前言
KMP算法,我个人感觉还有是有写难度的,我想了两天才大概想明白(我想说的是,你们也可能想了好久还是想不明白,没事,别放一下,有空了就想一想,一定要一鼓作气拿下它)。其主要就是那个所谓的 next[ ] 数组的构建,而其关键又是这一步 k=next[k-1],这一步想通了就没有什么难的了。
参考文章
可以先参考一下这两篇文章,能明白了其实就不用往下看了,我这里主要是对这两篇文章的理解,把其中关键的部分做了说明。
http://blog.51cto.com/13577765/2064490 (如有侵权,请联系我删除) 这篇文章的那个模式字符串的例子举的挺好的,大家可以参考一下。在这里我也贴出来吧
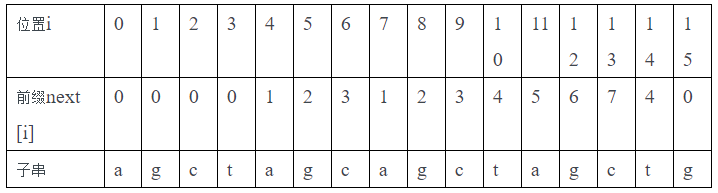
http://www.cnblogs.com/c-cloud/p/3224788.html (如有侵权,请联系我删除) 这篇文章有对KMP算法的详细解释。
先看代码在解释
写在前面
一定要理解 K 的含义和用 K-1 做下标到底意味着什么。
还有最重要的:::K=next[k-1] 其实是用到了递归的思想,一定要记住他用的是 递归 的思想,代码要是看不明白了,就回来看看这句话。
next数组的求解过程
void makeNext(const char P[],int next[])
{
int q,k;//q:模版字符串下标;k:最大前后缀长度
int m = strlen(P);
next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
{
while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k
k = next[k-1];//不理解没关系看下面的分析,这个while循环是整段代码的精髓所在,确实不好理解
if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1
{
k++;
}
next[q] = k;
}
}
对 k=next[k-1] 详解
先贴出我的手稿

字迹可能不太清楚(很难看,大家将就一下),我把它再写一遍,主要是看图,而且一定要自己动手写一写这个字符串,就会瞬间明白 k=next[k-1]。
手稿说明
在P[q]=P[k]不相等时,即产生失配后该怎么办,让K–吗?(我看到过有些文章这里写的是 K–,才会有这个提问,而且我一开始也是认为K–也可以,一开始也成功了,那是因为你找的字串很特殊造成的假象,一旦你明白了k=next[k-1]这条语句的真正含义,就会发现 K-- 所表达的含义很突兀,即不知道 K-- 要表达什么)
显然不对,而是应该重新从P[0]开始找,再找到一个适配点(而且要保证适配后K值尽量最大),而以K=next[k-1]为下标的下一个元素就是刚好要找的,即第一个 {} 后面的 t ,而为了简化这里就找了一次就找了也有助于大家的理解。
重要的事情
一定要亲自动手写写这个字符串,动笔哗啦哗啦,看看这个K值是怎么变化的,别老盯着代码看,看不出花来。一旦动手写,很容易明白的。
具体的完整代码这里就不贴了,这里只介绍最难理解的 next 数组的构建,想看完整代码的,你们可以看靠我给出的第二个链接。
结语
有些不对或者不太清楚的地方,欢迎大家指正,及时修改,以免误导了别人。很感谢上面两篇文章的作者,让我明白了这个算法,真的感谢。后续会把完整代码补全,可能后面还会写一个KMP的优化算法。