基于比较的排序算法的时间复杂度下限是O(nlogn),本文介绍另外一种整数排序算法——计数排序。计数排序是一种非比较排序稳定排序算法,它的运行效率为O(n+m),正比于数值范围大小(n),设待排序元素个数(m),所以它只适用于n相对于m不是特别大的情况,当m>>n时尤其适合。当然对于负整数或小数以及字符排序可以进行适当的预处理将原来待排序元素映射成自然数即可。
下面看算法:
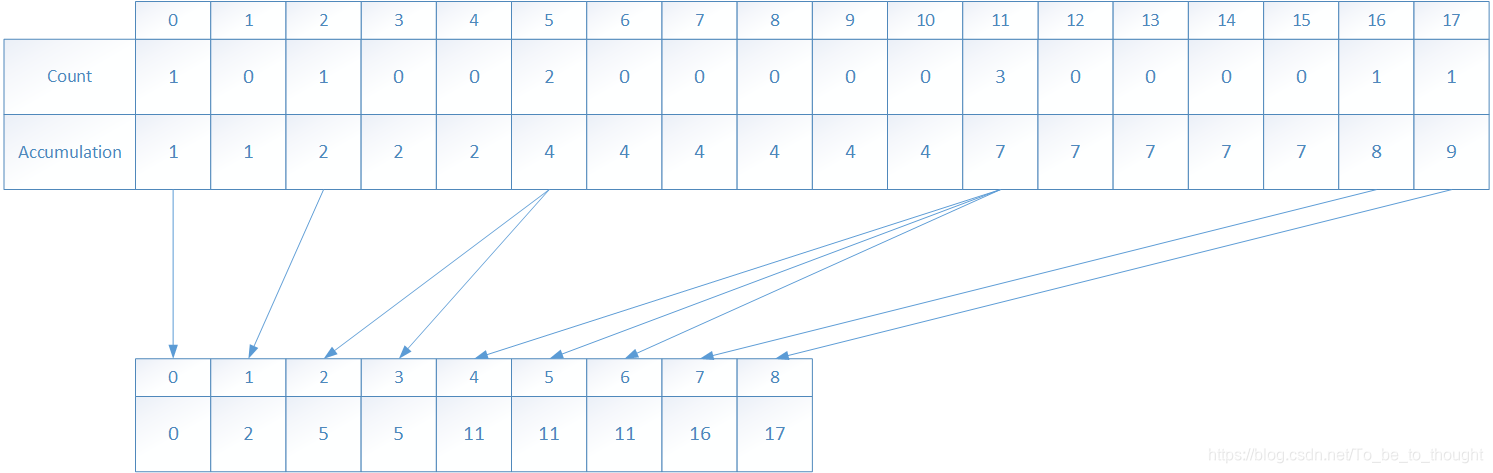
待排序元素数组长度为9:


步骤一:计算数组值的范围,确定计数数组count的长度,计数数组的长度len=max-min+1
步骤二:遍历原数组,填写计数数组,原数组的元素arr[i]每出现一次,以arr[i]为索引的count数组的元素加1
步骤三:遍历计数数组,计算累积频次,这个累积频次将对应于计数数组索引(即待排序元素)在排序后数组中的索引位置。累积频次(累积计数数组元素)的意义:累积频次(也就是该元素)总比该元素索引在排序数组中的索引位置大1,即表示原数组中小于等于索引值的元素数目为“累积频次”次。
步骤四:依据计数数组的元素值逆序填写待排序数组,累积计数数组的元素值-1就是元素索引在排序数组中的位置,将该元素放到正确位置后累积计数数组的元素值要自减1,以便当同一元素再次出现时可以填到正确的空位上去。
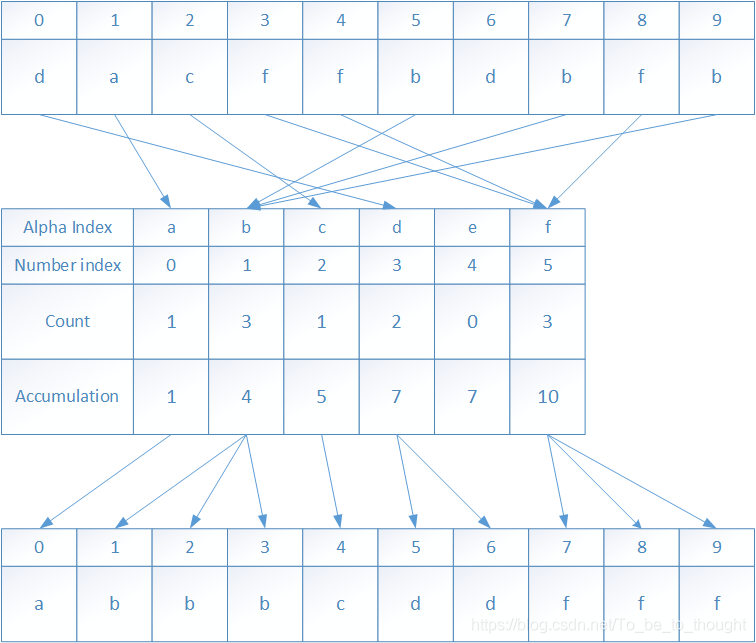
再来看一个《算法》第四版上字符排序的例子,字符串“dacffbdbfb”:

这个例子就不展开讲了,主要是排序前先要进行字符到数字的映射,因为字符串自身就有加减功能,所以这个映射不需要专门的函数:
下面上python代码:
def counting_sort(collection):
if collection == []:
return []
coll_len = len(collection)
coll_max = max(collection)
coll_min = min(collection)
counting_arr_length = coll_max + 1 - coll_min
counting_arr = [0] * counting_arr_length
for number in collection:
counting_arr[number - coll_min] += 1
for i in range(1, counting_arr_length):
counting_arr[i] = counting_arr[i] + counting_arr[i-1]
ordered = [0] * coll_len
for i in reversed(range(0, coll_len)):
ordered[counting_arr[collection[i] - coll_min]-1] = collection[i]
counting_arr[collection[i] - coll_min] -= 1
return ordered测试运行:

