前言
之前在用Tensorflow框架的时候,对于特征图的可视化已经研究了一下。主要的思路其实就是将特征图展开铺平成一张大图。具体文章参考Tensorboard特征图可视化。
文章主要的函数就是将特征图沿着第四通道展开,然后将其拼接。最后的返回结果 all_concact 其实还是个四维的张量,第一维是 batch_size,最后一维是 1,中间两维则是大的特征图的尺寸。
def _concact_features(self, conv_output):
"""
对特征图进行reshape拼接
:param conv_output:输入多通道的特征图
:return:
"""
num_or_size_splits = conv_output.get_shape().as_list()[-1]
each_convs = tf.split(conv_output, num_or_size_splits=num_or_size_splits, axis=3)
concact_size = int(math.sqrt(num_or_size_splits) / 1)
all_concact = None
for i in range(concact_size):
row_concact = each_convs[i * concact_size]
for j in range(concact_size - 1):
row_concact = tf.concat([row_concact, each_convs[i * concact_size + j + 1]], 1)
if i == 0:
all_concact = row_concact
else:
all_concact = tf.concat([all_concact, row_concact], 2)
return all_concact
最近在用 Keras 框架,Keras 框架使用 Tensorboard 似乎更加简单,利用 Tensorboard 这个 Callback 回调函数,自带了显示 loss 等曲线的功能。但是对于特征图、输入图片等涉及到 image 相关的,Keras 自带的 Tensorboard 并没有帮我们实现,所以需要我们自己去完善。
关于这方面的现成的资料可能有点难找,所以自己稍微摸索了一阵子,主要思路还是基于修改源码的方式进行扩展我们自己需要的功能。
主要有两个注意点:
- 利用Keras的API获取到网络中间层的输出结果时,这些只能用来定义
summary,并不是直接就获取到输出值了,想要获取到真正的输出值,需要给网络填充数据; - 我们只需要在
set_model()函数中利用tf.summary.image()之类的函数定义summary一次即可,想要更新则在on_batch_end()函数中不断的计算更新,也就是sess.run()和add_summary()。
可能表述的不是很清楚,没有用专业的词汇去表达,不能理解的可以直接看代码的实现思路,然后再回头看这两个注意点。
代码实现
下面附上自定义的 Tensorboard 源码。代码的自定义 MyTensorBoard 类的构造函数参数的含义都用注释标明,代码的主要修改在于加入了显示学习率变化的曲线和特征图的展示。
利用 self.model.layers 获取 Keras 的 model 的每一个网络层,然后遍历每一层,通过 layer.output 获取网络层的输出。利用 tf.summary.image() 将这些层的输出添加至 Tensorboard 中即可。
实现过程需要注意上述的两个注意点。其实主要就是 Keras 官方文档的那些获取网络中间层输出等等 API 都是不能直接有数据的,一定要 feed 数据才行。其实仔细想想是有道理的,Keras 只是包装了一下 Tensorflow 的计算图(网络模型),而不是帮我们都直接计算 (sess.run) 好了值。
# coding=utf-8
"""
自定义Tensorboard显示特征图
"""
from keras.callbacks import Callback
from keras import backend as K
import warnings
import math
import numpy as np
class MyTensorBoard(Callback):
"""TensorBoard basic visualizations.
log_dir: the path of the directory where to save the log
files to be parsed by TensorBoard.
write_graph: whether to visualize the graph in TensorBoard.
The log file can become quite large when
write_graph is set to True.
batch_size: size of batch of inputs to feed to the network
for histograms computation.
input_images: input data of the model, because we will use it to build feed dict to
feed the summary sess.
write_features: whether to write feature maps to visualize as
image in TensorBoard.
update_features_freq: update frequency of feature maps, the unit is batch, means
update feature maps per update_features_freq batches
update_freq: `'batch'` or `'epoch'` or integer. When using `'batch'`, writes
the losses and metrics to TensorBoard after each batch. The same
applies for `'epoch'`. If using an integer, let's say `10000`,
the callback will write the metrics and losses to TensorBoard every
10000 samples. Note that writing too frequently to TensorBoard
can slow down your training.
