只做简单理解,因为数据库原理课上老师讲了数据库实现了数据的独立,就是不管数据真正存在哪里,我要查这个,你给我就完事了;而操作系统实现了具体设备的独立性。不管你哪个厂家的鼠标,键盘,显示器,插上来我就能用,显示的协议都一样。
感觉挺有道理的,越来越感觉到接口和抽象的威力,简直是人类协作的一大利器,这让我想到大话设计模式中说的,四大发明其他三个都是真的发明,但是活字印刷术只不过是改进了原来的印刷技术,怎么能和其他并列呢?那是因为活字印刷术就是最早的面向对象方法啊!可扩展,可维护,可复用,灵活性好~仔细想想都很符合,这就是设计理念的力量,不多扯了哈哈。
数据库的数据存在哪呢?我们都以文件形式写文件里了,但是文件是操作系统虚拟出来的文件系统啊,数据其实是存在磁盘里的,具体怎么存跟操作系统的文件管理系统有关。这里就涉及到数据库设计的学问了,比如怎么从磁盘中查的快呢?这也是为什么oracle能靠卖个数据库挣这么多年钱,而要想设计好的方法,首先得知道数据怎么存的,于是我搜索比对了一些资料,简单总结下操作系统的文件管理系统的体系下,磁盘、分区、文件这些的概念。提示一下,我这篇的行文逻辑是,数据库要解决存取文件快其实要先了解操作系统怎么把文件映射到磁盘的,然后再研究磁盘存取的特性,才能做出牛逼的数据库~所以先写文件,再写磁盘,理清逻辑。
文件系统
文件
在系统运行时,计算机以进程为基本单位进行资源的调度和分配;而在用户进行的输入、输出中,则以文件为基本单位。文件的概念不需要死记硬背,其实就是一种逻辑上的组织形式,现在在PC里已经是无处不在了。
但是需要抽象的理解一下,就是有一堆数据项,比如说描述对象某个属性的值,人的名字,一些数据项 名字啊,性别啊组合起来就成为一个记录,然后文件就是这些记录的一个集合。
这个文件要么是有结构的,比如说某班学生文件里记录了班级里学生的信息,他们都很相似,这就是有结构的;无结构的文件就堪称字符流就行了,看不懂的编译后的文件那些就算无结构的。
目录
文件有一定的属性,包括名称啊,唯一标识符啊,类型,位置,大小等等,都保存在目录结构中。这个目录结构也存在外村上。文件信息需要时再被调入内存。一般,目录条目包括文件名,和唯一标识符。这个唯一标识符就能定位文件其他的属性信息。
所以在创建文件时不仅要在文件系统中为文件找到空间这个动作,还要在目录中为新文件创建一个条目。
写文件也是类似,告诉系统我要写的文件名和内容。对于给定的文件名,系统先搜索目录,根据条目去定位文件位置。然后再把一个写的指针返回回来给你写内容。
其他操作也是类似。这就是文件目录的好处。但是因为很多操作都涉及给定文件名然后搜索相关目录条目,而目录条目也是在外存上的,这样就不方便所以许多系统要求在首次使用文件的时候,调用一个open。维护一个包含所有打开文件信息的表,就叫打开文件表。
目的就是需要一个文件操作时,这个表里要是有,直接按照里面的索引找就行了,不用在去目录里搜。其实是个运行时缓存的思想吧。文件不用了进程可以关闭,操作系统再从打开文件表里删除这个条目。

可以简单的理解为,open之后,把文件的目录条目直接放到打开文件表里。然后进程打开文件要操作的时候,给你个指针,简化步骤,IO操作都用这个指针就行了,不需要知道文件名了。
目录结构
再细对现在的我还用处不大,值得讲的是,目录结构里,有个文件控制块,跟进程控制块差不多,叫FCB,名字也差不多,就是实现给你个文件名字,在目录结构里能找到他。
