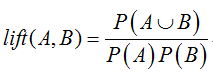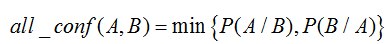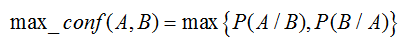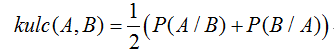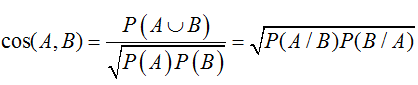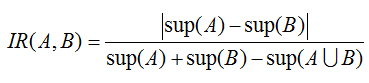1、基本概念
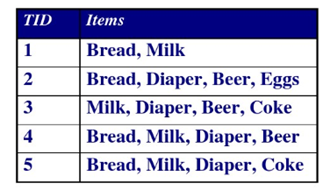
下图为5次交易的数据,每行代表一个事务,每个事务包好几个项。数据内隐含着内在关联。
事务:由事务号和项集组成。事务是一次购买行为
项:最小处理单位,即购买的物品
项集:由一个或多个项组成
支持度计数:包含某个项集的事务数
支持度:包含某个项集的事务数的比例
置信度:在所有包含X项集的事务中包含Y项集事务的比例
频繁项集:支持度不小于指定阈值的项集
关联规则:X和Y都是项集,X->Y(s,c)
关联规则评估指标:支持度不小于指定阈值和置信度不小于指定阈值
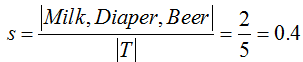
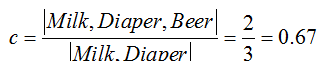
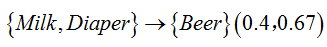
2、频繁项集挖掘算法
2.1 Apriori算法
算法核心思想
如果一个集合是频繁项集,则它的所有子集都是频繁项集;如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
算法流程
1)找到频繁的一维项集L1
2)从频繁的Lk维项集生成k+1维项集Ck+1
3)找到Ck+1中的频繁项集Lk+1
4)k=k+1,循环执行2)-3)直至k+1=n,n为最大项集
5)输出各个维度的频繁项集
从Lk生成Ck+1的方法,k>1
算法示例
2.2 FP—Growth算法
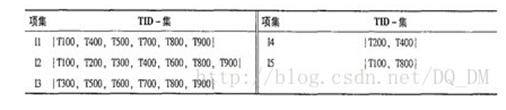
FP—Growth算法的数据格式是垂直数据格式:
算法流程
1)找到频繁的一维项集L1
2)从频繁的Lk维项集生成k+1维项集Ck+1
3)通过取频繁k项集的TID集的交,计算对应的(k+1)项集的TID集
4)k=k+1,循环执行2)-3)直至不能再找到频繁项集或候选项集
5)输出各个维度的频繁项集



3、相关性度量
3.1 度量指标
给定两个项集A和B
兴趣度/提升度:
提升度小于1为负相关;提升度大于1为正相关;提升度等于1为不相关。
下述四个指标的取值范围是[0,1],0表示不相关,1表示相关,0.5表示中性
全置信度
最大置信度
Kulc度量
余弦度量
3.2 度量指标对比
度量零不变
一种度量,如果它的值不受零事务的影响,则它是度量零不变的
对于数据集D3,4个新度量都正确地表示m和c是强负相关的。提升度和卡方都错误地与此相悖。
对于数据集D4,提升度和卡方都显示了m和c之间强正关联,而其他度量都表示“中性关联”。上述的例子中。非mc表示零事务的个数。提升度和卡方很难识别有趣的模式关联关系,因为它们受非mc的影响很大。另一方面,其他4个度量的定义都消除了非mc的影响上面的6种,只有提升度和卡方不是零不变度量。
不平衡比
不平衡比评估规则蕴含式中两个项集A和B的不平衡程度
两者之差越大,不平衡比就越大。数据集D5和D6,全置信度和余弦度把两者都视为负关联的,最大置信度度量把两者都视为强正关联的,而Kluc度量把两者都视为中性的。对于这种不平衡,把它看作是中性的可能更公平,同时用不平衡比(IR)指出它的倾斜性。