"""
def __init__(self, log_dir='./logs',
batch_size=64,
update_features_freq=1,
input_images=None,
write_graph=True,
write_features=False,
update_freq='epoch'):
super(MyTensorBoard, self).__init__()
global tf, projector
try:
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
except ImportError:
raise ImportError('You need the TensorFlow module installed to '
'use TensorBoard.')
if K.backend() != 'tensorflow':
if write_graph:
warnings.warn('You are not using the TensorFlow backend. '
'write_graph was set to False')
write_graph = False
if write_features:
warnings.warn('You are not using the TensorFlow backend. '
'write_features was set to False')
write_features = False
self.input_images = input_images[0]
self.log_dir = log_dir
self.merged = None
self.im_summary = []
self.lr_summary = None
self.write_graph = write_graph
self.write_features = write_features
self.batch_size = batch_size
self.update_features_freq = update_features_freq
if update_freq == 'batch':
# It is the same as writing as frequently as possible.
self.update_freq = 1
else:
self.update_freq = update_freq
self.samples_seen = 0
self.samples_seen_at_last_write = 0
def set_model(self, model):
self.model = model
if K.backend() == 'tensorflow':
self.sess = K.get_session()
if self.merged is None:
# 显示特征图
# 遍历所有的网络层
for layer in self.model.layers:
# 获取当前层的输出与名称
feature_map = layer.output
feature_map_name = layer.name.replace(':', '_')
if self.write_features and len(K.int_shape(feature_map)) == 4:
# 展开特征图并拼接成大图
flat_concat_feature_map = self._concact_features(feature_map)
# 判断展开的特征图最后通道数是否是1
shape = K.int_shape(flat_concat_feature_map)
assert len(shape) == 4 and shape[-1] == 1
# 写入tensorboard
self.im_summary.append(tf.summary.image(feature_map_name, flat_concat_feature_map, 4)) # 第三个参数为tensorboard展示几个
# 显示学习率的变化
self.lr_summary = tf.summary.scalar("learning_rate", self.model.optimizer.lr)
self.merged = tf.summary.merge_all()
if self.write_graph:
self.writer = tf.summary.FileWriter(self.log_dir, self.sess.graph)
else:
self.writer = tf.summary.FileWriter(self.log_dir)
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
if self.validation_data:
val_data = self.validation_data
tensors = (self.model.inputs +
self.model.targets +
self.model.sample_weights)
if self.model.uses_learning_phase:
tensors += [K.learning_phase()]
assert len(val_data) == len(tensors)
val_size = val_data[0].shape[0]
i = 0
while i < val_size:
step = min(self.batch_size, val_size - i)
if self.model.uses_learning_phase:
# do not slice the learning phase
batch_val = [x[i:i + step] for x in val_data[:-1]]
batch_val.append(val_data[-1])
else:
batch_val = [x[i:i + step] for x in val_data]
assert len(batch_val) == len(tensors)
feed_dict = dict(zip(tensors, batch_val))
result = self.sess.run([self.merged], feed_dict=feed_dict)
summary_str = result[0]
self.writer.add_summary(summary_str, epoch)
i += self.batch_size
if self.update_freq == 'epoch':
index = epoch
else:
index = self.samples_seen
self._write_logs(logs, index)
def _write_logs(self, logs, index):
for name, value in logs.items():
if name in ['batch', 'size']:
continue
summary = tf.Summary()
summary_value = summary.value.add()
if isinstance(value, np.ndarray):
summary_value.simple_value = value.item()
else:
summary_value.simple_value = value
summary_value.tag = name
self.writer.add_summary(summary, index)
self.writer.flush()
def on_train_end(self, _):
self.writer.close()
def on_batch_end(self, batch, logs=None):
if self.update_freq != 'epoch':
self.samples_seen += logs['size']
samples_seen_since = self.samples_seen - self.samples_seen_at_last_write
if samples_seen_since >= self.update_freq:
self._write_logs(logs, self.samples_seen)
self.samples_seen_at_last_write = self.samples_seen
# 每update_features_freq个batch刷新特征图
if batch % self.update_features_freq == 0:
# 计算summary_image
feed_dict = dict(zip(self.model.inputs, self.input_images[np.newaxis, ...]))
for i in range(len(self.im_summary)):
summary = self.sess.run(self.im_summary[i], feed_dict)
self.writer.add_summary(summary, self.samples_seen)
# 每个batch显示学习率
summary = self.sess.run(self.lr_summary, {self.model.optimizer.lr: K.eval(self.model.optimizer.lr)})
self.writer.add_summary(summary, self.samples_seen)
def _concact_features(self, conv_output):
"""
对特征图进行reshape拼接
:param conv_output:输入多通道的特征图
:return: all_concact
"""
all_concact = None
num_or_size_splits = conv_output.get_shape().as_list()[-1]
each_convs = tf.split(conv_output, num_or_size_splits=num_or_size_splits, axis=3)
if num_or_size_splits < 4:
# 对于特征图少于4通道的认为是输入,直接横向concact输出即可
concact_size = num_or_size_splits
all_concact = each_convs[0]
for i in range(concact_size - 1):
all_concact = tf.concat([all_concact, each_convs[i + 1]], 1)
else:
concact_size = int(math.sqrt(num_or_size_splits) / 1)
for i in range(concact_size):
row_concact = each_convs[i * concact_size]
for j in range(concact_size - 1):
row_concact = tf.concat([row_concact, each_convs[i * concact_size + j + 1]], 1)
if i == 0:
all_concact = row_concact
