一、使用UUID生成
1.定义
UUID是一个128位长的数字,一般用16进制表示。算法的核心思想是结合机器的网卡、当地时间、一个随即数来生成GUID。从理论上讲,如果一台机器每秒产生10000000个GUID,则可以保证(概率意义上)3240年不重复。
2.用法
在java使用UUID非常简单,在jdk的工具类中已经有生成UUID的类可以直接使用,如下:
代码实例:

运行结果:
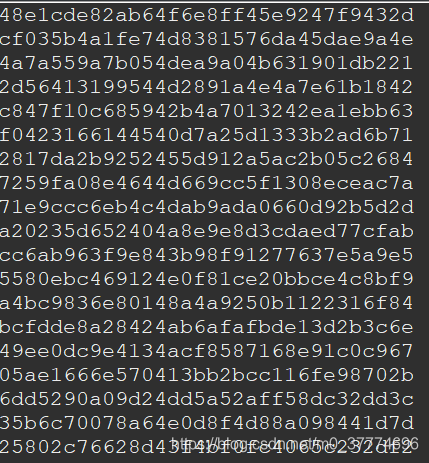
可以看出在单机环境下,生成的uuid不会重复
3.优缺点
| 优点 | 缺点 |
|---|---|
| 使用简单 | 数据库索引效率低(这里针对mysql的b+树索引而言) |
| 不依赖其他组件,直接是使用jdk工具类 | 太长无意义,用户不友好 |
| 不影响数据库的拓展 | 空间占用大 |
| 在应用集群环境,机器多的时候,重复几率很大!!! |
二、使用数据库自增序列生成
1.定义
利用数据库,全数据库唯一。
2.用法
设置mysql数据库自增长起始值以及步长,多个不同数据库应设置不同起始值,而步长设置一致,则每个数据库生成的自增序列码可以避免相同。
以一个数据库中设置为例:
代码:
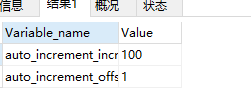
SHOW VARIABLES like 'auto_inc%';//查看自增相关变量值
set auto_increment_increment=100;//设置步长
set auto_increment_offset=1;//设置起始值
INSERT into `user`VALUES(null);//模拟插入数据
结果运行图:
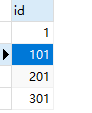
3.优缺点
| 优点 | 缺点 |
|---|---|
| 开发人员无需编码 | 大表不能做水平拓展,否则插入或删除容易出现问题 |
| 性能过得去 | 依赖前期的规划,拓展麻烦 |
| 索引友好(针对mysql中b+树) | 依赖mysql内部维护的“自增锁”,高并发下插入数据影响性能 |
| 在业务操作父子关联表(ER表)插入时,必须先父后子 |
三、推特的雪花算法(snowflake)
1.定义
推特公司使用的一款通过划分命名空间并行生成的算法,来解决全局唯一ID的需求,类似的还有MongoDB的object_id。雪花算法,是64位二进制,转换十进制,不超过20位。第一位是符号位,一般是不变的0,第二阶梯的是41位的毫秒,第三阶梯是10位的机器ID,第四阶梯是12位的序列号,雪花算法能保证一毫秒内,支持1024*4096个并发,400多W了,对付绝大多数场景,都适用了。业界使用一般根据雪花算法做拓展。
2.用法
snowflake 使用java实现源码:
package com.jd.qztest;
/**
* twitter的snowflake算法 -- java实现
*
* @author rock
* @date 2016/11/26
*/
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
}
使用java模拟一百个线程调用雪花算法生成方法:
package com.jd.qztest;
import java.util.concurrent.CountDownLatch;
public class Main1 {
private static int threadNum=100;
private static CountDownLatch countDownLatch=new CountDownLatch(threadNum);
public static void main(String [] args) {
SnowFlake flake=new SnowFlake(2,3);
for (int i=0;i<threadNum;i++){
new IdThread(flake).start();
countDownLatch.countDown();
}
}
static class IdThread extends Thread{
private SnowFlake flake;
public IdThread(SnowFlake flake){
this.flake=flake;
}
@Override
public void run(){
try {
countDownLatch.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(flake.nextId());
}
}
}
运行结果:
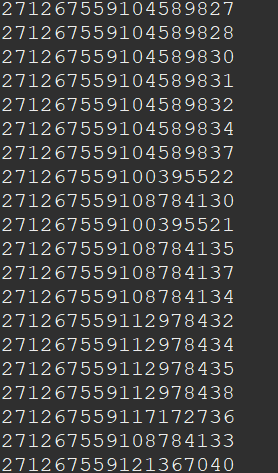
3.优缺点
| 优点 | 缺点 |
|---|---|
| 性能较好,速度快 | 依赖机器时间,如果发生时间会把,则可能产生id重复 |
| 无需第三方依赖,实现比较简单 | |
| 可以根据实际情况调整和拓展雪花是短发,方便灵活 |
四、基于redis的自增
1.定义
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
在实际公司开发项目中,我们一般将redis的命名为:系统名:模块名:功能名
2.用法
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,负载到哪个机要先确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
单机使用redis自增特性运行截图:
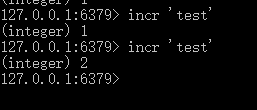
3.优缺点
| 优点 | 缺点 |
|---|---|
| 拓展性强,可以方便地结合业务进行处理 | 增加一次网络开销 |
| 利用redis的单纤成操作的原子性,保证高并发下不会重复 | 引入redis第三方依赖库 |
| 需要做reids高并发支持 |
五、说在最后
技术选型并无绝对,针对以上的分布式订单号生成常用的四种策略,我们应该根据自己业务场景去选择合适的策略。