2018.7.19
远算科技
一面:
手撕LRU算法
二面:
1、缓存替换算法有哪几种,指标是什么?
2、FTL层是什么,作用是什么,为什么要这么做?
3、现在有人说要去掉FTL层,为什么要去掉,有什么好处?还有什么弊端
4、简单的说下专利的思想
5、什么是预取,预取的大小如何控制,何时预取,预取的大小?预取操作性能指标是什么?
6、对于一个顺序读的操作,预取的大小怎么控制?是否可以建立相应的模型?
7、听说过文件预取吗?
————————————————————————————————————————————
2018.7.20
CVTE笔试
1、struct和union对于内存优化的区别
2、任意字符串,通过插入,删除,替换操作,求最小操作数让两个字符串相等
————————————————————————————————————————————
2018.8.4
顺丰一面:
1.函数指针,指针函数的区别
——函数指针是指向函数的指针,用在宏里面较多
——指针函数是返回值为指针的函数
——一个是函数,一个是指针
2.vector容器的讲解
3.timewait状态发生在哪些
——发生在主动断开连接方,可以在服务端也可以在客户端
4.KVM和docker的区别,在底层系统结构上的区别
——????这个回去得仔细看看,吸取经验
5.queue和stack的区别和应用场景
——bfs,dfs
2018.8.5
thoughtwork一面
1.迷宫编程
2018.8.7
百度一面:
1、项目
2、网络
——tcp三次握手
——三次握手第二次没有收到回信,然后客户端又重新发送,这个时候又收到回信了怎么办?
——拒绝这一次的报文
——udp头部是怎么样的,udp和ip层不一样,封装了哪些
——源端口号,目的端口号,数据长度,数据CRC校验
3、操作系统
——进程和线程的区别
——进程之间的通信方式
——线程之间共享哪些资源
——除了自身的堆栈和寄存器之外的一些资源
空指针NULL,如果对它解引用,内核会发生什么??会抛出段错误,段错误如何抛出的?
空地址,会去查看页表
——
对于每个进程,操作系统养了的页表的,这就决定了地址的映射方式对于这种情况发生在每次存储器访问时,CPU根据页表转换它。如果翻译成功,则执行相应的读/写到物理存储器位置
有趣的事情时,地址转换失败发生。不是所有的地址是有效的,如果有任何内存访问产生的无效地址,处理器引发的页故障异常的。这将触发从一个过渡的用户模式的转换成的内核模式的(即CPL 0)在内核中的code特定的位置,由中断描述符表定义的(IDT)。内核重新获得控制,并且基于从异常和进程的页表中的信息,计算出发生了什么。在这种情况下,认识到,用户级进程访问一个无效的内存位置,然后将其相应的反应。在Windows中,它会调用结构化异常处理允许用户code来处理异常。在POSIX系统,操作系统将提供一个 SIGSEGV 信号的过程。
——实际上NULL就是0,代表了数值编号为0的一个内存地址,那么解引用就是0号地址,那不是可以给0号地址写数据,这就说明NULL是可以作为一个正常的地址来使用的,如此一来就出现了一个漏洞,其实按照理论上讲除非你把NULL地址的内存的访问权限完全封死,要不然这个漏洞就是无法弥补的,只能通过程序员自己来负责了。而完全封死NULL又不符合设计规范,用户空间的进程内存是可以被该进程自由访问的,任何机构都没有权力封死一块内存的访问权限,既然不能封死NULL,那么按照规则和编译器的特性内核中的指针在初始化的时候都被初始化成了 NULL,如果后面没有再被赋予正确的值,那么它将一直是NULL,如果此时有一个执行绪没有检查NULL指针直接调用了一个可能是NULL的回调函数,那么只要在NULL地址处映射着的代码都将被执行,而映射什么代码全部是用户进程说了算的。
—— NULL指针解引用漏洞 NULL指针解引用是最常见的漏洞之一。指针即包含内存中某一变量的地址值,当指针解引用时,即可获取内存地址中存放的变量值。一个静态未初始化的指针,其内容为 NULL即(0x0).在内核代码中NULL值常在变量初始化、设置为缺省值或者作为一个错误返回值时使用。在系统中,虚拟地址空间分为两个部分,分别称为内核空间和用户进程空间,当内核尝试解引用一个NULL指针时,若用户又允许映射NULL地址(如首个页面包含0地址),则可直接或间接控制内核代码路径。(注:NULL指针引用BUG主要是因进程在执行指针解引用时,没有检查其合法性造成的,若待解引用的地址为NULL,则在内核态访问NULL指针时会引发Oops,此时若黑客在用户态将NULL地址设置为可执行并注入恶意代码,则内核代码将会执行NULL地址的恶意指令。
——于是乎在内核空间为了安全起见一般都将函数指针初始化为一个 stub函数,然后在该stub中直接返回一个出错码,还有一种初始化方式就是初始化为一个0xc0000000指针,用户空间是无法访问内核空间的,因此就不能往这个地址映射任何东西,内核空间和用户空间完全分治。
现在的内核普遍采用了stub函数的初始化方式
——如果进程取找磁盘上的数据,这个时候会发生什么??先查看页表,再去触发中断
——在程序的执行过程中,因某种原因使CPU无法访问到相应的物理内存单元,即无法完成从虚拟地址到物理地址映射时,CPU会产生一次缺页异常,从而进行相应的缺页异常处理,如目标页面不存在(页表项全 0,即该线性地址与物理地址尚未建立映射或者已经撤销)或者相应的物理页面不在内存中(如在swap分区或磁盘文件上)等。当CPU捕获到这个异常的时候就会引发一次缺页异常中断,并调用do_page_fault()函数来判断和处理这些异常。当把数据从磁盘读到内存的时候,cpu再去指定的内存地址取数据,最后返回给指定的进程。
注意:在查找页表的时候,页表上逻辑地址会有对应的标志,有些标志是在内存,有些标志在磁盘,有些0地址标志为只读
4、算法
——ip地址去掉.号之后,然后增加点号,能组成有效ip地址的个数
——这是个有限的次数,最多就是c11 3,就是三个点的放置,实际可以看成一个多叉树,然后多叉树形成的时候去判断剪枝的条件。一个是不能超过255,一个是不能超过三位数。
——从左到右,从上到下有效的数组怎么样搜索某一个值,复杂度多少
——降低复杂度,可以用二分来完成,复杂度多少
————————————————————————————————————————————
2018.8.8
金山wps一面
1.构造和析构函数的内容考察
class a;
class b:public a
new b对象的时候的构造顺序,先构造a在构造b,
a有一个虚函数funa,b里面的funb对a进行修改了。
a* p = new b(); 这个时候调用的是b的虚函数,因为b的虚函数重写了。
如果 a的构造函数里面有个虚函数,b重写了这个虚函数,
同样a* p = new b();,这个时候p调用的是a的虚函数,为什么,因为先构造的a,这个时候虚函数表指针指向的a,并没有找到b,这个位置需要好好了解!!!!!
