版权声明:本文为小盒子原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_35393693/article/details/84976434
search
需求:匹配出文章阅读的次数
#coding=utf-8
import re
ret = re.search(r"\d+", "阅读次数为 9999")
ret.group()
运行结果:

findall
需求:统计出python、c、c++相应文章阅读的次数
#coding=utf-8
import re
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print ret
运行结果:

sub 将匹配到的数据进行替换
需求:将匹配到的阅读次数加1
方法1:
#coding=utf-8
import re
ret = re.sub(r"\d+", '998', "python = 997")
print ret
运行结果:

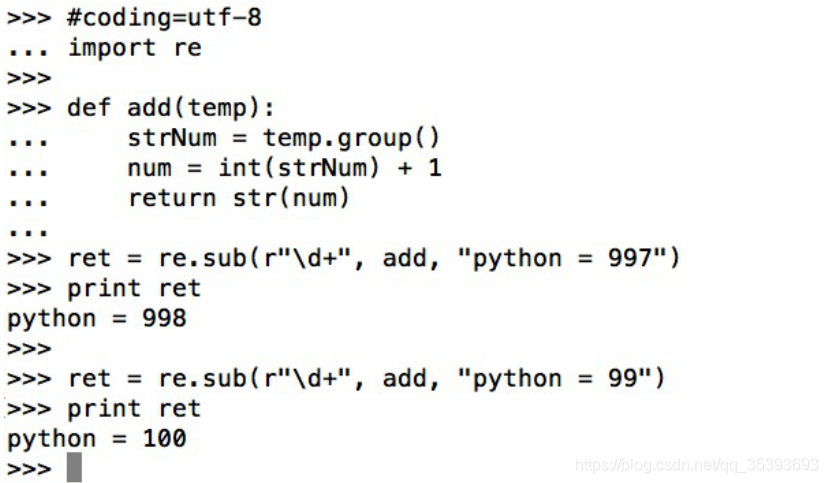
方法2:
#coding=utf-8
import re
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
ret = re.sub(r"\d+", add, "python = 997")
print ret
ret = re.sub(r"\d+", add, "python = 99")
print ret
运行结果:
split 根据匹配进行切割字符串,并返回一个列表
需求:切割字符串“info:xiaoZhang 33 shandong”
#coding=utf-8
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print ret
运行结果:
