QQ空间,这个曾经陪我们从童年到少年再到成年,从2G时代再到如今的4G末,占据了我们太多的青春回忆,如今好友空间动态更新的不在像从前那样频繁。依稀记得当年的好友买卖,抢车位再或者情侣空间,现在想想那时候真的很幼稚,那就是我们傻逼的童年,什么互踩,火星文,跑堂见证了我们无忧无虑的童年。
有时候看看QQ推送的"那年今日",看到自己好几年前发的动态,说的傻话,自己都怕了自己。有时候看到好朋友几年前的动态,不由笑骂道,这孙子,怎么这么2! 即使现在不怎么用QQ了,有时候看看曾经发的说说还有空间的留言。即使让我再尴尬也不舍得删,因为那都是青春满满的回忆。
空间留言上千条,说说也比较多,一页一页的翻比较麻烦。索性就把这些数据都下载到本地。同理我们也可以导出全部联系人的说说和留言板。
Selenium
由于访问好友留言板需要登录,为了方便起见我们使用Web应用程序测试的Selenium工具。该工具可以用于单元测试,集成测试,系统测试等等。它可以像真正的用户一样去操作浏览器等,支持Mozilla Firefox、Google Chrome、Safari、Opera、IE等等浏览器。
使用这个工具之前我们需要安装selenium库和下载相应浏览器的驱动。然后通过分析QQ空间登录界面我们发现默认是扫码登录,因此需要切换成账号密码登录。
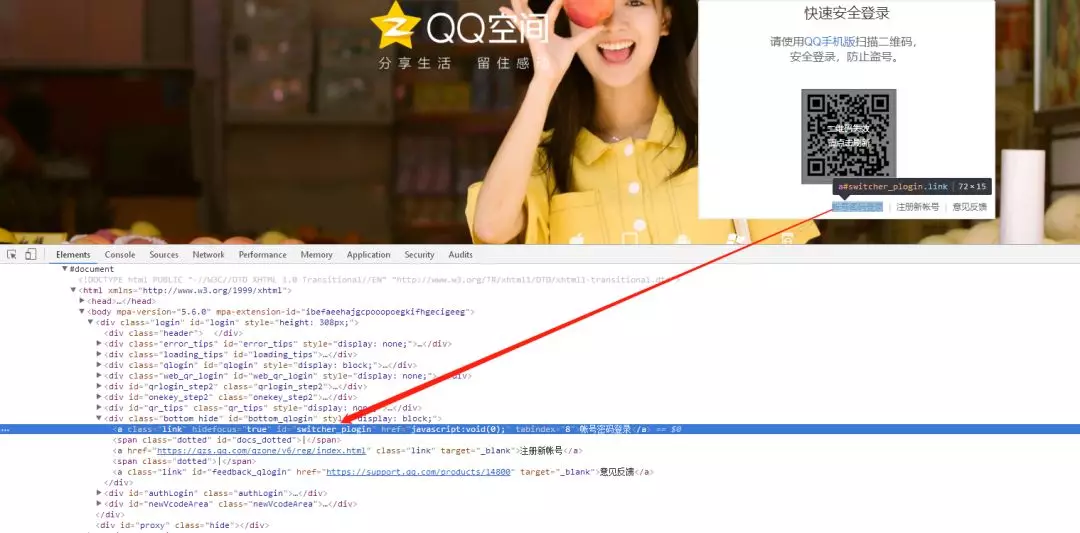
通过分析html标签属性,我们发现 id="switcher_plogin",是个切换登录的全局唯一属性。同理我们再需要找到账号、密码输入框和点击登录的元素就可以用selenium模拟登录了
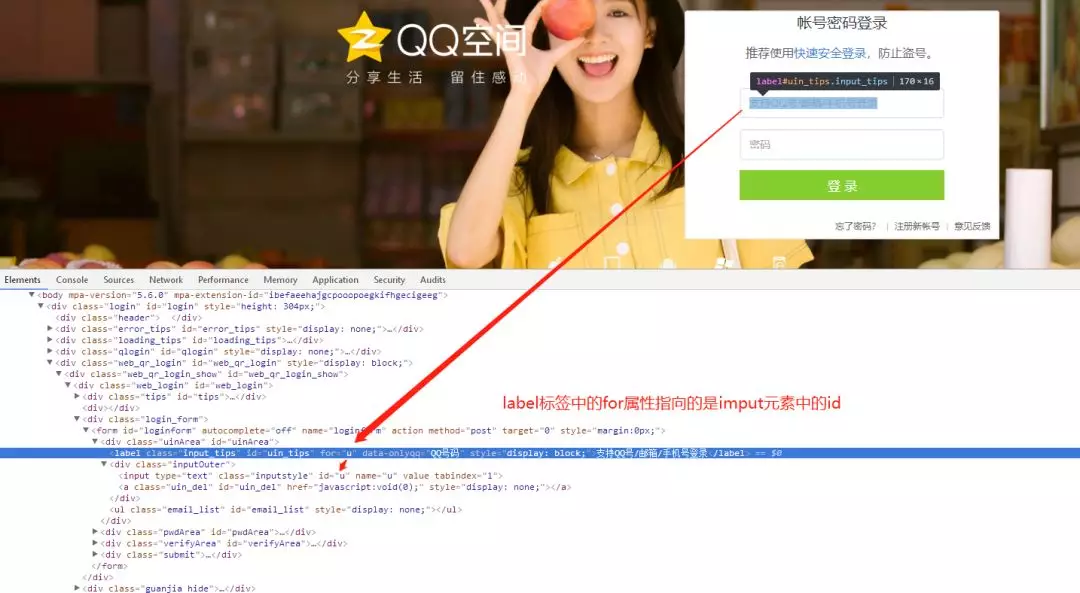
登录部分代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
# 获取谷歌浏览器驱动
driver = webdriver.Chrome()
# 登录网站
driver.get('https://i.qq.com')
# 选择账号密码登录
driver.switch_to_frame('login_frame')
# 点击输入框获取输入
driver.find_element_by_id('switcher_plogin').click()
# 输入账号
driver.find_element_by_id('u').send_keys('你的qq号')
# 输入密码
driver.find_element_by_id('p').send_keys('qq密码')
# 点击登录
driver.find_element_by_id('login_button').click()
工作前的参数准备
通过查看开发者工具中的请求我们发现,登录之后每次请求除了携带必要的参数以外,还携带了登录获取的token和g_tk。token我们可以从网页源代码中直接获取,但是g_tk在源代码中没有,根据以往经验第一步只能从js中查看,果然发现了一段加密代码,再结合上下文发现是从cookie中取出“p_skey”的值再经过一系列操作就是g_tk的值了。因为我们需要先获取cookie,然后再通过cookie获取g_tk。

部分js加密逻辑代码
if (e) { if (e.host && e.host.indexOf("qzone.qq.com") > 0) { try { t = parent.QZFL.cookie.get("p_skey") } catch(e) { t = QZFL.cookie.get("p_skey") } } ............ } "g_tk=" + QZFL.pluginsDefine.getACSRFToken(t) QZFL.pluginsDefine.getACSRFToken._DJB = function(e) { var t = 5381; for (var n = 0, r = e.length; n < r; ++n) { t += (t << 5) + e.charCodeAt(n) } return t & 2147483647 };
获取token && cookie && g_tk代码
""" 获取g_tk的值 """ def get_g_tk(cookie): hashes = 5381 for letter in cookie['p_skey']: hashes += (hashes << 5) + ord(letter) return hashes & 0x7fffffff # 获取登录之后的cookie信息 cookie = {} for elem in driver.get_cookies(): cookie[elem['name']] = elem['value'] # 获取g_tk g_tk = get_g_tk(cookie) # 利用xpath获取登录之后的网页源代码 html = driver.page_source xpath = r'window\.g_qzonetoken = \(function\(\)\{ try\{return "(.*?)";}' # 通过xpath 获得登录后的token token = re.compile(xpath).findall(html)[0]