a a1 = new b(),这个时候delete a1,析构释放的是a对象的值,因为指向的b里面继承的a
2、全局变量和静态全局变量的区别
静态全局变量有叠加的性质,全局变量没有
3、sizeof和strlen的区别
char a[10] = {0}
sizeof(a) = 10;
strlen(a) = 4;
4、const和define的区别
5、函数传参数,一个是普通参数,一个是const的传参数,两者的区别是什么?
6、STL的相关问题
vector和list的区别
hashmap和map的区别
vector和list不断的pushback哪个耗时
7、算法:
求树的深度(depth(root) = max(depth(left),depth(right))+1)
求删除重复数组中的数字(数组映射删除)
海量数据查找(位图的位运算)
————————————————————————————————————————————
2018.8.9
百度一面:
算法:
1、堆排序
2、连续最大子数组
3、LRU
项目:
分布式存储框架
分布式存储的io流的写入写出
网络:
三次握手四次挥手
简单描述下send数据出现的一个完整过程
网络出现拥塞tcp是如何解决的
操作系统
内存的分配,连续和非连续
置换算法
进程在内存中的分布
局部变量和非局部变量调用内存堆栈位置
为什么数据段要和代码段分开,从编译角度去分析
cpp
继承类构造和析构的顺序
简单讲下cpp里面的虚函数
多态是什么
算法:
排序算法是哪几类
堆排和快排时间复杂度一样,两者有什么区别
能描述下堆排的过程吗
————————————————————————————————————————————
百度二面:
分布式场景题:
1、分布式中多副本的写入,出现异常的情况怎么解决
异常一:副本机器直接宕掉,心跳机制解决
异常二:副本有较大延迟,怎么解决,客户端向每个副本发送包
异常三:副本直接网络有较大延迟,怎么解决?客户端向a b返回,客户端向b c返回,循环测试网络环路是不是正确的
2、分布式中副本写入有两种方式,一种是链式结构,一种分发的结构,这两种结构谁好谁坏,吞吐量和延时比较
链式结构:吞吐量较大,但是延时较高,吞吐量达是因为可以连续的处理
分发结构:吞吐量小,但是延时较低,因为分发结构是并行结构,所有可以并行处理请求,请求延时小
3、操作系统
——操作系统中锁有了解吗,自旋锁和互斥锁的区别,分别适用于哪些场景
——自旋锁:轮询等待,适用于等待时间较小的场景
——互斥锁:没拿到锁的时候会睡眠,释放锁在去唤醒,适用于等待时间较长的场景
4、算法题:
——0的概率为p,1的概率为1-p,请问怎么能产生概率为50%的数
——怎么判断两个链表是否相交
——给你多个集合,这集合中的数是有序的,但是这个集合数字大小是不确定的,集合是有限的,怎么判断多个集合的数字存在或者不存在。
——给你三个队列,这三个队列的权重是1,3,5,怎么样进行调度,让队列的数据按照1/9,3/9,5/9进行
5、分布式文件系统的场景
——文件系统中客户端创建一个目录,服务器端收到了,创建的目录,这个时候返回确认信号丢失,这个时候客户端重发了,但是服务器这个时候发现自己已经创建的目录,这个时候返回存在的信号,而客户端需要的是ok信号,这种情况怎么处理
——答:通过创建一个会话,这个会话是当前发送的唯一性,会话id主要有客户端发送的时间,服务器端的ip地址,和服务器端的当前进程,服务器端收到会话的时候,会去检查是不是当前的会话,是不是第一次创建的时间,判断是不是创建同一个目录,如果是这种情况下就直接回复ok,不是这种情况下就回复存在。
6、时间问题
在文件系统中会有多个时间,如果让分布式系统的时间相同,同时时间是一个递增的状态。
——答:需要去了解下百度的rpc的开源框架
————————————————————————————————————————————
2018.8.11
顺丰hr面:
1、简历介绍
2、简历上每个项目的负责
3、项目带领的时候,出现了哪些问题
4、出现的问题你是如何协调的
5、对顺丰科技的了解
6、未来从事的发展方向
7、女朋友
8、独生子女
9、薪水
10、工作地的旋转
11、顺丰的业务
————————————————————————————————————————————
2018.8.13
远算三面:
1、项目遇到的难点是什么
2、pgsql科研项目遇到的难道
3、公司的业务
————————————————————————————————————————————
2018.8.14
远算四面:
1、对公司的了解
2、个人最大的特点
3、公司的介绍
————————————————————————————————————————————
百度二面:
1、项目,数据库,io延时告警的设置
2、两个算法,一个是二叉树的深度,一个是旋转数组的大小
————————————————————————————————————————————
2018.8.15
百度三面:
1、实习经验
2、项目中遇到的问题
3、团队合作
4、自己怎么学习
5、SSD的相关问题
6、有面试过其他公司吗
7、有面试百度的其他部门吗
————————————————————————————————————————————
2018.8.17
阿里一面:
1、项目相关经验
2、cpp中什么情况下迭代器会失效
3、分布式的一致性是什么?说一下原理
4、互斥锁和自旋锁的区别与联系
5、ext4文件系统相关知识
————————————————————————————————————————————
2018.8.20
远算hr面:
1、薪资
2、团队中遇到的困难
3、女朋友
4、为人性格
5、入职时间
6、能不能来实习
————————————————————————————————————————————
2018.8.21
依图科技一面:
1、项目的基本架构
2、分布式存储系统的性能评估
3、了解kv存储,举个例子
4、memecached的基本框架
5、memcached的性能瓶颈,性能瓶颈在网络上,网络的带宽小于内存的带宽
6、网络瓶颈还是内存的瓶颈
7、给你20个OSD,每个上面的HDD,网络带宽是万兆网,4KB的随机IOPS是多少
8、HDD的iops的大小,1.5TB的HDD最多200出头,一般4KB都是100多左右
9、linux知识,有用过linux里面一些抓包工具吗
10、算法题:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
11、智力题:在房里有三盏灯,房外有三个开关,在房外看不见房内的情况,你只能进门一次,你用什么方法来区分那个开关控制那一盏灯?
12、项目里面监控哪些参数,监控的参数用什么形式展现的?
13、用哪种数据库存放这一类监控数据,多长时间清理一次?
14、进程线程的资源如何监控?
————————————————————————————————————————————
2018.8.21
多益网络一面:
1、实习项目
2、cpp里面对象的生命周期
——分为堆和栈两种情况
3、cpp里面内存泄漏如何预防和监测
——vargrid
4、内存泄漏监测工具是如何完成的
5、团队合作上又遇到问题吗
6、目前有没有其他的offer
7、基本薪资期望是多少
8、如何看待加班这个问题
9、算法:由于某种原因一个二叉排序树的两个节点的元素被交换,在不改变树的结构的情况下恢复这棵二叉排序树
————————————————————————————————————————————
2018.8.21
拼多多一面
1、分布式存储的项目
2、数据库缓存替换算法的项目
3、操作系统中进程,线程,协程的区别
——线程的切换一般收操作系统内核的管理机制进行,而协程则完完全全由用户来完成。
——协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
——1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
4、说一下线程切换的过程
5、操作系统中内存的分配
6、操作系统中的置换页
7、网络的滑动窗口
8、tcp中的慢启动
9、算法:给你一个数组,有子id和父id,构造一个多叉树
struct input_node {
int id;
int parent_id;
}
struct tree_node{
int tree_id;
int child_size;
vector<struct tree_node*> children;
}
tree_node* build(vector<input_node> inputs) {
if(inpus.size()<0)
return NULL;
tree_node* rootnode = NULL;
unordered_map<int,struct tree_node*> mpp;
unordered_map<int,int> mp;
for(int i=0;i<inpus.size();i++){
mp[inpus[i].id] = inpus[i].parent_id;
tree_node* node= new tree_node();
node->tree_id= inpus[i].id;
mpp[inpus[i].id] = node;
}
for(int i=0;i<inpus.size();i++){
if(mp.find(inpus[i].parent_id)==mp.end())
{
rootnode = mpp[inpus[i].id];
}
}
for(int i=0;i<inpus.size();i++){
if(inpus[i].id!=rootnode->tree_id)
{
auto i = mpp.find(inpus[i].parent_id);
if(i!=mpp.end()){
(*i)->children.push_back(mpp[inpus[i].id]);
(*i)->child_size++;
}
}
}
return rootnode;
}
————————————————————————————————————————————
2018.8.22
360一面
1、项目
2、数据库的项目
3、项目中监控模块的监控项
4、遇到的困难,难点
5、网络中的拥塞控制
6、滑动窗口
7、算法题,有序数组的去重
——通过前后比较,并维护一个当前不重复的计数即可
8.网络tcpip 流量控制拥塞控制
9.分布式:一致性的协议 pxaos协议,两段式提交协议
——pxaos协议,paxos就是解决多个节点写入的问题,即多个节点写入一个同一个值,且被写入之后不再更改
——pxaos两个操作,一个是提议的值,一个是提议的操作
——三个角色,proposer提议的发起者,proposer提出value
——acceptors,提议的接受者,有N个proposer提出的value必须获得超过半数的acceptors批准后通过
——learner,提议学习者,将通过的value同步给其他的未确定的acceptors
——协议过程,pxaos将发起的提案value给所有的accpetors,超过半数的accpetor获得批准后,proposer将填下入acceptors,acceptors或得一致性确定的写入值,且后序不能修改
——准备阶段:proposer首先选择一个提议的编号n,向所有的acceptors进行广播,acceptors接到广播之后,如果n比之前acceptors接受到的编号都要大,那么承诺不会接受比n小的提议,
——接受阶段:如果没有超过半数的proposer接收到响应,那么转换为提议失败