else:
all_concact = tf.concat([all_concact, row_concact], 2)
return all_concact
该自定义类基本和具体的网络无关,可以直接就用。唯一需要自己实现的部分就是传入 input_images 参数,这其实就是网络的输入数据。一般使用 Keras 框架,都会定义数据的读取函数(generate 函数),并将该读取函数传给 model.fit_generator() 中。我们仅仅需要利用 __next__ 方法(python2是 next())即可获取到一组数据传入我们自定义的 MyTensorBoard 构造函数中。
例如:
# 定义一个读取数据的generate函数
def _get_data(self, path, batch_size, normalize):
"""
Generator to be used with model.fit_generator()
:param path: .npz数据路径
:param batch_size: batch_size
:param normalize: 是否归一化
:return:
"""
while True:
files = glob.glob(os.path.join(path, '*.npz'))
np.random.shuffle(files)
for npz in files:
# Load pack into memory
archive = np.load(npz)
images = archive['images']
offsets = archive['offsets']
del archive
self._shuffle_in_unison(images, offsets)
# 切分获得batch
num_batches = int(len(offsets) / batch_size)
images = np.array_split(images, num_batches)
offsets = np.array_split(offsets, num_batches)
while offsets:
batch_images = images.pop()
batch_offsets = offsets.pop()
if normalize:
batch_images = (batch_images - 127.5) / 127.5
yield batch_images, batch_offsets
