我们知道tensorflow是一个深度学习框架,用计算图(graph) 表示计算任务,用张量(tensor) 表示和传递数据,在会话(session) 中执行计算任务。我们要学习和使用tensorflow,就需要知道如何读取tensorflow数据。经常看实例代码,我们会发现有的是先定义变量占位,然后再通过feed_dict喂入数据,有的则没有,现在就来整理一下有哪些方式。
数据读取
- 预取数据(Preloaded data)
- 供给数据(Feeding)
- 从文件读取(Reading from file)
预加载数据
在TensorFlow图中定义常量或变量来保存所有数据。这种方式一般只适用于数据量比较小的情况,因为预加载数据量大的时候会占用大量内存。通常有两种方法:
1.存储在常数中;
2. 存储在变量中,初始化后,值则不可改变。
示例:
import tensorflow as tf
# 定义一个图graph
x1 = tf.constant([1, 2, 3])
x2 = tf.constant([2, 3, 4])
y = tf.add(x1, x2)
# 打开一个会话session 来执行计算y
with tf.Session() as sess:
print sess.run(y)
供给数据
在TensorFlow程序运行的每一步, 让Python代码来供给数据。可用代码产生数据也可以用代码读取数据来实现供给。TensorFlow的数据供给机制允许你在TensorFlow运算图中将数据注入到任一张量中,因此python运算可以把数据直接设置到TensorFlow图中。
这种方式下,一般是先定义占位符,然后通过run()或者eval()函数的feed_dict参数把数据喂入网络。
示例:
import tensorflow as tf
# 定义一个图graph
x1 = tf.placeholder(tf.int32)