——如果接收到了超过半数的承诺,又分为不同情况
——如果当前所有的acceptors都没有接收过值,那么发起自己的value值
——如果当前有部分acceptors接受过值,从所有接收过的值中选取对应提议编号最大的值最为value,但是这个时候proposer不能提议自己的值,智能信任acceptors接收的值。
——如果acceptors接收到提议之后,如果提议的版本号不等于准备阶段的版本号,就不接受请求,重新发起新的pxaos,否则接收持久化写入
————————————————————————————————————————————
2018.8.23
wps二面
1、c++里面多态是什么样的,哪些函数可以不能设置成为虚函数(构造函数,静态函数)
——(构造函数,静态函数)
2、静态函数一般用在哪些场景,静态函数可以调用类的普通函数吗
——不能,类的普通函数需要对象的this指针来引用,但是静态函数属于这个类,不属于这个对象,是没有对应的this指针的。
3、虚函数可以为构造函数吗,虚函数可以是析构函数吗
——构造函数不能为虚函数,但是析构函数是虚函数
4、构造函数里面调用虚函数,这个时候会如何执行动态绑定
——构造函数里面调用虚函数,则这个函数失去了动态绑定,只能被当前类绑定
——不要在构造函数中调用虚函数的原因:因为父类对象会在子类之前进行构造,此时子类部分的数据成员还未初始化, 因此调用子类的虚函数是不安全的,故而C++不会进行动态联编。
5、析构函数里面调用虚函数,这个时候会如何执行动态绑定
——析构函数里面调用虚函数,则这个函数失去了动态绑定,只能被当前类绑定
——不要在析构函数中调用虚函数的原因:析构函数是用来销毁一个对象的,在销毁一个对象时,先调用子类的析构函数,然后再调用基类的析构函数。所以在调用基类的析构函数时,派生类对象的数据成员已经“销毁”,这个时再调用子类的虚函数已经没有意义了。
6、静态函数一般作用是什么
——提供一个全局的静态访问点
7、算法题,图像用RGB表示,那么给定字体颜色,求相差最大的背景颜色,通过求字体颜色和背景颜色相差最大的选定颜色
8、算法题,多叉树的遍历,多叉树的平均深度,最大深度和最小深度的平均值
9、算法题,计算机里面i++,操作变成指令一共有几条(读取,加法,写会)
——一般是有读,自加,写回,需要考虑写回的问题,写回的时候会发生覆盖操作。
10、算法题,初始值为0,两个线程同时执行i++,可能出现的情况,一个线程i++ 50次,一个线程i++100次,最后可能出现的结果。
——50~150次
————————————————————————————————————————————
2018.8.23
拼多多二面
1、网络攻击知道哪些
——ARP欺骗、DNS欺骗,DDOS攻击
2、半连接攻击了解过吗,有用过对应网络攻击的工具吗
——SYN攻击属于DOS攻击的一种,它利用TCP协议缺陷,通过发送大量的半连接请求,耗费CPU和内存资源。
——客户端在短时间内伪造大量不存在的IP地址,向服务器不断地发送syn包,服务器回复确认包,并等待客户的确认,由于源地址是不存在的,服务器需要不断的重发直至超时,这些伪造的SYN包将长时间占用未连接队列,正常的SYN请求被丢弃,目标系统运行缓慢,严重者引起网络堵塞甚至系统瘫痪。
3、MD5了解过吗,有哪些应用场景
——MD5方法: 一个任意长度的数据,经过MD5计算后就会得到一个长度固定的十六进制字符串
——MD5常常作为文件的签名出现,我们在下载文件的时候,常常会看到文件页面上附带一个扩展名为.MD5的文本或者一行字符,这行字符就是就是把整个文件当作原数据通过MD5计算后的值,我们下载文件后,可以用检查文件MD5信息的软件对下载到的文件在进行一次计算。两次结果对比就可以确保下载到文件的准确性。
——另一种常见用途就是网站敏感信息加密,比如用户名密码,支付签名等等。随着https技术的普及,现在的网站广泛采用前台明文传输到后台,MD5加密(使用偏移量)的方式保护敏感数据保护站点和数据安全。
4、数字签名里面会用到md5吗
——MD5还广泛用于操作系统的登陆认证上,如Unix、各类BSD系统登录密码、数字签名等诸多方。如在UNIX系统中用户的密码是以MD5(或其它类似的算法)经Hash运算后存储在文件系统中。当用户登录的时候,系统把用户输入的密码进行MD5
Hash运算,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这可以避免用户的密码被具有系统管理员权限的用户知道。
5、了解过加密码,说下常见的对称加密和非对称加密
——一个是公钥,一个是公钥+私钥
6、http协议里面的头部包含哪些信息
——Request请求的方法:OPTIONS、HEAD、GET、POST、PUT、DELETE、TRACE、CONNECT、PATCH
——Http协议Request请求头结构:
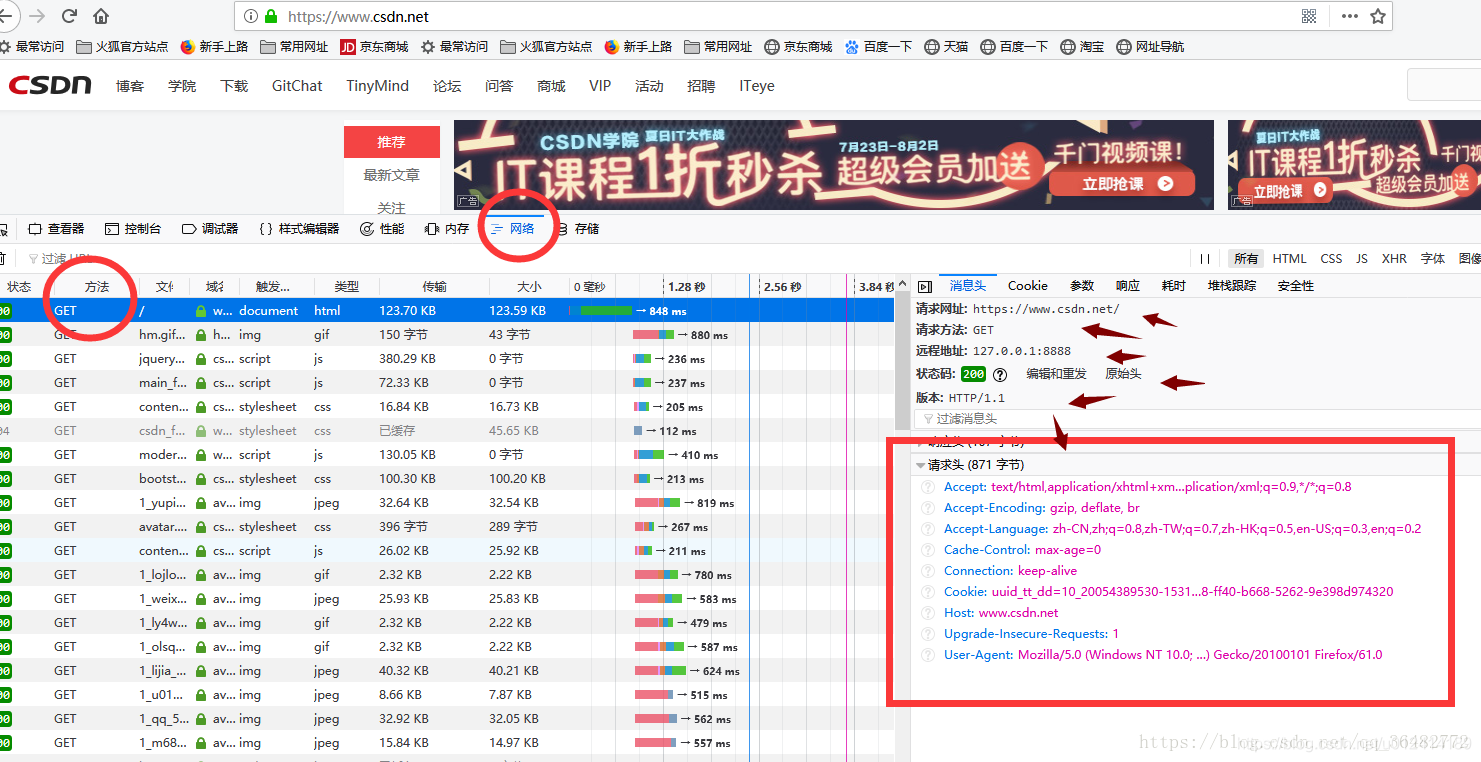
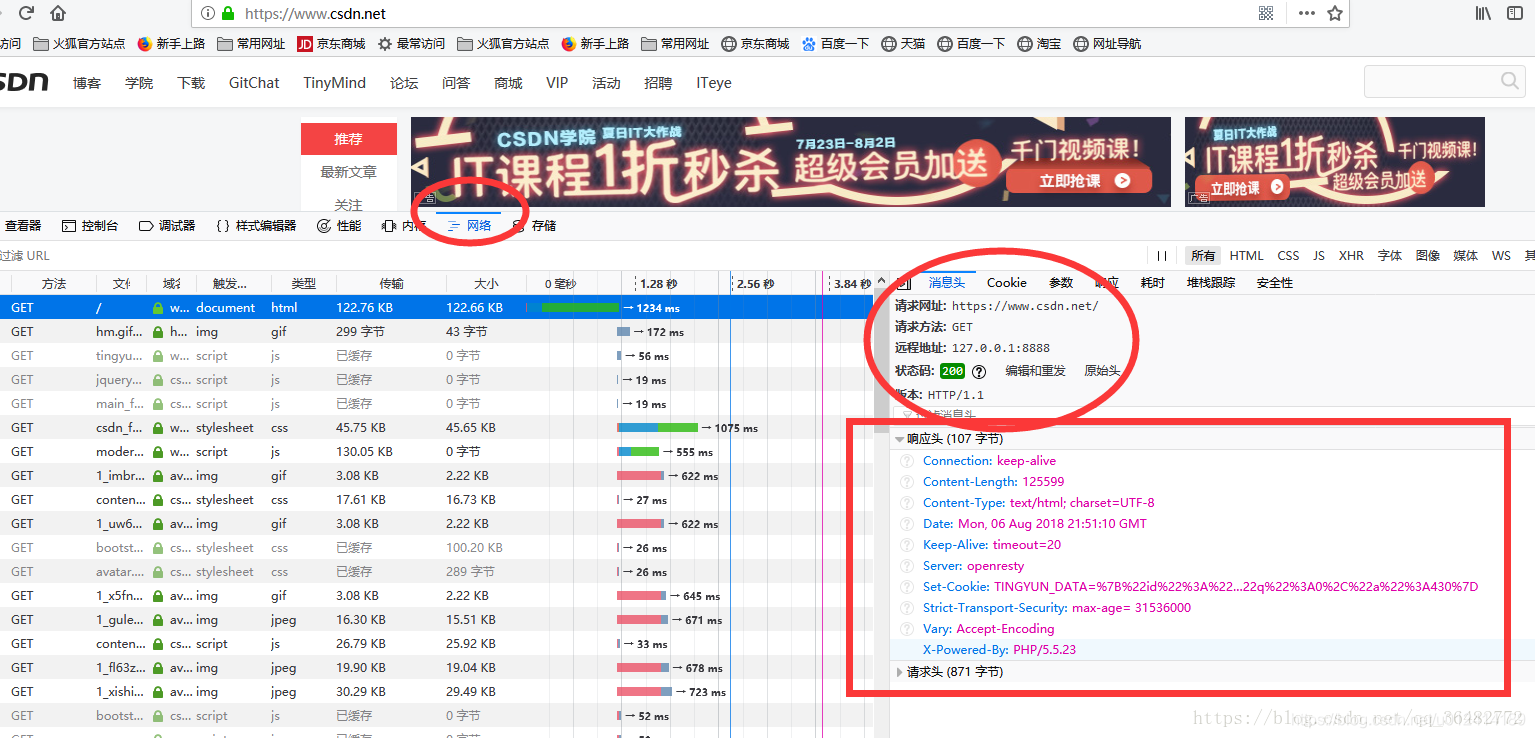
——Http协议Reponse应答头结构:
7、有用过ngnix吗,Nginx里面字段怎么保存的
8、用过mysql吧,列举下mysql的存储引擎
——innodb,MyISAM,前者支持事务,后者不支持事务
9、innodb里面存储的字段是怎么样的,用的那样的数据结构
???
10、redis可以存储哪些字段,是用什么样的数据结构
——string:可以是字符串,整数或者浮点数,对整个字符串或者字符串中的一部分执行操作,对整个整数或者浮点执行自增(increment)或者自减(decrement)操作。
——string: 一个链表,链表上的每个节点都包含了一个字符串,虫链表的两端推入或者弹出元素,根据偏移量对链表进行修剪(trim),读取单个或者多个元素,根据值查找或者移除元素。
列表命令:
①rpush、将给定值推入列表的右端
②lrange、获取列表在指定范围上的所有值
③lindex、获取列表在指定范围上的单个元素
④lpop、从列表的左端弹出一个值,并返回被弹出的值
——string:包含字符串的无序收集器(unordered collection)、并且被包含的每个字符串都是独一无二的。添加,获取,移除单个元素,检查一个元素是否存在于集合中,计算交集,并集,差集,从集合里面随机获取元素。
集合命令:
①sadd、将给定元素添加到集合
②smembers、返回集合包含的所有元素
③sismember、检查指定元素是否存在于集合中
④srem、检查指定元素是否存在于集合中,那么移除这个元素
——string:包含键值对无序散列表,添加,获取,移除当键值对,获取所有键值对。
散列命令:
①hset、在散列里面关联起指定的键值对
②hget、获取指定散列键的值
③hgetall、获取散列包含的所有键值对
④hdel、如果给定键存在于散列里面,那么移除这个键
——string:
字符串成员(member)与浮点数分值(score)之间的有序映射,元素的排列顺序由分值的大小决定。添加,获取,删除单个元素,根据分值范围(range)或者成员来获取元素。
有序集合命令:
①zadd、将一个带有给定分值的成员添加到有序集合里面
②zrange、根据元素在有序排列中所处的位置,从有序集合里面获取多个元素
③zrangebyscore、获取有序集合在给定分值范围内的所有元素
④zrem、如果指定成员存在于有序集合中,那么移除这个成员
11、memcached和redis有哪些区别
12、redis持久化是怎么做到的
——redis 需要经常将内存中的数据同步到磁盘来保证持久化。redis支持两种持久化方式,一种是 Snapshotting(快照)也是默认方式,另一种是Append-only file(缩写aof)的方式
——快照是默认的持久化方式。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以通过配置设置自动做快照持久 化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照,下面是默认的快照保存配置
——aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要 通过fsync函数强制os写入到磁盘的时机。
13、了解常见一致性协议吗
——二段式提交,三段式提交,paxos
14、paxos一般包含哪些组件
——zk
15、zk主要完成哪些功能
——能提供主从协调、服务器节点控制、统一配置管理、分布式共享锁、统一名称服务等功能
16、zk持久化数据,是以什么样的数据结构存储数据的
——树的数据结构,具体是什么不清楚
17、了解RPC吗,基本组件是怎么样的,哪些功能
——
1.RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
2.RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
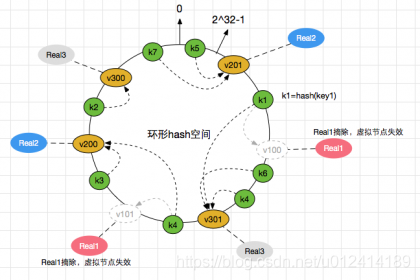
18、一致性哈希原理讲解下
19、为什么会用一致性哈希而不用其他的
——因为一致性哈希能保证数据均衡,同时能够尽可能较少宕机导致的数据迁移
20、一致性哈希发生迁移时候,节点瞬间流量压力变大时如何解决的
——因为引入了虚拟节点,虚拟节点对应的物理机发生了宕机,可以将对应的数据分布到其他的机器上,而不是单独的一个机器上来实现瞬间流量压力大的情况
————————————————————————————————————————————
2018.8.24
Dellemc一面:
1、项目
2、闪存数据库缓存替换算法的项目
3、hdd和ssd的区别联系
4、常见的kv存储主要有哪些
——memecached,redis,leveldb,tail, dynamo
5、memcached的简答介绍
6、memcached和redis的区别与联系
——redis支持事务操作,支持数据持久化,支持多副本操作,存储的数据类型较多,
7、操作系统进程的内存空间
8、在shell上执行一个命令是如何加载的
——shell会派生一个新的子进程,通过这个子进程执行的。
9、如果访问到额外虚拟的内存空间是如何访问的
——数据定义的虚拟地址空间的元素,在进程访问对应的虚拟逻辑空间地址的时候,这个时候在页表上没有找到,这个时候会触发缺页中断,缺页中断会去磁盘上找到对应的数据,然后放置到内存中,并更新页表对应的映射。
10、进程的加载过程是怎么样的
——当一个程序加载到内存时,刚开始只加载0号块,剩下的块暂时不会访问到,不用加载到内存,放在虚拟内存上就可以。因此上图内存可以同时加载20块,即20个程序。假如系统有3G的内存,第一个进程只占4k,其他剩余的3G-4k的内存可以加载其他程序。
但是当去内存访问0号块完毕时,如果要访问1号块,但此时1号块不在内存上而在虚拟内存上,此时就会发生页中断(页错误)。此时CPU无法执行,中断处理程序会扫描虚拟内存,然后找到1号块所在的虚拟内存的空间,将其加载到内存,CPU再次扫描,程序正常执行。
使用虚拟内存这种管理方式的缺点是浪费时间,中断处理程序执行时,CPU需要等待,会浪费时间。
11、lls | grep 通过管道连接一共有多少个进程
——lls是一个进程,管道会创建一个子进程用来根lls通信,最后grep又是单独的进程完成筛选操作。
12、是不是所有进程都可以用管道来连接(父子关系)
——不能管道是父子进程
13、管道和命令管道有什么区别
——一个是全双工,一个半双工
14、shell终端输入一行命令,会fork一个子进程吗
——会
15、cpp里面STL的一些知识考察
16、说下map和unordermap的不同点
17、unordermap主要有哪些缺点
18、介绍一下智能指针,
19、智能共享指针里面循环引用是如何解决的
————————————————————————————————————————————
2018.8.26
网易一面:
1、手撕算法,单向链表的翻转,递归非递归,
2、手撕算法,字符串的反转,hello world变成world hello,原地反转和非原地反转
——原地反转主要是通过字符串的交换和切割单词,单词的交换
——非原地反转,主要是通过一个map来实现,索引是单词切割的序号,值是对应的单词,通过对索引进行反转,映射到对应的链表上,进行反转。
3、tcp的三次握手,具体的状态画出来,分别处于哪些状态
——首先需要了解几个名词:tcp标志位,有6种分别为:SYN(synchronous建立联机) 、ACK(acknowledgement 确认) 、PSH(push传送) 、FIN(finish结束)、 RST(reset重置) 、URG(urgent紧急);
URG 紧急指针,告诉接收TCP模块紧要指针域指着紧要数据。
ACK 置1时表示确认号(为合法,为0的时候表示数据段不包含确认信息,确认号被忽略。
PSH 置1时请求的数据段在接收方得到后就可直接送到应用程序,而不必等到缓冲区满时才传送。
RST 置1时重建连接。如果接收到RST位时候,通常发生了某些错误。
SYN 置1时用来发起一个连接。
FIN 置1时表示发端完成发送任务。用来释放连接,表明发送方已经没有数据发送了。
另外还有 Sequence number(顺序号码) 、Acknowledge number(确认号码)在建立握手过程中发送的序列号。
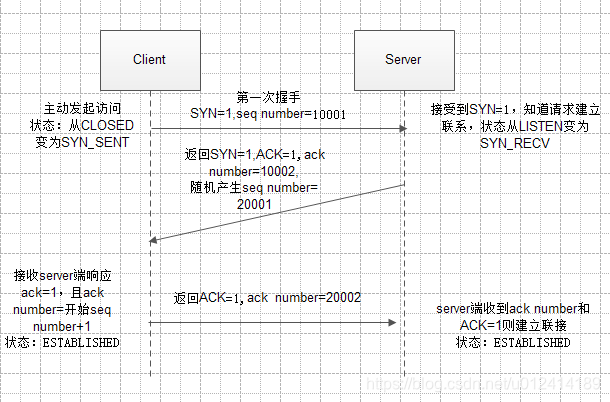
首先开始建立连接开始之前,客户端处于closed状态,服务器同样处于listen状态,客户端发送连接请求,请求内容是发送连接请求syn,以及当前连接的顺序编号seq_number,此时客户端由closed状态变成syn_send状态,
然后服务器端此时接受到发送过来的信号,发现里面有syn=1,这个时候状态从listen状态变成syn_recv状态,然后返回状态信息,包括有syn和ack确认信号,以及确认顺序号码(这个号码是发送确认号+1),同时随机在产生另外一个顺序号(seq_number)。
客户端这个时候收到服务端的响应ack=1,并且发现ack_number是之前发送的seq_number+1,这个时候认为是自己上一次发送连接请求的确认信号,这个时候从syn_send状态变成establish状态,表示连接建立,这个时候返回给服务端确认信号,其中包含的内容是ack=1,ack_number = seq_number+1。
服务器端接受到确认信号,判断ack_number和ack的状态,这个时候状态从syn_recv变成establish状态
三次握手结束。
——SYN攻击
在三次握手过程中,服务器发送SYN-ACK之后,收到客户端的ACK之前的TCP连接称为半连接(half-open connect).此时服务器处于Syn_RECV状态.当收到ACK后,服务器转入ESTABLISHED状态.