这个FCB里有一堆文件的基本信息和存取控制信息,如文件的存取权限,使用信息,如什么时候建的、什么时候修改过这些,这个东西就是要记录的东西。前面说的记录一个条目或者说目录项,就是这个条目。创建新文件的时候,就有一个FCB放进文件目录中。
然后进一步的,每次检索目录文件也就是前面那个目录的时候,都是拿着给的文件名一直查查查,只有匹配了才会看目录项里其他的,比如物理地址啊什么的。其他描述信息没啥用,所以像UNIX这样的系统,有在中间加了一层,文件的描述信息单独形成一个成为索引节点的东西,inode。每个目录项只放文件名,和指向它的inode的指针。
意思就是拿着文件名先匹配,匹配到了再说,给你个inode指针,你在去里面找文件的物理地址吧,这样节省了好多系统开销。
因为一个FCB是64B,而UNIX系统一个目录只占16B,我们知道真正查文件时是在磁盘上找的,每次查磁盘最小是查一个块(这个后面讲磁盘会再梳理一下),一个块里你放的东西多,那你需要找的块就少,你跟磁盘互动的次数就少了3/4,大大节省了开销。
下面这个概念也要了解下,直接复制的。
多级目录结构
也成为树形目录结构。将两级目录结构的层析加以推广,就形成了多级目录结构,及树形目录结构。
用户要访问某个文件时用文件的路径名标识文件,文件路径名是一个字符串,由从根目录出发到所找文件的通路商的所有目录名与数据文件名用分隔符/连接起来而成。从根目录出发的路径称为绝对路径。当层次较多时,每次从根目录查询浪费时间,于是加入了当前目录,进程对各文件的访问都是相对于当前目录进行的。当用户要访问某个文件时,使用相对路径标识文件,相对路径由从当前目录出发到所找文件通路商所有目录名与数据文件名用分隔符**/**链接而成。
通常,每个用户都有自己的当前目录,登陆后自动进入该用户的当前目录。操作系统提供一条专门的系统调用,供用户随时改变当前目录。
树形目录结构可以很方便的对文件进行分类,层次结构清晰,也能够更有效地进行文件的管理和保护。但是,**在属性目录中查找一个文件,需要按路径名主机访问中间节点,**这就增加了磁盘访问次数,无疑将影响查询速度。
没有细追究,这个当前目录跟命令行里 可以直接操作目前命令行里的文件 也可以以绝对路径操作任意地方的文件 有关不,感觉是这样安排的。
文件的打开过程
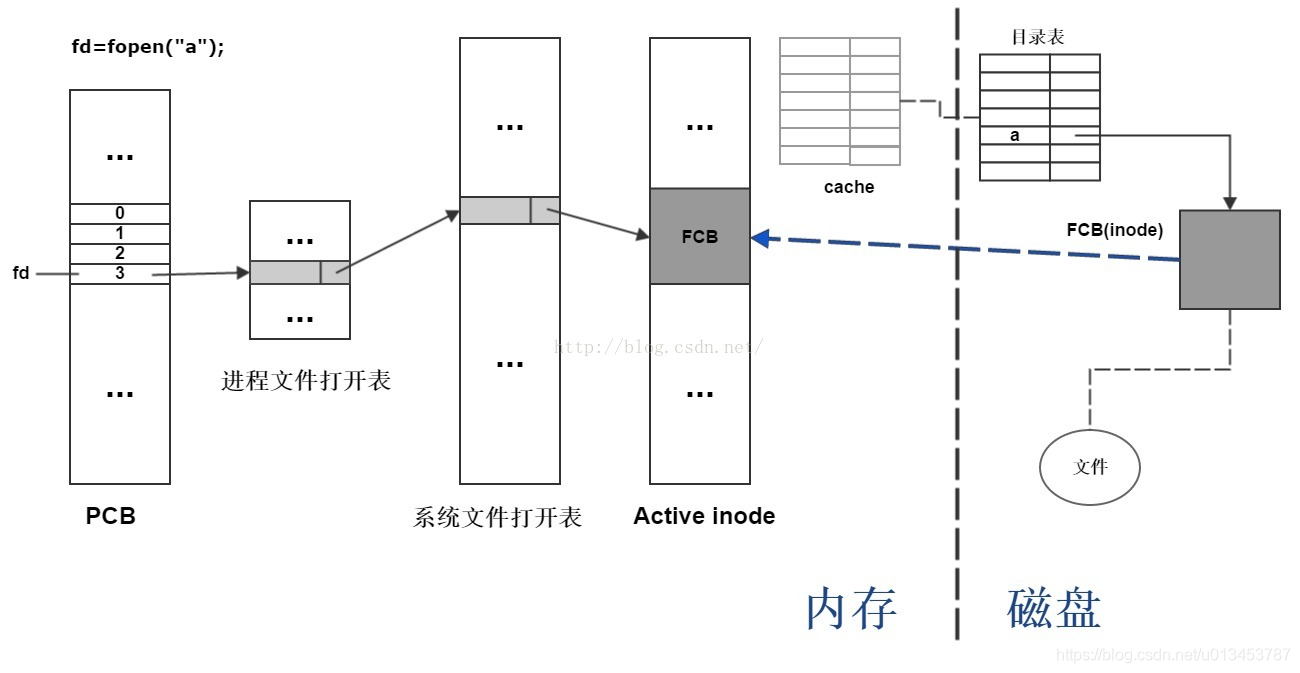
以上是文件的打开过程,应该从右往左看。
首先,操作系统根据文件名a,在系统文件打开表中查找
第一种情况:
如果文件a已经打开,则在进程文件打开表中为文件a分配一个表项,然后将该表项的指针指向系统文件打开表中和文件a对应的一项;
然后再PCB中为文件分配一个文件描述符fd,作为进程文件打开表项的指针,文件打开完成。
第二种情况:
如果文件a没有打开,查看含有文件a信息的目录项是否在内存中,如果不在,将目录表装入到内存中,作为cache;
根据目录表中文件a对应项找到FCB在磁盘中的位置;
将文件a的FCB装入到内存中的Active inode中;
然后在系统文件打开表中为文件a增加新的一个表项,将表项的指针指向Active Inode中文件a的FCB;
然后在进程的文件打开表中分配新的一项,将该表项的指针指向系统文件打开表中文件a对应的表项;
然后在PCB中,为文件a分配一个文件描述符fd,作为进程文件打开表项的指针,文件打开完成。
