##1.re正则表达式
特殊字符:
^:代表以该字符为开头。如^b就是b为开头。
.: 代表任意一个字符。如^b.就是b开头后面一个字母任意
*: 代表前一个字符可以出现任意次(0个也可以)。如^b.*就是b开头后面可有任意数个任意字母
$: 代表前一个字符为结尾符合。 如:.*3$就是以3为结尾的任意字符串
?:非贪婪匹配。一般情况从右往左匹配正则,?可以实现从左往右,非贪婪指遇到第一个就结束。.*?(b.*?b).*就是首先开始的b和b之间的字符串
+: 代表前面的字符至少出现一次(1个到无数个)。如b.+指b后面至少一个任意字母{2} {2,5} {2, }: 代表前面的字符出现2次。代表前面的字符出现2到5次. 代表前面字符出现2次及两次以上
|:代表或的意思 b|c,从左到右,看先匹配到那个。
(): 代表子字符串。如((a|b)123)代表group(1)为外层括号里的a123|b123;group(2)为内层括号值
[]: 代表[]内的字符满足任意一个都可以。1 ,[abcdefg]123代表以里面任意abcdefg中一个字母开头的都可以 2,[0-9] [a-z]代表可以为0-9范围内任意一个字符,代表a-z范围任意一个字符 3: [^1] ^为取反,只要不等于1就可以
注!(进入[]的字符都不再具有特殊含义[.*]就指匹配到.或者*)
\s \S: 1:\s代表匹配到一个空格。2:\S代表匹配到一个非空格
\w \W: 匹配单词字符[a-zA-Z0-9_]/非单词字符
[\u4E00-\u9FA5]: 匹配中文汉字
\d: 匹配数字
{m} {m,n}: {m}匹配前一个字符m次,{m,n}匹配前一个字符m到n次
-------------------------------------------------
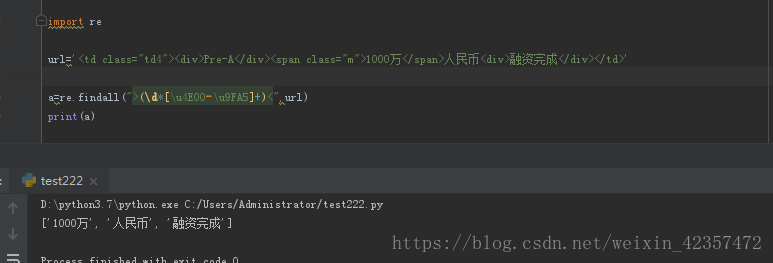
import re
url='<td class="td4"><div>Pre-A</div><span class="m">1000万</span>人民币<div>融资完成</div></td>'
a=re.findall(">(\d*[\u4E00-\u9FA5]+)<",url)
print(a)
#2.xpath解析
a.string()用法
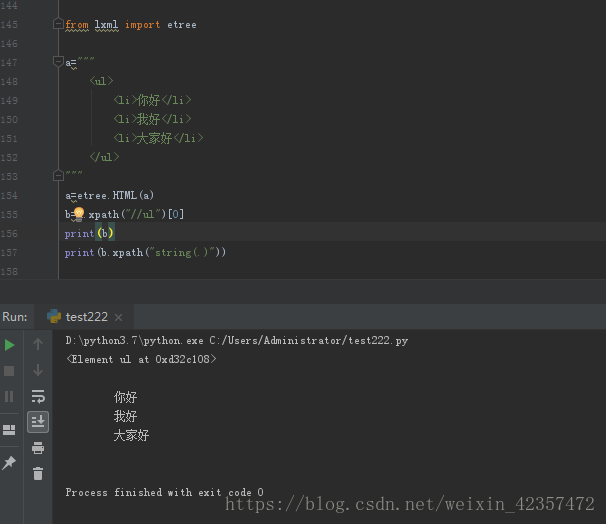
from lxml import etree
a="""
<ul>
<li>你好</li>
<li>我好</li>
<li>大家好</li>
</ul>
"""
a=etree.HTML(a)
b=a.xpath("//ul")[0]
print(b)
print(b.xpath("string(.)"))
b.contains()用法(id或者class样式有多个值时)
举例:
a.xpath('//div[contains(@class,"col-xs-10")]/a/@href')
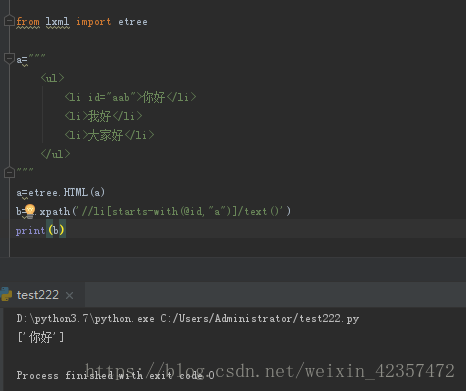
c.starts-with()用法(选取摸个属性@id@class@href以某字符数开头选取)
a="""
<ul>
<li id="acb">你好</li>
<li>我好</li>
<li>大家好</li>
</ul>
"""
a=etree.HTML(a)
b=a.xpath('//li[starts-with(@id,"ac")]/text()')
print(b)