Syn攻击就是 攻击客户端 在短时间内伪造大量不存在的IP地址,向服务器不断地发送syn包,服务器回复确认包,并等待客户的确认,由于源地址是不存在的,服务器需要不断的重发直 至超时,这些伪造的SYN包将长时间占用未连接队列,正常的SYN请求被丢弃,目标系统运行缓慢,严重者引起网络堵塞甚至系统瘫痪。
Syn攻击是一个典型的DDOS攻击。检测SYN攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击.在Linux下可以如下命令检测是否被Syn攻击:
#netstat -n -p TCP | grep SYN_RECV
一般较新的TCP/IP协议栈都对这一过程进行修正来防范Syn攻击,修改tcp协议实现。主要方法有SynAttackProtect保护机制、SYN cookies技术、增加最大半连接和缩短超时时间等,但是不能完全防范syn攻击。
4、tcp的四次挥手,具体的状态画出来,分别处理哪些状态
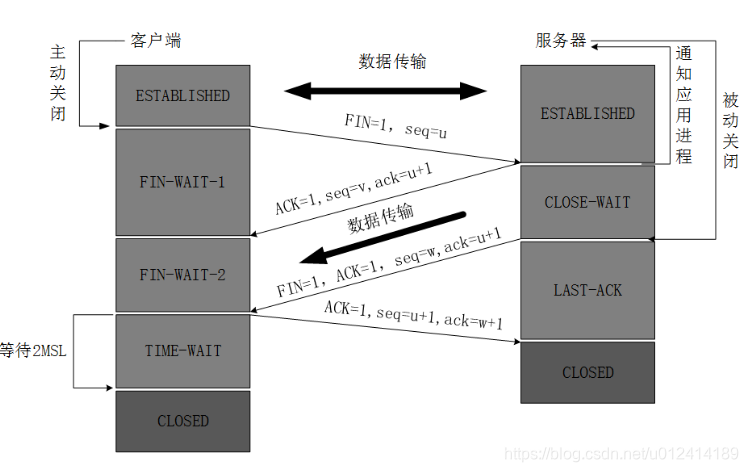
四次挥手的过程客户端和服务器都是从establish状态转换到closed状态。需要说明的是客户端和服务端都可以主动的发送关闭请求。这里也客户端来说明。
首先说明的,客户端主动发送关闭请求,请求信号包括FIN=1,seq_number = 10000(序列号随机,只是为了标记当前这个连接动作),发送关闭请求后,从establish变成fin_wait1状态
服务器端接受到关闭请求fin=1,这个时候服务器首先通知上层应用,客户端主动进行关闭,此时回复确认信号,依然按照之前的,确认信号包括ack=1,seq_number = 20000,ack_number = 10001,然后服务端从establish变成close_wait状态,
客户端收到服务器的信号,确认信号中的ack和ack_number是上次连接的确认信号,这个时候状态从fin_wait1变成fin_wait2状态,
这个时候客户端已经关闭了发送端口,但是仍然能够接受,接受服务器的数据。
服务器在close_wait状态下,等待上层应用发送关闭信号,此时服务器主动向客户端发送关闭信号,信号组成是fin=1,seq_number = 30000,ack = 20000+1,此时等待客户端的确认信号,从close_wait变成last_ack状态。
客户端这个时候接受到了确认信号,同样确认ack和ack_number是否正确,然后从fin_wait2状态变成time_wait状态,time_wait状态即等待2MSL延时(2倍的网络传输延时)即可关闭。然后回复关闭确认信号给服务端,确认信号为ack = 1,ack_number = 30001
服务器这个时候收到了这个确认信号,首先确认收到的确定信号,然后从last_ack状态变成closed状态。
客户端等待2MSL状态之后,此时没有收到服务器的重关闭信号,这个时候会从timewait状态变成closed状态。
5、四次挥手里面timewait是做什么用的,为什么要这么做
——因为虽然双方都同意关闭连接了,而且握手的4个报文也都发送完毕,按理可以直接回到CLOSED 状态(就好比从SYN_SENT 状态到ESTABLISH 状态那样),但是我们必须假想网络是不可靠的,你无法保证你(客户端)最后发送的ACK报文一定会被对方收到,就是说对方处于LAST_ACK 状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT 状态的作用就是用来重发可能丢失的ACK报文。
相同的问题还有以下两个:
1、 为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这 是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一 个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未 必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文 和FIN报文多数情况下都是分开发送的。
2、关闭TCP连接一定需要4次挥手吗?
不一定,4次挥手关闭TCP连接是最安全的做法。但在有些时候,我们不喜欢TIME_WAIT 状态(如当MSL数值设置过大导致服务器端有太多TIME_WAIT状态的TCP连接,减少这些条目数可以更快地关闭连接,为新连接释放更多资源),这时我们可以通过设置SOCKET变量的SO_LINGER标志来避免SOCKET在close()之后进入TIME_WAIT状态,这时将通过发送RST强制终止TCP连接(取代正常的TCP四次握手的终止方式)。但这并不是一个很好的主意,TIME_WAIT 对于我们来说往往是有利的
——这里就是面试官一直想让我说的,也就是说TCP关闭连接不一定需要4次挥手,可以通过设置一些参数来避免socket进入到time_wait状态,那么没有进入到time_wait状态的时候,系统会发送RST的信号强制中止当前的tcp连接,当然这种也是可以的。
那么如何设置避免进入time_wait状态呢?
