zookeeper安装和使用 windows环境
2016年07月25日 22:27:02 tlk20071 阅读数:93471 标签: zookeeper 分布式应用 更多
个人分类: zookeeper
简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3.4.8\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
下载
Apache官方最新版本为:3.4.8
下载地址:http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
安装
解压到指定目录下 D:\soft\zookeeper-3.4.8
修改zoo_sample.cfg 文件名(D:\soft\zookeeper-3.4.8\conf) 为 zoo.cfg
主要修改一下日志位置,具体配置文件如下:
-
# The number of milliseconds of each tick -
tickTime=2000 -
# The number of ticks that the initial -
# synchronization phase can take -
initLimit=10 -
# The number of ticks that can pass between -
# sending a request and getting an acknowledgement -
syncLimit=5 -
# the directory where the snapshot is stored. -
# do not use /tmp for storage, /tmp here is just -
# example sakes. -
dataDir=D:\\zookeeper\\data -
dataLogDir=D:\\zookeeper\\log -
# the port at which the clients will connect -
clientPort=2181 -
# the maximum number of client connections. -
# increase this if you need to handle more clients -
#maxClientCnxns=60 -
# -
# Be sure to read the maintenance section of the -
# administrator guide before turning on autopurge. -
# -
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance -
# -
# The number of snapshots to retain in dataDir -
#autopurge.snapRetainCount=3 -
# Purge task interval in hours -
# Set to "0" to disable auto purge feature -
#autopurge.purgeInterval=1
配置文件简单解析
1、tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2、dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
3、dataLogDir:顾名思义就是 Zookeeper 保存日志文件的目录
4、clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
启动
进入到bin目录,并且启动zkServer.cmd,这个脚本中会启动一个java进程

启动后jps可以看到QuorumPeerMain的进程

也可以启动客户端连接一下

OK,安装成功,很简单
zookeeper集群搭建(windows环境下)
本次zk测试部署版本为3.4.6版本,下载地址http://mirrors.cnnic.cn/apache/zookeeper/
限于服务器个数有限本次测试了两种情况
1、单节点方式:部署在一台服务器上
2、单IP多节点(伪集群):部署在同一IP,但是有多个节点,各有自己的端口
3、多IP多节点:部署在不同IP,各有自己的端口(未测试)
一、单节点方式:
1、解压zk包,进入zookeeper-3.4.6\conf目录,修改zoo_sample.cfg文件为zoo.cfg.如果没有特殊需求,不需要修改配置文件,直接使用默认配置文件即可.
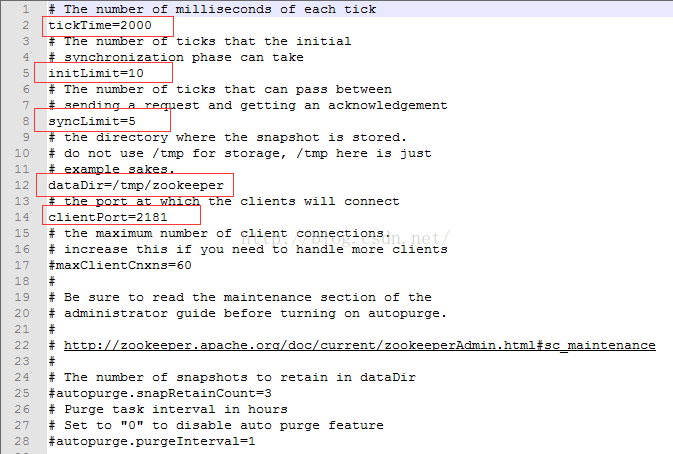
各个参数的意义:
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。 clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。 initLimit:集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量) syncLimit:集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
启动zookeeper,windows下执行zookeeper-3.4.6\bin >zkServer.cmd;linux下ookeeper-3.4.6\bin >zkServer.sh start启动
查看是否成功运行:bin/zkServer.cmd status
二、单IP多节点
(1)修改配置文件:拷贝多份zookeeper程序,例如设置三个server,分别创建目录server1、server2、server3,每个目录下存放一份zookeeper程序,并修改各自配置文件如下:
server1
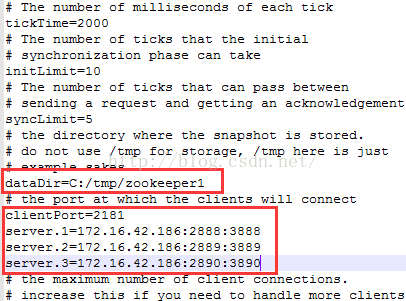
server2配置:
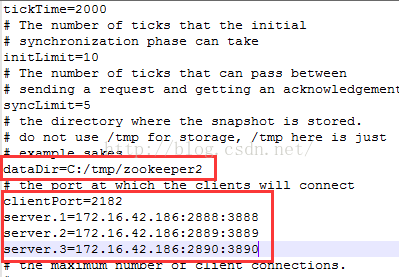
server3配置:
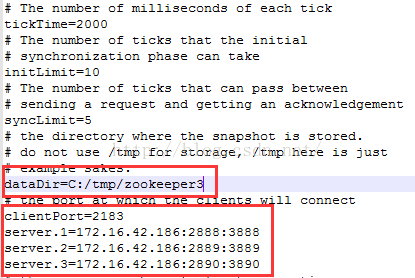
注意:
同一IP上搭建多个节点的集群时,必须要注意端口问题,端口必须不一致才行;
创建多个节点集群时,在dataDir目录下必须创建myid文件,myid文件用于zookeeper验证server序号等,myid文件只有一行,并且为当前server的序号,例如server.1的myid就是1,server2的myid就是2等。
server.A=B:C:D;其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
启动过程:启动顺序为server1、server2、server3。在启动server1,server2时zk会报错,当所有节点全部启动时错误会消失。
三、
多IP多节点:
将zookeeper拷贝到每个节点一份。
多IP多节点与单IP多节点搭建过程基本一致,上述过程不再重复描述,仅重点说一个地方:server的IP地址、端口为真实即可。
注意:zk的部署个数最好为基数,ZK集群的机制是只要超过半数的节点OK,集群就能正常提供服务。只有ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
分类: Apache