我们当前所开发的网络都遵循同一个模式,那就是串行化。多个网络层按照前后次序折叠起来,数据从底层输入,然后从最高层输出,其结构如下图:
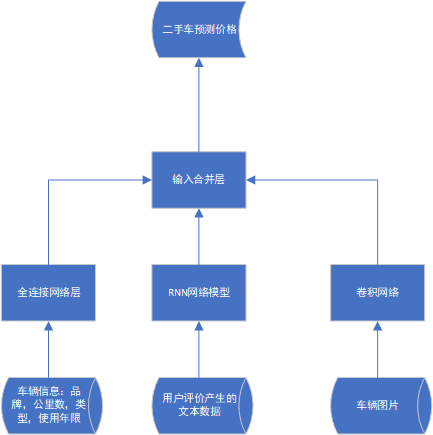
事实上这种形式很不灵活,在很多应用场景中不实用。有些应用场景需要网络同时接收多种输入,有些应用场景要求网络能同时又多种输出,有些需要网络内部的网络层发送分叉,像一颗多叉树那样。有一些更复杂的网络结构是,它同时接收来自不同网络的输出,试想我们想要预测二手车在市场上的售价,此时网络可能要同时接收三种类型的信息,一种是对车辆的描述,例如车的品牌,类型,使用年限,公里数等;一种是用户评价产生的文本资料;一种是车辆的图片。于是我们就可能需要如下形式的网络结构:
还有一种情况是多类型预测。给定一本小说,我们需要预测这本小说所属类型,是言情类还是历史类,同时还需要预测小说的创作年代,于是网络的输出就必须要有两个以上的分支:
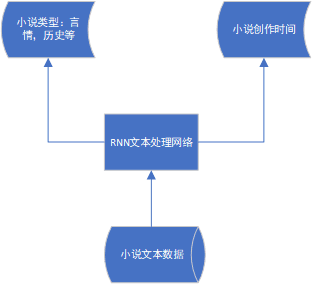
对于上面问题,我们可以构造两个网络去分别预测小说的类型和创造时间,但由于这两种数据高度相关,知道小说的创作时间很有利于对小说类型的预测,因此把他们整合在一个网络结构里分析显然更为合理。同时随着神经网络应用越来越广泛,应用场景对网络结构的要求也越来越多样化,有一类网络叫Inception network,它的特点是输入数据同时由多个网络层并行处理,然后得到多个处理结果,这些处理结果最后同时归并到同一个网络层,如下图:
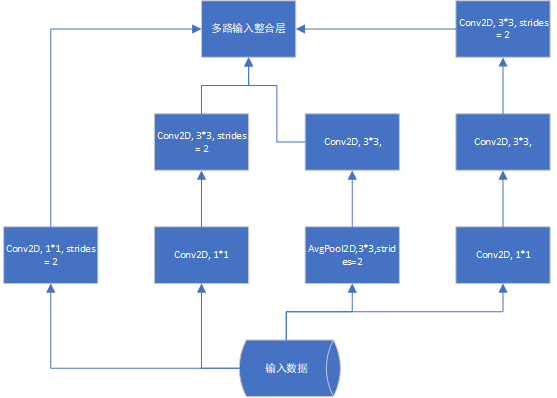
谷歌开发的一种强大图像处理网络就属于上面的结构类型。所有原有的串行化结构无法适应很多复杂的应用场景,因此我们必须使用新的方法构建出类似上面的多样化神经网络,好在keras导出很多API,让我们方便的构建各种类型的深度网络,我们用具体代码来看看如何构造各种形态的网络,
from keras.models import Model
from keras import layers
from keras.utils import plot_model
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 1000
answer_vocabulary_size = 500
text_input = Input(shape=(None, ), dtype='int32', name = 'text')
embedded_text = layers.Embedding(64, text_vocabulary_size)(text_input)
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape = (None, ), dtype='int32', name='question')
embedded_question = layers.Embedding(32, question_vocabulary_size)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question], axis = -1)