开始搞事
破解了一个简单的反爬虫,下面就可以编写正式的爬虫代码了,首先确定我们目标url、通过浏览器分析响应的json对象、编写headers
因为每次请求都需要携带登录信息,为了方便我们用到了session类,其次观察相应我们发现返回的response有无用的字符,因此需要进行截取

headers = {
'authority': 'user.qzone.qq.com',
'method': 'GET',
'scheme': 'https',
'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
def get_resp(cookie, g_tk, token, page):
session = requests.session()
# 将cookie字典转换成RequestsCookieJar
c = requests.utils.cookiejar_from_dict(cookie)
# 将headers 放入session
session.headers = headers
# RequestsCookieJar复制给session
session.cookies = c
# 访问留言板的url
url = f'https://user.qzone.qq.com/proxy/domain/m.qzone.qq.com/cgi-bin/new/get_msgb?uin={登陆的qq}&hostUin={要查询留言内容的QQ号}&start={page}&num=10&g_tk={g_tk}&qzonetoken={token}'
print(url)
response = session.get(url)
# 截取无用的字符
resp_text = response.text[10: -3]
# 转为json
resp_json = json.loads(resp_text)
return resp_json
上面的方法,只是获得了某一页的接口相应,我们通过json获取留言总数,再除以每页的条数,就可以知道总页数了。然后再遍历去取每页的数据,为了方便查看将数据保存在csv文件中,另外将留言内容保存在txt文件中,生成词云。
def get_zone_xx(cookie, g_tk, token, page=0):
# 初始化请求为了取总条数
resp_json = get_resp(cookie, g_tk, token, page)
# 总条数
total = resp_json['data']['total']
print(f'共{total}条留言信息')
# 总页数
size = int(total/10 + 1)
# 已经读取的信息条数
use_page = 0
# 保存每条数据信息,生成csv文件用
content_arr = []
for i in range(0, size):
# 请求每一页的内容
resp_json = get_resp(cookie, g_tk, token, i)
# 当条数大于或等于总条数 跳出循环
if use_page >= total:
break
# 从每页数据中取出需要的字段值
for comment in resp_json['data']['commentList']:
use_page += 1
print(f'当前正在读取第{use_page}条')
page_json = []
# 留言日期
page_json.append(comment['pubtime'])
# 昵称
page_json.append(comment['nickname'])
# 内容
content = replace_html(comment['htmlContent'])
# 将内容写入文本 生成词云用
with open('zone_text111.txt', 'a') as f:
f.write(content)
page_json.append(content)
content_arr.append(page_json)
生成csv文件
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=content_arr,
columns=['留言日期', '昵称', '留言内容'])
df.to_csv('QQ_ZONE.csv', index=False, encoding='utf-8_sig')
print('已保存为csv文件.')
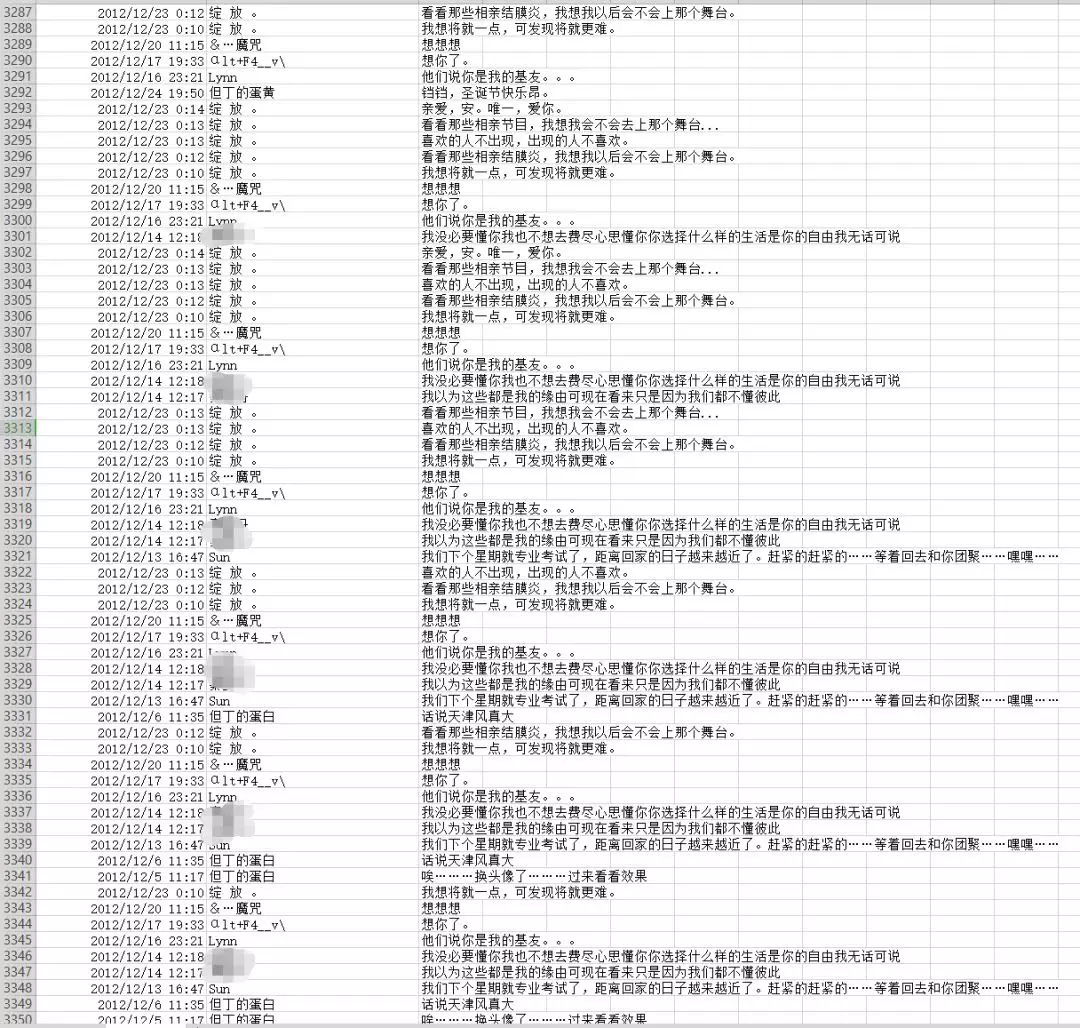
运行上面代码生成csv文件部分内容如下
生成词云(wordcloud)代码如下
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open('zone_text.txt','r') as f:
mytext = f.read()
font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(collocations=False, font_path=font, width=1400, height=1400, margin=2).generate(mytext)
plt.imshow(wc)
plt.axis("off")
plt.show()
plt.show()
运行结果如下:

写在最后
上面的代码并没有太复杂,也许是触景生情,也许是对现在朋友圈各种乱七八糟的信息产生了抵触,所以试着去回忆青春的那些往事。
朋友圈和空间并不能去衡量一个人是是否成熟,但是对于大部分90后来说,空间真的是承载了太多纯真的回忆。不忘初心,砥砺前行!!!
公众号 程序员共成长 内回复【空间】,获取源代码
本文首发于公众号 程序员共成长 公众号内回复 [礼包] 即可领取优质资源,包括但不限于Java、Python、Linux、数据库、大数据、架构、测试、前端、ui以及各方向电子书