train_loader = _get_data(/path/xxx, 128, True)
MyTensorBoard(
log_dir=self.config.tb_dir,
input_images=train_loader.__next__(), # 使用__next__()获取一组数据
batch_size=self.config.batch_size,
update_features_freq=50,
write_features=True,
write_graph=True,
update_freq='batch'
)
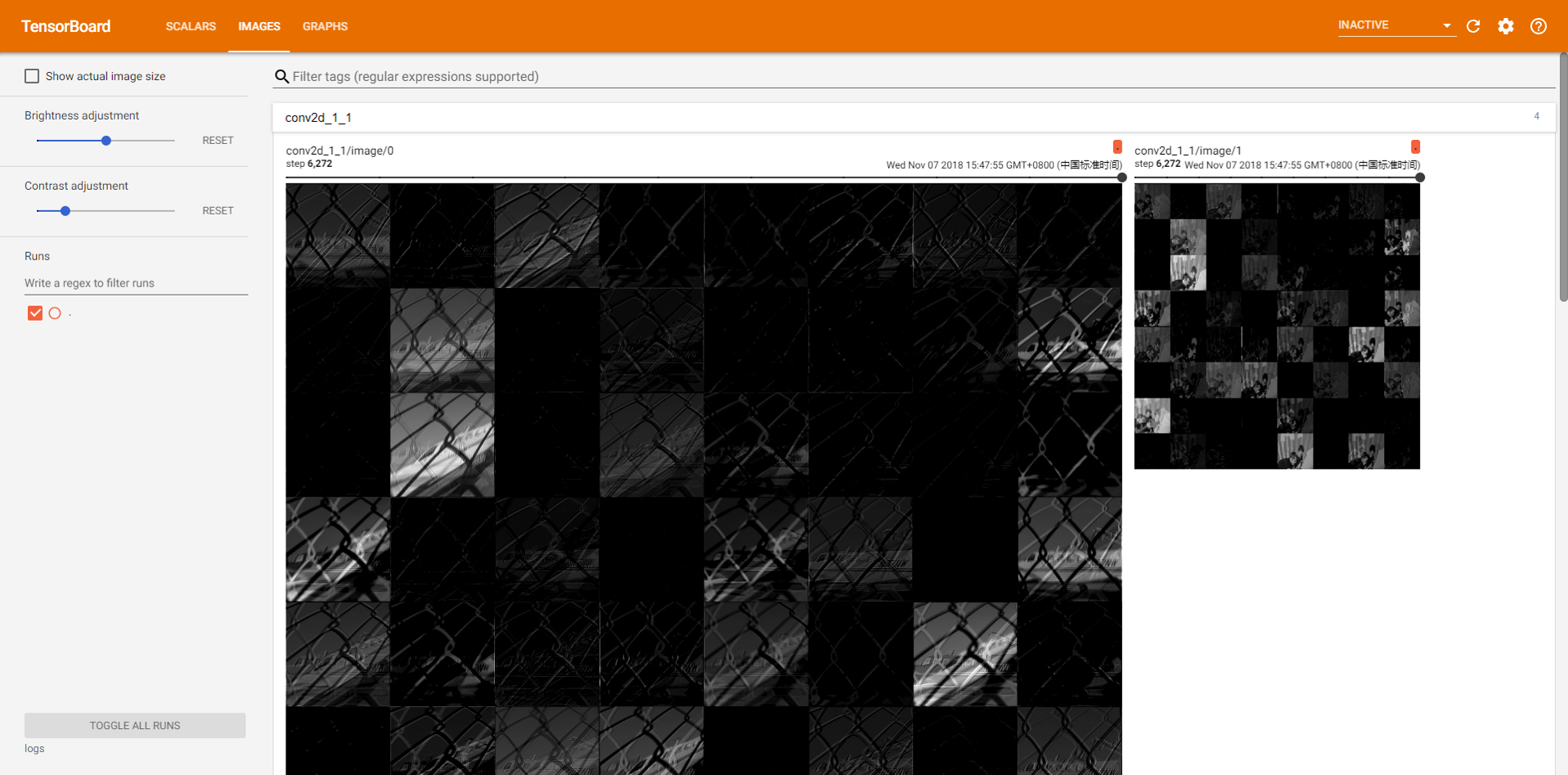
结果图
- 显示学习率变化曲线(附自定义指数下降学习率的实现代码);
class LearningRate(Callback): """ 自定义学习率调整函数 """ def __init__(self, config): super(LearningRate, self).__init__() self.base_lr = config.learning_rate self.num_total_steps = config.num_epochs * int(np.ceil(config.num_datas / float(config.batch_size))) self.step = 0 # 记录训练batch的次数 # 下降间隔 self.decay_steps = int((math.log(0.96) * self.num_total_steps) / math.log(config.min_lr * 1.0 / self.base_lr)) print("[DEBUG]: learning rate decay steps is %d ......" % self.decay_steps) def on_batch_begin(self, batch, logs=None): self.step += 1 if self.step % self.decay_steps == 0: cur_lr = self.base_lr * math.pow(0.96, self.step / self.decay_steps) K.set_value(self.model.optimizer.lr, cur_lr)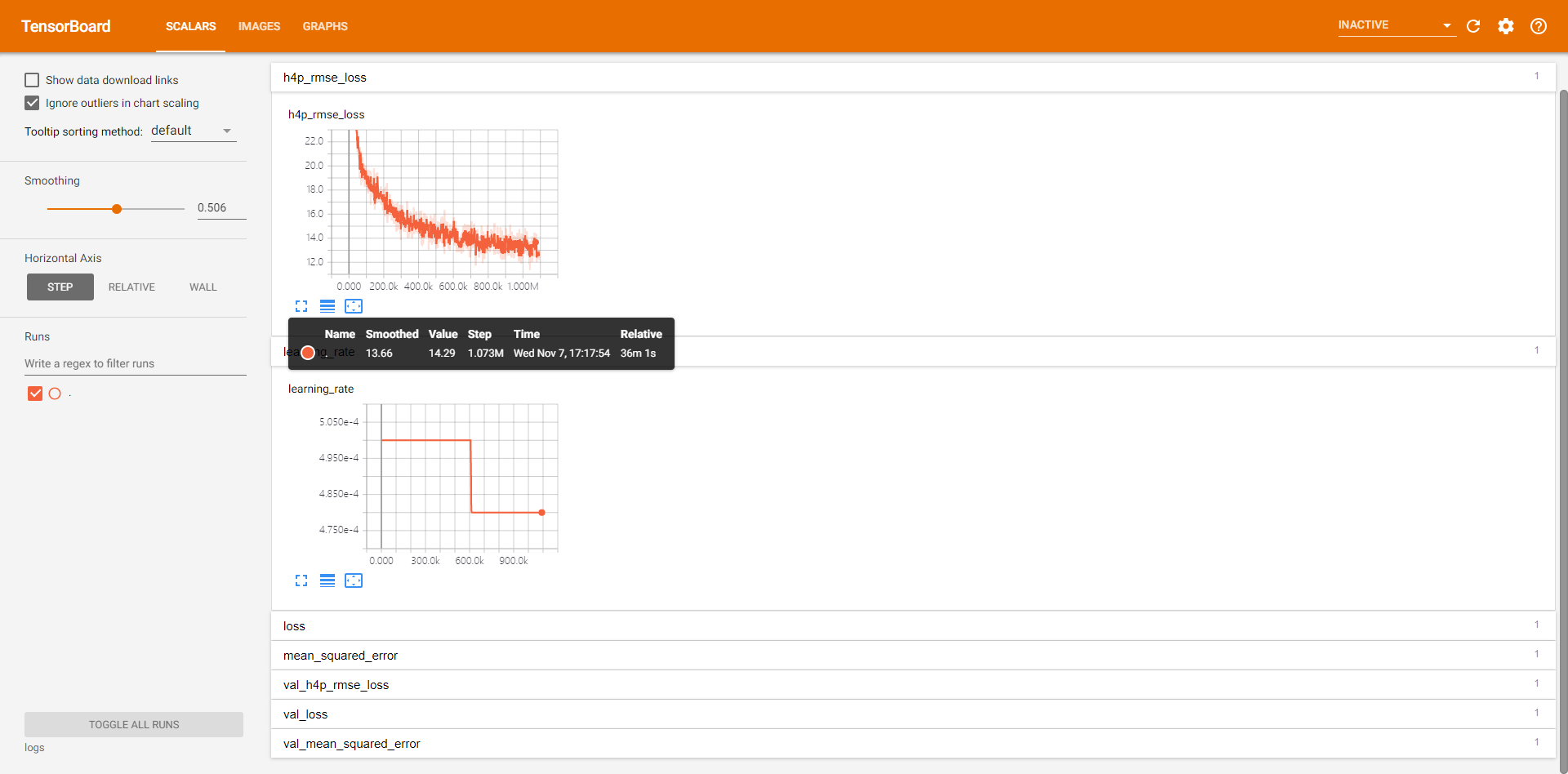
- 显示特征图。