到目前为止我们已经搭建起来一套CouchBase集群,并且可以通过界面进行基本的操作。从这一节开始,主要是讲解CouchBase的架构原理。我一直觉得学习开源软件不是学习这套软件怎么安装配置和使用,更重要的是要学习到软件的原理,架构和代码实现。尤其是自定而下,从设计原则,指导思想到具体的架构,组件功能划分,最后到代码的具体实现。
如果只是了解CouchBase的安装配置方法,实在是有点太过于浅薄。
互联网行业实在飞速发展的,各种性能一代强过一代的开源软件层出不穷,只是疲于奔命的去了解软件的安装配置方法实在算不上是一个好的方法,反而如果能够了解学习吸收到软件背后的设计思想和架构原理,那么不管开源软件如何迭代,也能轻易的掌握其本质。
就跟现在的计算机飞快发展,但是其背后的冯·诺依曼体系结构永远是不变的核心。
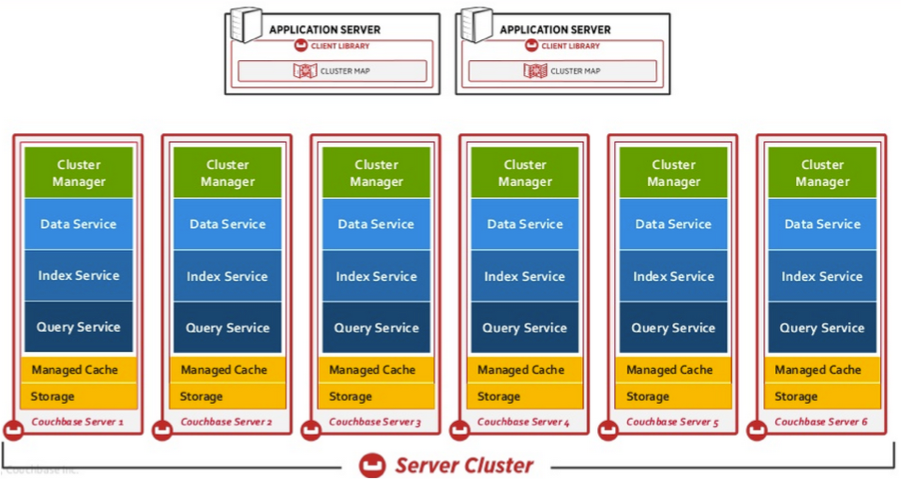
下面了解CouchBase中所使用到的一些关键术语
- Data:我们要存储的数据,在Couchbase中一条数据就是一个item。每个item都是k,v结构的,包含一个value以及用来查找value的key。value可以是二进制也可以是json文档。
- Buckets, Memory, and Storage:Buckets直译为桶,是couchbase中组织数据的一种方式,类似于关系数据库中的database。couchbase中item存储在Bucket中。注意其中并没有table的概念。Bucket是存储在内存中的,视Bucket类型的不同,也有可能持久化到硬盘中。
- Couchbase类型:存储到内存和硬盘中
- Ephemeral类型:只存储到内存中,Couchbase特有。
- Memcached类型:兼容Memcached协议,只存储到内存中。
- Services:数据已经存储起来了,同样也需要外界查询,而分布式部署的不同类型的service支持不同的查询方式。例如Data Service可以允许通过key来获取value,Query Service可以允许通过类sql的查询语言来获取结果,并且这些Service是可以独立的部署在不同的节点上的。
- Indexes:Index索引数据允许高速的访问数据。
- Server:一台couchbase节点被称之为Server
- Cluster:多个Server节点组合成为一个Cluster,例如我们前面的3台机器就是组合成为了一个集群
- Security:CouchBase基于RDBC策略的权限控制在灵活性和安全性有一个良好的平好,还包括ssl加密和3A认证。
- Rebalance:data和index在集群内多个节点之间重新负载均衡的过程。任何集群配置的变动都最好做一次Rebalance,需要手动触发。
- Availability:高可用措施
- 备份和还原
- XDCR:跨集群复制
- Data Recovery:某个节点故障了,恢复后数据从本地恢复或者从其他的节点获取最新的数据
- Intra-Cluster Replication:集群内部的数据复制
- Services:
- Analytics:提供join,set,aggregation和group之类的操作,这类操作往往是大数据量,运行时间长,资源消耗多
- Data:通过key来获取value
- Eventing:提供即时操作,近乎实时的对数据进行操作
- Query:提供类sql的查询
- Search:专门为全文搜索创建索引,全文搜索可以用于自然语言搜索
- Index:为Analytics和Query创建索引
- Scaling:根据工作负载进行横向扩容,例如某个组件要承担较重的负载就可以在多个节点上部署该服务
- Tools:提供各种工具用于集群管理
- CLI:命令行工具
- Web Console:我们之前已经看过的管理界面
- REST API:通过api进行管理
- SDK:couchbase也提供了各种语言的sdk,直接接入进sdk就可以使用couchbase了
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">