目录
Generationanl GC
引入年龄的概念,优先回收年轻的已成为垃圾的对象。
什么是分代垃圾回收
对象对的年龄
书上说:“人们 从众多案例总结出一个经验:‘大部分的对象再生成后马上就变成了垃圾。很少有对象活的很久’。”,分代,引入年龄概念,经历过一次GC的对象年龄为一岁。
新生代对象和老年对象
分代垃圾回收中,将对象分为几类(几代),针对不同的代使用不同的GC算法。刚生成的对象称之为新生代,到达一定年龄的对象称为老年代对象。
我们对新生代对象执行的GC称为新生代GC(minor GC)。新生代GC的前提是大部分新生代对象都没存活下来,GC在很短时间就结束了。新生代GC将存活了一定次数的对象当做老年代对象来处理。这时候我们需要把新生代对象上升为老年代对象(promotion)。老年代对象比较不容易成为垃圾,所以我们减少对其GC的频率。我们称面向老年代对象的GC为老年代GC(major GC)。
分代垃圾回收是将多种垃圾回收算法并用的一种垃圾回收机制。
Ungar的分带垃圾回收
堆的结构
Ungar分代垃圾回收中,堆结构图如下所示。总共需要四个空间,分别是生成空间、两个大小相等的幸存空间、老年代空间,分别用$new_start、$survivor1_start、$survivor2_start、$old_start这四个变量指向他们开头。
生成空间和幸运空间合称为新生代空间,新生代对象会被分配到新生代空间,老年代对象则会被分配到老年代空间里。Ungar 在论文里把生成空间、幸存空间以及老年代空间的大小分别设成了 140K 字节、28K 字节和 940K 字节。
此外我们准备出一个和堆不同的数组,称为记录集(remembered set),设为 $rs。

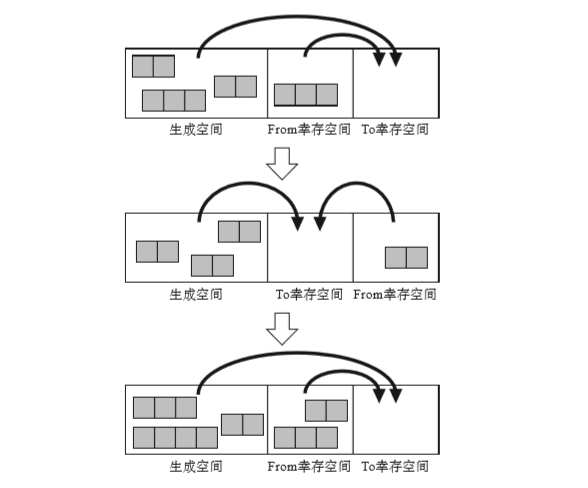
- 生成空间,是生成对象的空间。当空间满了新生代GC就会启动,将生成空间里的对象复制,与GC复制算法一样。
- 两个幸存空间,一个From一个To。
- 新生代GC将From空间和生成对象空间里活动的对象复制到To空间中。(这有一个问题,会造成To可能不够用)
- 只有经过一定次数的新生代GC才能被放到老年代空间中去。
过程如下图所示:
- 新生代GC要注意一点,就是老年代空间到新生代空间的引用。因此除了一般GC的根,老年代空间里也会有新生代空间对象的引用来当做根。
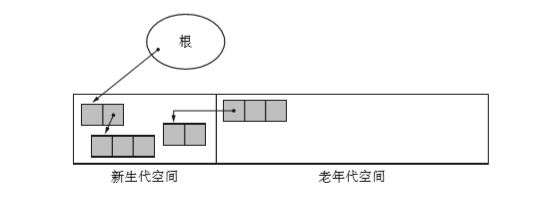
- 分代垃圾回收的优点,将重点放置新生代的对象,他们容易被回收。这样会缩减GC所需的时间。但是,如果我们让老年代对象引用新生代对象这样一来等同于所有对象都从根引用。这样就没有这样的优势了。
- 所以我们引入记录集。记录集用来记录老年代对象到新生代对象的引用。这样就可以不搜索老年代空间里的所有对象,而是通过搜索记录集来发现老年代对象到新生代对象的引用关。
- 当老年代空间满了的时候,就要进行老年代GC了。
记录集
记录集用于高效的寻找从老年代对象到新生代对象的引用。在新生代 GC 时将记录集看成根(像根一样的东西),并进行搜索,以发现指向新生代空间的指针。
不过如果我们为此记录了引用的目标对象(即新生代对象),那么在对这个对象进行晋升(老 年化)操作时,就没法改写所引用对象(即老年代对象)的指针了。如下图示:
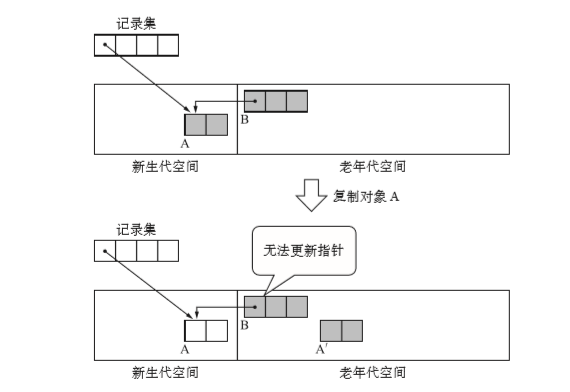
通过查找可知对象A时新生代GC的对象,执行GC后它升级为了老年代对象A'。但在这个状态下我们不发更新B的引用为A',记录集里没有存储老年代对象 B 引用了新生代对象 A的信息。
所以记录集里记录的不是新生代对象,而是老年代对象。他记录的老年代对象都是有子对象是新生代对象的。这样我们就能去更新B了。
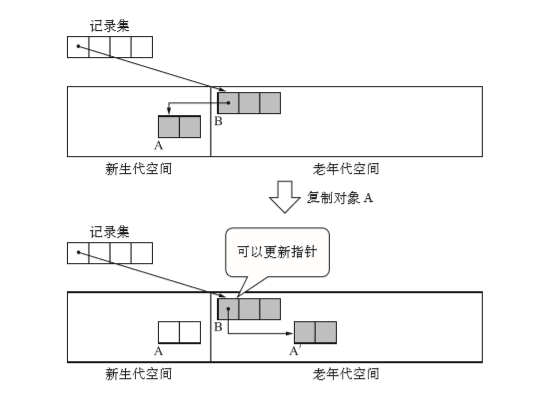
记录集大部分使用固定大小数组来实现。那么我们如何向记录集里插入对象呢?关于写入屏障内容。
写入屏障
将老年代对象记录到记录集里,我们利用写入屏障(write barrier)。write_barrier()函数。
write_barrier(obj, field, new_obj){
if(obj >= $old_start && new_obj < $old_start && obj.remembered == FALSE)
$rs[$rs_index] = obj
$rs_index++
obj.remembered = TRUE
*field = new_obj
}obj 是发出引用的对象,obj内存放要更新的指针,而field指的就是obj内的域,new_obj 是在指针更新后成为引用的目标对象。
- 检测发出引用的对象是不是老年代对象,指针更新后引用的目标是不是新生代对象,发出引用的对象是否还没有被记录到记录集中。
- 当这些都为真时,obj就被记录到记录集中了。
- $rs_index适用于新纪录对象的索引
最后一行,用于更新指针。
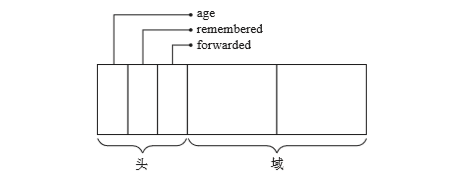
对象的结构
对象的头部除了包含对象的种类和大小之外,还有三条信息,分别是对象的年龄(age)、已经复制完成的标识(forwarded)、向记录集中记录完毕的标识(remembered)。
- age标识新生代对象存活的次数。超过一定次数,就会被当做老年代对象。
- forwarded,用来防止重复复制相同的对象。
- remembered用来防止登记相同的对象。不过remembered只适用于老年代对象,age和forwarded只使用新生代的对象。
- 除上面三点之外,这里也是用forwarding指针之前的垃圾回收一样。在forwarding指针中利用obj.field1,用obj.forwarding访问obj.field1。
对象结构如下图示:
分配
在生成空间里进行,执行new_obj()函数代码如下:
new_obj(size){
if($new_free + size >= $survivor1_start)
minor_gc()
if($new_free + size >= $survivor1_start)
allocation_fail()
obj = $new_free
$new_free += size
obj.age = 0
obj.forwarded = FALSE
obj.remembered = FALSE
obj.size = size
return obj
}- $new_free指向生成空间的开头
- 检测生成空间是否存在size大小的分块。如果没有就执行新生代GC。执行后所有对象都到幸存空间去了,生成空间绝对够用。
- 分配空间。
- 对对象进行一系列的标签之类的设置(初始化)。然后返回。
新生代GC
生成空间被对象沾满后,新生代GC就会启动。minor_gc()函数负责吧生成空间 和From空间的活动对象移动到To空间。