总之就是要完成这一个一个指针一样的链接,这样在操作文件的时候才会可以得到上述那么多的好处。文件的大概理解到这里,有机会在研究真正内部的东西,下面谈谈磁盘的事。
磁盘
磁盘磁道柱面的概念网上到处都是,给出一个图。
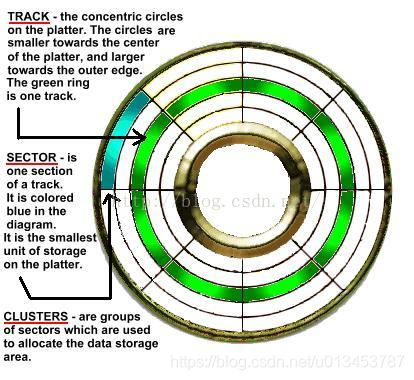
物理上来说,硬盘主要由若干盘片、机械手臂、读写磁头与主轴马达组成。盘片表面涂以磁性介质,用以存储数据。每个盘片有两面,都可记录信息。而读写主要是透过在机械手臂上的读写磁头来达成。实际运作时,主轴马达让盘片转动,然后机械手臂可伸展使磁头到达指定的位置,在盘片上进行读写动作。每个盘片有两个面,每个面都有一个磁头。
逻辑上来说,又有磁道(track)、扇区(Sector)和柱面(Cylinder)的概念:
当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道(track)。这些磁道用肉眼是看不到的,磁盘上的信息便是沿着这样的轨道存放的。
盘片上的每个磁道被等分为若干个弧段,这些弧段便是磁盘的扇区,每个扇区存放512个字节的信息,磁盘驱动器在向磁盘读取和写入数据时,都是以扇区为单位。
柱面:磁盘通常由一组盘片构成,不同盘片相同半径的磁道所组成的圆柱称为柱面。每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号。磁道与柱面都是表示不同半径的圆,在许多场合,磁道和柱面可以互换使用
可以得到的信息有:
1.硬盘容量=磁头数Head×磁道(柱面Cylinder)数×每道扇区Sector数×每扇区字节数(一般初始为512)。这个就是常说的磁盘的CHS,知道了CHS就能确定硬盘的容量。
2.每个磁道上的扇区数目一样,所以越往外扇区面积越大,但是早期每个扇区存的数据量一样,都是512字节。所以里面扇区密度大,外面小。
当像硬盘写入数据时,险些如最外层的磁道,写满所有扇区再往内层磁道写。这就是为什么感觉硬盘用久了,读写都会变慢。磁盘整理基本的意思就是能利用再尽量整理整理用外面的。
对磁盘的具体使用需要分区,然后在具体操作系统的文件系统上,这个上面说过了。
关于分区需要知道主引导记录(Master Boot Record,MBR),又叫做主引导扇区,是计算机开机后访问硬盘时所必须要读取的首个扇区,它存储在0号盘面的0号磁道的1号扇区上。系统在启动时主动去读取这个区块的内容,这样系统才会知道你的程序放在哪里且该如何进行启动。
簇的概念
有的操作系统叫簇,有的叫块,其实差不多。簇是操作系统分配内存的最小单位。如,就算一个文件小到只有一个字节,它在磁盘上也不是只占一个字节的空间,而是占有一簇。这样设置是为了让硬盘对数据的管理变得相对容易,因为如果不容易管理数据,存再多都没有意义,簇通常为多个扇区。
这样,对磁盘进行存取的时候,最后都是对簇进行的存取而不是一个一个的扇区,减少了磁头的扫描,可以达到更快的效果。
总结
回到最开始的问题,由以上可知,要想设计一个数据库事其存取数据的操作很快,一个比较泛化的标准是:必须找到一套存储和检索数据的方法,在这样的方法下,任意的数据库操作,如大规模的变换条件的查询,修改,删除等操作发生时,数据库跟磁盘的IO,即磁头扫描簇的操作很少。这样就可以保证数据库操作的快速。这里最大的进步就是,想优化文件的IO是幼稚的想法,说了很多遍数据其实都是写在磁盘上的。
基础很重要,慢慢补。不积跬步无以至千里。