x2 = tf.placeholder(tf.int32)
y = tf.add(x1, x2)
# python代码生成数据
a = [1,2, 3]
b = [2,3,4]
# 打开一个会话session 来执行计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: a, x2: b})
从文件读取
在TensorFlow图的起始, 让一个输入管线从文件中读取数据。一般是创建一个**队列(queue)**可以用tf.train.slice_input_producer()方法,然后把数据(一般会把数据类型进行转换,用tf.cast()函数)加载到队列中去,之后再分别获得数据内容(一般需要一个解码内容的过程,如tf.image.decode_jpeg()方法)和标签内容,最后再通过tf.train.shuffle_batch()生成batch化的数据。
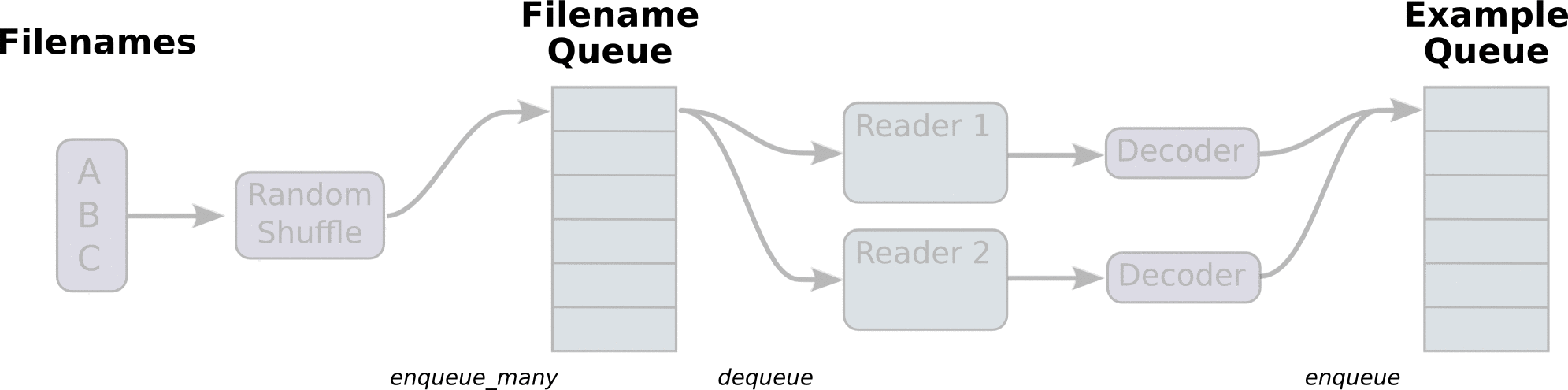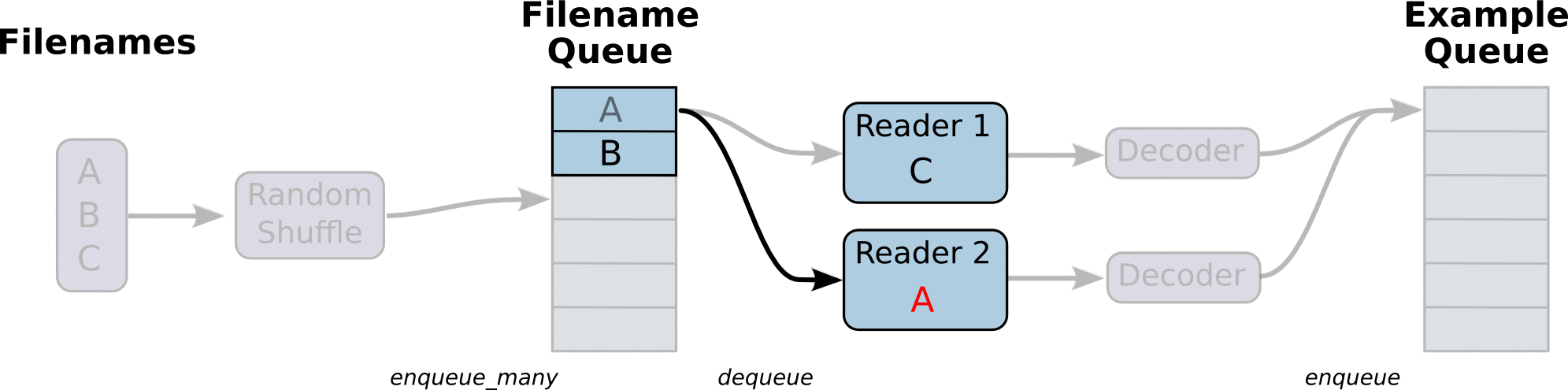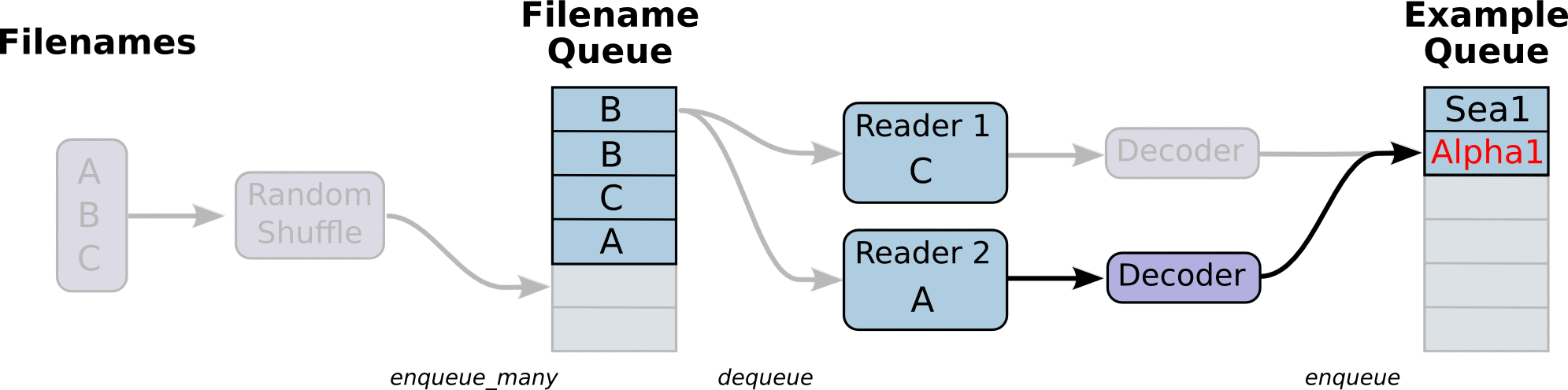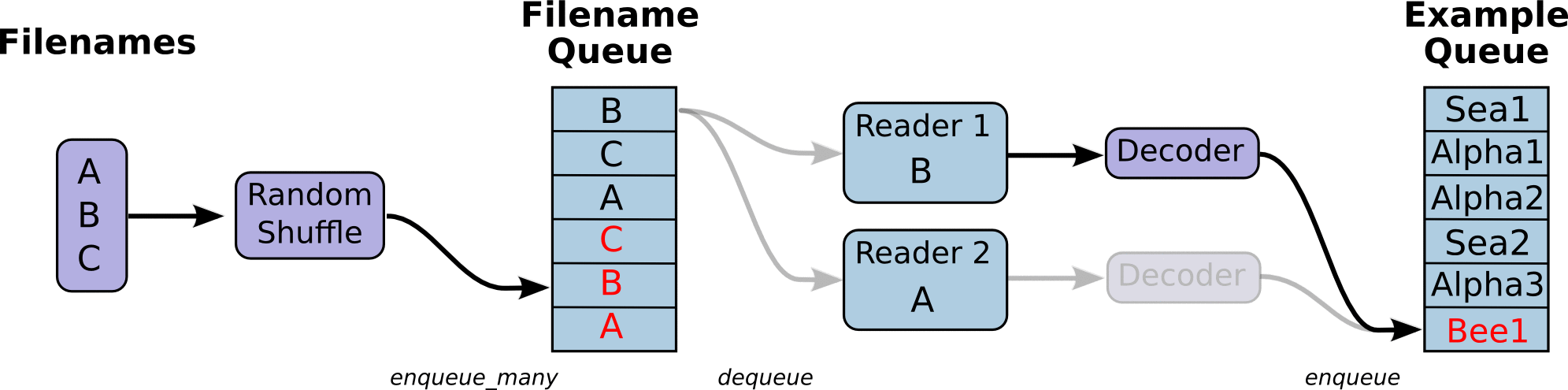
示例:
def get_batch(image, label, image_W, image_H, batch_size, capacity):
# step1:转换类型,产生一个输入队列queue
image = tf.cast(image, tf.string) # 可变长度的字节数组.每一个张量元素都是一个字节数组
label = tf.cast(label, tf.int32)
# tf.train.slice_input_producer是一个tensor生成器
input_queue = tf.train.slice_input_producer([image, label])
label = input_queue[1]
image_contents = tf.read_file(input_queue[0]) # tf.read_file()从队列中读取图像
# step2:将图像解码,获取图像内容
image = tf.image.decode_jpeg(image_contents, channels=3)
# jpeg或者jpg格式都用decode_jpeg函数,其他格式可以去查看官方文档
# step3:数据预处理,对图像进行旋转、缩放、裁剪、归一化等操作
image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H)
# 对resize后的图片进行标准化处理
image = tf.image.per_image_standardization(image)
# step4:生成batch化的数据
image_batch, label_batch = tf.train.batch([image, label],
batch_size=batch_size,
num_threads=16,
capacity=capacity)
# 重新排列label,行数为[batch_size]
label_batch = tf.reshape(label_batch, [batch_size])
image_batch = tf.cast(image_batch, tf.float32) # 显示灰度图
return image_batch, label_batch
以上内容只是根据个人理解整理,如有异议还望提出来一起交流。
参考来源:http://www.tensorfly.cn/tfdoc/how_tos/reading_data.html