我们先来了解minor_gc()中进行复制对象的函数copy()。
copy(obj){
if(obj.forwarded == FALSE) // 检测对象是否复制完毕
if(obj.age < AGE_MAX) // 没有复制则检查对象年龄
copy_data($to_survivor_free, obj, obj.size)// 开始复制对象操作
obj.forwarede = TRUE
obj.forwarding = $to_survivor_free
$to_survivor_free.age++
$to_survivor_free += obj.size// 复制对象结束
for(child :children(obj)) // 递归复制其子对象
*child = copy(*child)
else
promote(obj) //如果年龄够了,则进行晋级的操作,升级为老年代对象。
return obj.forwarding //返回索引
}promote(obj){
new_obj = allocate_in_old(obj)
if(new_obj == NULL) // 判断能否将obj放入老年代空间中。
major_gc() //不能去就启动gc
new_obj = allocate_in_old(obj)// 再次查询
if(new_obj == NULL) //再次查询。
allocation_fail()//不能放入的话就报错啦。
obj.forwarding = new_obj // 能放入则设置对象属性
obj.forwarded = TRUE
for(child :children(new_obj)) //启动GC
if(*child < $old_start) // obj是否有指向新生代对象的指针
$rs[$rs_index] = new_obj // 如果有就将obj写到记录集里。
$rs_index++
new_obj.remembered = TRUE
return
}minor_gc(){
$to_survivor_free = $to_survivor_start // To空间开头
for(r :$roots) // 寻找能从跟复制的新生代对象
if(*r <$old_start)
*r = copy(*r)
i = 0 // 开始搜索记录集中的对象$rs[i] 执行子对象的复制操作。
while(i<$rs_index)
has_new_obj = FALSE
for(child :children($rs[i]))
if(*child <$old_start)
*child = copy(*child)
if(*child < $old_start) //检查复制后的对象在老年代空间还是心神的古代空间
has_new_obj = TRUE //如果在新生代空间就设置为False否则True
if(has_new_obj ==FALSE) // 如果为False,$rs[i]就没有指向新生代空间的引用。接下来就要自己在记录集里的信息了。
$rs[i].remembered = FALSE
$rs_index--
swap($rs[i], $rs[$rs_index])
else
i++
swap($from_survivor_start, $to_survivor_start) // From 和To互换空间
}
幸存空间沾满了怎么办?