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated)
model = Model([text_input, question_input], answer)
plot_model(model, to_file='model.png', show_shapes=True)
我们无需输入数据运行训练网络,我们只要把握上面网络的拓扑结构即可,上面代码的最后一句会把网络图像绘制出来,为了代码能正确运行,我们需要安装一个插件名为graphviz,通常情况下使用如下命令安装即可:
pip install graphviz
安装插件再运行上面代码后,网络的拓扑结构会绘制在model.png图形文件里,它的结构如下所示:
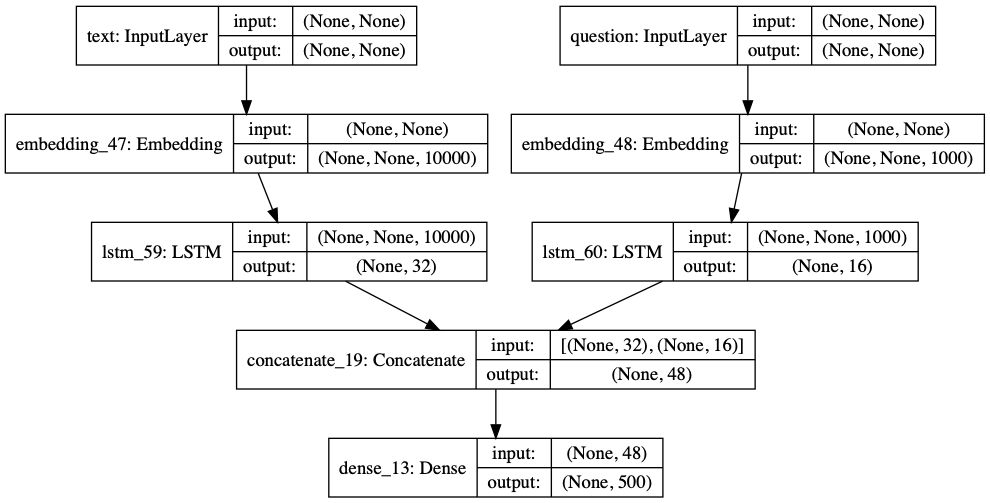
我们看到该网络并非我们常见的串行结构,最上层是两个并行分支,其输出的结果在网络层concatenate_19合并后再输入最后一层dens_13。这是一个多输入单输出的网络,当我们需要构建一个网络,它能读入数据并预测多种不同类型的数值时,这类网络就是单输入多输出的情况,一个具体例子如下:
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None, ), dtype = 'int32', name = 'posts')
embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation='relu')(x)
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name = 'gender')(x)
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
model.compile(optimizer='rmsprop', loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'], loss_weights = [0.25, 1. , 10.])
plot_model(model, to_file='model2.png', show_shapes=True)
上面代码构建的网络用语读入个人数据,然后预测该人的年龄,收入以及性别,代码运行后,我们得到网络的拓扑图如下:
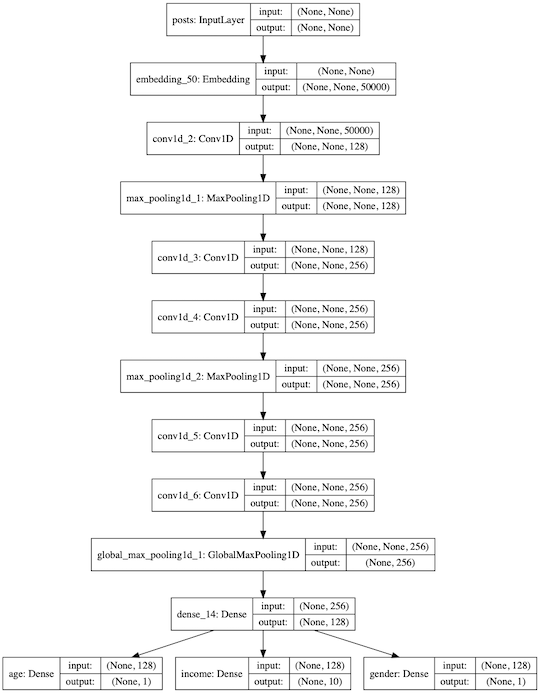
注意到当网络有多种输出时,我们必须对每种输出定义相应的损失函数,keras会把三种输出结果加总,然后使用梯度下降法修正整个网络的参数。但是这么做会产生一种情况,如果某个分支输出误差较大,那么网络调整参数时就会更多的去照顾这个分支,从而影响其他分支结果的准确性,处理这个问题的办法是为每个输出分支设定一个权重从而影响每个分支在参数调整是所产生的影响。
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
