版权声明:未经本人许可,不得用于商业用途及传统媒体。转载请注明出处! https://blog.csdn.net/qikaihuting/article/details/84950947
GAN损失函数
- 对抗网络中生成器的目的是尽可能使生成样本分布拟合真实样本分布。
- 鉴别器目的是尽可能鉴别输入样本来自于真实的还是生成的。
- 大家都知道GAN的优化目标函数如下:
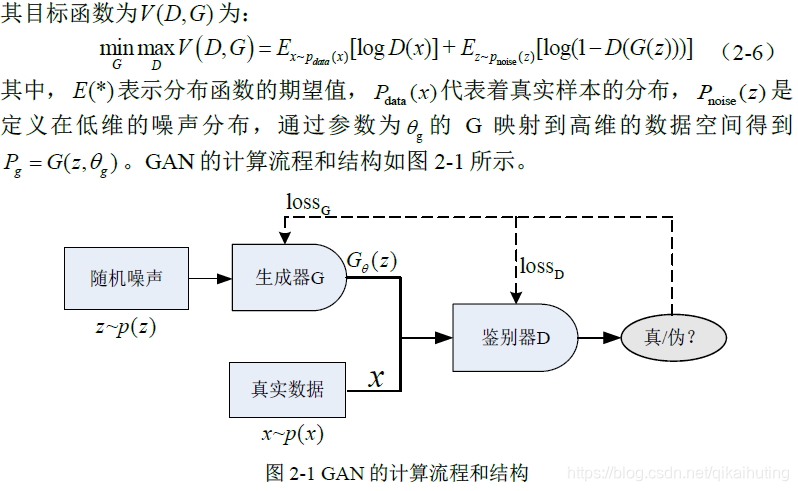
- 但其参数到底是如何优化的呢?答案是交替迭代优化;如下图所示:
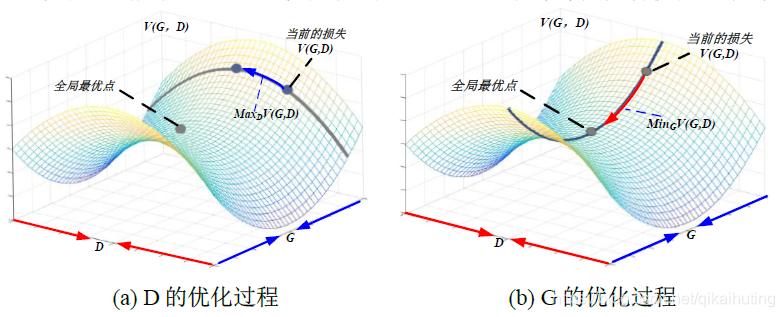
- 图(a):固定G参数不变,优化D的参数,即最大化
等价于
。因此,D的损失函数等价如下:
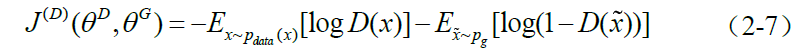
- 鉴别器认为来自真实数据样本的标签为1而来自生成样本的标签为0。因此,其优化过程是类似Sigmoid 的二分类,即sigmoid的交叉熵。
- Tensorflow中的交叉熵是用
tf.nn.sigmoid_entropy_with_logits(logits,labels)表示。 - 我们可以通过查看TF的sigmoid交叉熵API理解:
- 当
x = logits表示最后输出特征,z = labels表示对应的标签. The logistic loss is . - 推导如下:
当x<0,可进一步化简为:
- The logistic loss formula from above is
x - x * z + log(1 + exp(-x)) - For x < 0, a more numerically stable formula is
-x * z + log(1 + exp(x)) - Note that these two expressions can be combined into the following:
max(x, 0) - x * z + log(1 + exp(-abs(x)))
- 当
- 当
z=1时,真实样本对应的损失为: . - 当
z=0时,生成样本对应的损失为: .其中 .

- 由于JS散度具有非负性,当两者分布相等时,其散度为零。因此,D(x)训练得越好,G(z)就越接近最优,则生成器的损失越接近于生成样本分布和真实样本分布的JS 散度。
- 图(a):固定G参数不变,优化D的参数,即最大化
等价于
。因此,D的损失函数等价如下:
- GAN网络算法流程如下表:

- 实际上,式(2-6)可能并没有提供足够的梯度来更新G 的参数。训练初期, 由于G 没有得到较好的训练,生成样本很差,D 会以高置信度的概率来拒绝初期生成的样本,导致log(1−D(G(z)))达到饱和,无法提供足够的梯度来更新 G。于是,采用最大化log(D(G(z)))来代替最小化log(1−D(G(z)))更新 G的参数。
- tensorflow框架下的GAN的损失代码如下:
# the first term of discriminator loss of real sample:-log[D(x)]
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_entropy_with_logits(logits=D_real_logits,labels=tf.ones_like(D));
# the second term of discriminator loss of fake sample:-log[1-D(G(z))]
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_entropy_with_logits(logits=D_fake_logits,labels=tf.zeros_like(D));
# D_fake_logits是鉴别器对生成器生成样本提取的特征 D(G(z))
d_loss = d_loss_real + d_loss_fake ;
# -log[D(G(z))]
g_loss = tf.reduce_mean(tf.nn.sigmoid_entropy_with_logits(logits=D_fake_logits,labels=tf.ones_like(D));
D表示对应维度大小为batchsize的标签