- 通常的GC复制算法把空间二等分为From空间和To空间,即使From空间里的对象都还 活着,也确保能把它们收纳到To空间里去。
- 不过在Ungar的分代垃圾回收里,To幸存空间必 须收纳 From 幸存空间以及生成空间中的活动对象。From 幸存空间和生存空间的点大小比 To 幸 存空间大,所以如果活动对象很多,To 幸存空间就无法容纳下它们。
- 当发生这种情况时,稳妥起见只能把老年代空间作为复制的目标空间。当然,如果频繁发生 这种情况,分代垃圾回收的优点就会淡化。
- 然而实际上经历晋升的对象很少,所以这不会有什么重大问题,因此在伪代码中我们就把这 步操作省略掉了。
老年代GC
就之前介绍的GC都行,但是具体使用哪个看想要的效果以及内存的大小来决定。一般来说GC标记清除就挺好的。
优缺点
吞吐量得到改善
通过使用分代垃圾回收,可以改善 GC 所花费的时间(吞吐量)。正如 Ungar 所说的那样:“据实验表明,分代垃圾回收花费的时间是 GC 复制算法的 1/4。”可见分代垃圾 回收的导入非常明显地改善了吞吐量。
在部分程序中会起到反作用
“很多对象年纪轻轻就会死”这个法则毕竟只适合大多数情况,并不适用于所有程序。当然, 对象会活得很久的程序也有很多。对这样的程序执行分代垃圾回收,就会产生以下两个问题。
- 新生代GC花费时间增多
- 老年代GC频繁
除此之外,写入屏障等也导致了额外的负担,降低了吞吐量。当新生代GC带来的速度提升特别小的时候,这样做很明显是会造成相反的效果。
记录各代之间的引用的方法
Ungar的分带垃圾回收,使用记录集来记录各个代间的引用关系。这样每个发出引用的对象就要花费1个字的空间。此外如果各代之间引用超级多还会出现记录集溢出的问题。(前面说过记录集一般是一个数组。)
卡片标记
Paul R.Wilson 和 Thomas G.Moher开发的一种叫做卡片标记(card marking)的方法。
首先把老年代空间按照等大分割开来。每一个空间就成为卡片,据说卡片适合大小时128字节。另外还要对各个卡片准备一个标志位,并将这个作为标记表格(mark table)进行管理。
当因为改写指针而产生从老年对象到新生代对象的引用时,要事前对被写的域所属的卡片设置标志位,及时对象夸两张卡片,也不会有什么影响。
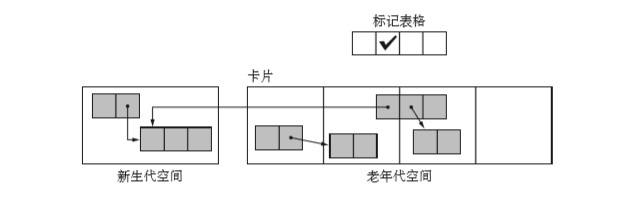
GC时会寻找位图表格,当找到了设置了标志位的卡片时,就会从卡片的头开始寻找指向新生代空间的引用。这就是卡片的标记。
因为每个卡片只需要一个位来进行标记,所以整个位表也只是老年代空间的千分之一,此外不会出现溢出的情况。但是可能会出现搜索卡片上花费大量时间。因此只有在局部存在的老年代空间指向新生代空间的引用时卡片标记才能发挥作用。
页面标记
许多操作系统以页面为单位管理内存空间,如果在卡片标记中将卡片和页面设置为同样大小,就可以使用OS自带的页了。
一旦mutator对堆内的某一个页面进行写入操作,OS就会设置根这个也面对应的位,我们把这个位叫做重写标志位(dirty bit)。
卡片标记是搜索标记表格,而页面标记(page marking)则是搜索这个页面重写标志位。
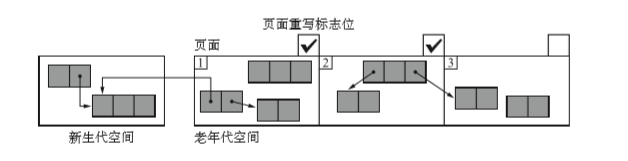
根据 CPU 的不同,页面大小也不同,不过我们一般采用的大小为4K字节。这个方法只适用于能利用页面重写标志位或能利用内存保护功能的环境。
多代垃圾回收
Multi-generational GC
将对象划分为多个代,这样一来能晋升的对象就会一层一层的减少了。

- 除了最老的那一代,每一代都有一个记录集。X代的记录集只记录来自比X老的其他代的引用。
- 分代越多,无意对象越快被回收,这个方法每一层的对象都在减少。
- 但是不能过度增加,想想一下,我们的cpu竟然同时在做很多的GC算法,简直不能理解是吧。
- 书上说,2-3代是最好的。不过我想还是要看情况的。