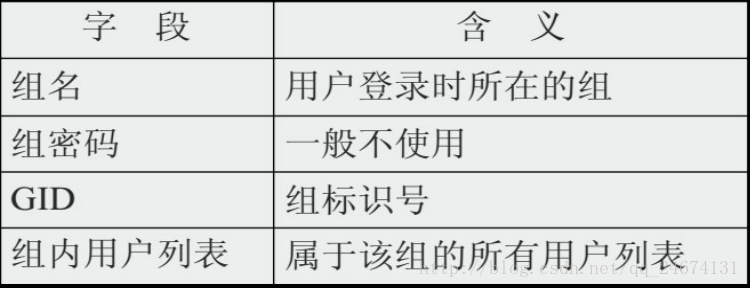
用户组密码文件:/etc/gshadow

用户组
用户组密码,如果是空或者有"!",表示没有密码
用户组管理者
组成员,用逗号","隔开

组管理命令
添加组账号:
命令格式: groupadd[选项]<用户名>
常用命令选项:
-g:指定新建工作组的id
-r:创建系统工作组,系统工作组的id小于500
-o:允许添加组id号不唯一的工作组
修改用户组的属性:
命令格式 groupmod[选项]<用户名>
常用命令选项:
-g:设置想要使用的GID
-o:使用已经存在的GID
-n:设置想要使用的群组名称
设置组账号密码、添加/删除组成员:
命令格式 gpasswd [选项] 组账号名
常用命令选项:
-a:向组内添加一个用户
-d:从组内删除一个用户
-M:定义组成员列表,以逗号分隔
删除组账号:
命令格式:groupdel<组账号名>
注意:只能删除那些没有被任何用户指定为主组的组
显示用户所属组: groups 用户名

文件即目录权限管理
权限和权限值
权限:
读(r)写(w)执行(x)
4 2 1
设置文件或目录权限
格式: chmod [ugoa] [+-=] [rwx] file/dir
chmod nnn file/dir
参数解释: u:属主 g:属组 o:其他用户 a:所有用户
+添加 -删除 =赋予权限
nnn:三位八进制的权限
常用命令选项 -R 递归修改指定目录下的所有子文件及文件夹的权限
设置文件或目录归属:
chown命令 格式 chown 属主 file/dir
chown :属组 file/dir
chown 属主:属组 file/dir
常用命令选项 -R 递归修改指定目录下的所有子文件及子目录的归属

高级文本处理命令:
sed
1
、删除:
d
命令
sed'2d'huangbo.txt --删除huangbo.txt文件的第二行
sed'2,$d'huangbo.txt--删除huangbo.txt文件的第二行到末尾所有行
sed'$d'huangbo.txt--删除huangbo.txt文件的最后一行
sed'/test/d' huangbo.txt--删除huangbo.txt文件包含test的行
2、替换:
s
命令
格式: sed's/要替换的字符串/新字符串/g'
sed 's/test/mytest/g' huangbo.txt
在整行范围内把test替换为mytest。如果没有g标记,则只要每行第一个匹配的test替换成mytest
sed -n 's/^test/mytest/p' huangbo.txt
(-n)选项和p标志一起使用表示只打印那些发生替换的行。
没有-n 表示答应发生变化的行以及文本的全部内容
sed 's/^192.168.0.1/&localhost/' huangbo.txt
追加在以192.168.0.1开头的行 变成 192.168.0.1localhost
选定行的范围
sed -n '5,/^test/p' .txt
sed -n '/^test/5p' .txt
打印从第5行开始到第一个包含以test开头的行之间的所有行
打印从以test开头往后的8行
sed '/test/,/check/s/$/sed test/' huangbo.txt
对于模板test和check之间的行,每行的末尾用字符串sed test替换
3、多点编辑:
e
命令
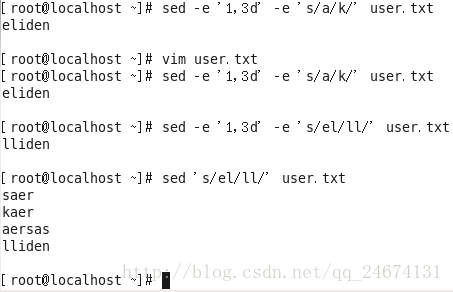
sed -e '1.5d' -e 's/test/check/' huangbo.txt
(-e)选项允许在同一行执行多条命令,第一条命令删除1至5行,第二条命令用check替换test。
4、从文件读入:r命令
sed'/test/r file' huangbo.txt
file里的内容被读进来,显示在与test匹配的行下面,如果匹配多行,则file的内容将显示在所有匹配行的下面。

5、写入文件: w命令
sed -n '/test/w file' huangbo.txt
在huangbo.txt中所包含test的行都被写入file里
6、追加命令:a命令
sed '/^test/a\\--->this is a example' huangbo.txt

7、插入:i命令
sed '/test/i\\some this new ------' huangbo.txt
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面

8、退出:q命令
sed '10q' huangbo,txt
打印完第10行后,退出sed
awk
(优点:awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符,将每行切片,切开的部分再进行各种分析处理。)
awk'{pattern+action}'{filenames}
pattern 表示awk在数据中查找的内容,而action是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。
pattern就是要表示的正则表达式,用斜杠括起来
2、只显示5个最近登录的账号
last -n 5 | awk '{print $1}'
awk 工作流程:读入有'\n'换行符分隔的一条记录,然后记录按指定的域分隔符,化分域,填充域, $0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符为空白键或"tab"键。
以上均为 awk+action的示例
awk '/root/' /etc/passwd
root:x:0:0:root:/root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern的行才会执行action
awk -F ':' '/root/{print$7}' /etc/passwd
这里指定了action{print$7}

awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
uniq
功能说明:合并文件中相邻的行
语法:uniq[选项][文件]
常用选项:
-i:忽略大小写字符的不同
-c:进行重复出现行的计数
-d:仅显示重复出现的行
-u:仅显示重复一次的行列
使用last将账号列出,仅取出账号栏,进行排序
last | cut -d ' ' -f | sort | uniq -c | sort -n
只显示修改的:

cut和awk在分割时的区别

cut 是一个选取命令,它就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的,并不是整篇信息分析的
cut 语法
cut<选项> 文件
选项与参数:
-d:后面接分隔字符。与-f一起使用
-f:依据-d的分隔字符将一段信息分隔成为数段,用-f取出第几段的意思
-c:以字符(characters)的单位取出固定字符区间
-b:以字节为单位进行分割
echo $PATH | cut -d ':' -f 5取出一行第五个数据
echo $PATH | cut -d ':' -f 3,5取出第三个和第五个数据
echo $PATH | cut -d ':' -f 3- 找出第三个到最后一个
echo $PATH | cut -d ':' -f 1-3,5找出第一个到第三个还有第五个数据
cut -c 2-3 .txt 获得第二个字符到第三个字符之间的字符
cut -b 2,5 .txt获取第二个和第五个字节