目录
归纳和演绎
“归纳”和“演绎”是科学推理的两大基本手段
“归纳”是从特殊到一般,是一个“泛化”过程,是总结经验,比如猫有哪些特点?
“演绎” 就是从一般到特殊,从基本情况推出具体情况,是“特化”过程
从“样本”中学习过程 称为“归纳学习”
归纳学习分为广义和狭义:
- 广义的归纳学习大体相当于从样例中学习
- 狭义的归纳学习要求从训练数据中得到概念。(“概念”是一种存在的我们可能未知的事实。)
概念学习、概念形成最基本的是布尔概念学习:
布尔值就是0和1,表示“是”或者“不是”

假设我们有一个数据集,用来训练算法。通过 “ 色泽+跟蒂+敲声” 来判断这个瓜是否是好瓜。
计算机拿到这组数据集时,首先是直接记录了这4个情况,等于只要和 这4种情况一样,我们就可以直接判断瓜的好坏。
但是训练是从特殊到一般的过程,目的是“泛化”,能根据数据集训练得到未知的结果,从而对瓜好坏进行判断。
学习过程:在假设组成的空间中进行搜索,搜索目标与训练进行“匹配”,从而能够进行判断。
以这个西瓜集为例子,形成的假设空间为:

假设空间相当于是对数据集的全组合,对未知的情况也进行组合,以便得到更加普遍“泛化” 的结果。
现实生活中,假设空间都很大,而训练样本有限, 因此可能存在一个 与训练集一致的“假设集合”,我们称为“版本空间”
表1对应的版本空间为:
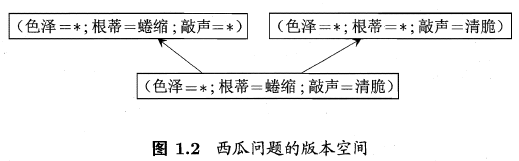
解答疑问
1.假设空间得到的结果一定是全组合吗?
全组合是基于你给的数据集属性决定的,比如,现在给你一个黄颜色的芯的西瓜,那就不在这个假设空间中。
2.假设空间还不是 很明白,能不能简单描述?
假设空间就是基于数据集形成的所有情况的假设集合,对每种情况根据数据集分析得到概率情况,以便后期对未知情况进行判断