在建立当前套接字的时候,设置其中的参数SO_LINGER标志,这样在对这个套接字进行close的时候,不会产生大量的timewait状态。
6、listen里面有哪些参数,分别是什么作用
——#include<sys/socket.h>
int listen(int sockfd, int backlog)
返回:0──成功, -1──失败
——
首先要明白三次握手的。当然能点进来的应该都知道什么是三次握手,这里就不废话了。
当有多个客户端一起请求的时候,服务端不可能来多少就处理多少,这样如果并发太多,就会因为性能的因素发生拥塞,然后造成雪崩。所有就搞了一个队列,先将请求放在队列里面,一个个来。socket_listen里面的第二个参数backlog就是设置这个队列的长度。如果将队列长度设置成10,那么如果有20个请求一起过来,服务端就会先放10个请求进入这个队列,因为长度只有10。然后其他的就直接拒绝。tcp协议这时候不会发送rst给客户端,这样的话客户端就会重新发送SYN,以便能进入这个队列。
如果三次握手完成了,就会将完成三次握手的请求取出来,放入另一个队列中,这样队列就空出一个位置,其他重发SYN的请求就可以进入队列中。
——所有tcp的连接实际是有两个队列,一个是未连接队列,表示当前等待连接的最大深度,还有一个已连接队列,当每成功完成一次tcp连接,就会把未连接队列上的一个连接放入到已连接队列上,对于超过未连接队列的连接,将直接拒绝连接。
7、tcp传输的信号有哪些
——主要有fin,syn,ack,sys_number,ack_number,fin_number
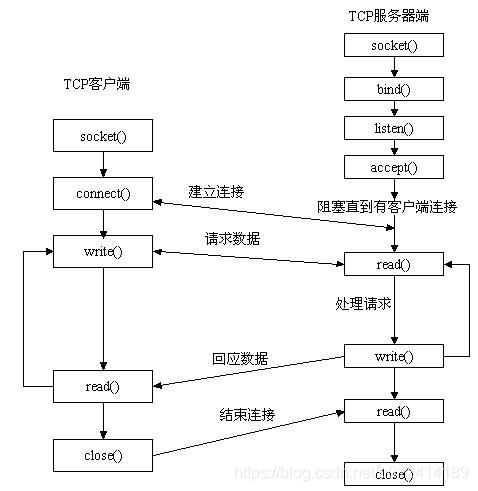
8、网络通信的套接字是怎么样的
——主要的连接如下:
(1) 建立TCP服务器的各个系统调用
——建立一个TCP服务器需要涉及到以下的几个系统调用:
——socket():开启一个套接字
——bind():绑定IP地址和端口号,注意绑定的时候,服务器一般是要主动绑定IP地址和端口号的,但是客户端一般是不需要的,因为客户端发送连接的时候,内核会自动分配一个端口号给它。
——listen():监听是否有客户端请求
——accept():阻塞进程,等待客户端的接入,接入之后产生收发的另外一个套接字,注意客户端的地址和端口号是在accept接收到的参数中找到的
——send():有客户端的接入之后,发送数据
——receive():有客户端接入之后,接收数据
——close():关闭套接字
9、分布式一致性协议用过哪些,
——
分布式一致性协议
- 二阶段提交协议(2pc)
- 三阶段提交协议(3pc)
- paxos
- zab
10、简单讲述一下paxos
——pxaos协议,paxos就是解决多个节点写入的问题,即多个节点写入一个同一个值,且被写入之后不再更改
——pxaos两个操作,一个是提议的值,一个是提议的操作
——三个角色,proposer提议的发起者,proposer提出value
——acceptors,提议的接受者,有N个proposer提出的value必须获得超过半数的acceptors批准后通过
——learner,提议学习者,将通过的value同步给其他的未确定的acceptors
——协议过程,pxaos将发起的提案value给所有的accpetors,超过半数的accpetor获得批准后,proposer将填下入acceptors,acceptors或得一致性确定的写入值,且后序不能修改
——准备阶段:proposer首先选择一个提议的编号n,向所有的acceptors进行广播,acceptors接到广播之后,如果n比之前acceptors接受到的编号都要大,那么承诺不会接受比n小的提议,
——接受阶段:如果没有超过半数的proposer接收到响应,那么转换为提议失败
——如果接收到了超过半数的承诺,又分为不同情况
——如果当前所有的acceptors都没有接收过值,那么发起自己的value值
——如果当前有部分acceptors接受过值,从所有接收过的值中选取对应提议编号最大的值最为value,但是这个时候proposer不能提议自己的值,智能信任acceptors接收的值。
——如果acceptors接收到提议之后,如果提议的版本号不等于准备阶段的版本号,就不接受请求,重新发起新的pxaos,否则接收持久化写入
11、SSD内部算法,怎么保证顺序写变成随机写的
——有人疑问,在SSD内部会把随机的数据改写顺序的数据,这样的说法正确吗?
——不正确,如果是全新的数据,那么在SSD上可以按照随机的请求顺序写入,当然也是不对的,因为SSD内部存在有多通道,数据写入要考虑到损耗均衡的问题
12、讲解一下互斥锁和自旋锁
——互斥锁没获得锁会挂起,自旋锁则是原地轮询
13、操作系统里面原子操作是什么样的,需要硬件支持吗
——原子操作指的是不可再分的指令操作,即在执行原子操作时不可能被打断,要么原子操作没有执行,要么已经执行完毕。
——原子操作的实现必须需要硬件的支持,操作系统仅仅是在硬件指令的基础之上进行一次封装。对于没有实现原子操作的硬件,则需要操作系统从软件算法层面进行支持。
————————————————————————————————————————————
网易二面:
1、linux c++中内存是怎么检测的
——现在一般使用的工具是valgrind
2、用过内存检测工具valgrind这个工具吗
——
是不是说没有一种内存检查工具能够在Linux使用呢,也不是,像开源的valgrind工具还是相当不错的
Memcheck。这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。这也是本文将重点介绍的部分。
Callgrind。它主要用来检查程序中函数调用过程中出现的问题。
Cachegrind。它主要用来检查程序中缓存使用出现的问题。
Helgrind。它主要用来检查多线程程序中出现的竞争问题。
Massif。它主要用来检查程序中堆栈使用中出现的问题。
Extension。可以利用core提供的功能,自己编写特定的内存调试工具
Memcheck
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,Memcheck 工具主要检查下面的程序错误
| 内容 | 描述 |
|---|---|
| 使用未初始化的内存 | Use of uninitialised memory |
| 使用已经释放了的内存 | Reading/writing memory after it has been free’d |
| 使用超过 malloc分配的内存空间 | Reading/writing off the end of malloc’d blocks |
| 对堆栈的非法访问 | Reading/writing inappropriate areas on the stack |
| 申请的空间是否有释放 | Memory leaks – where pointers to malloc’d blocks are lost forever |
| malloc/free/new/delete申请和释放内存的匹配 | Mismatched use of malloc/new/new [] vs free/delete/delete [] |
| src和dst的重叠 | Overlapping src and dst pointers in memcpy() and related functions |
3、了解操作系统的常见io栈吗
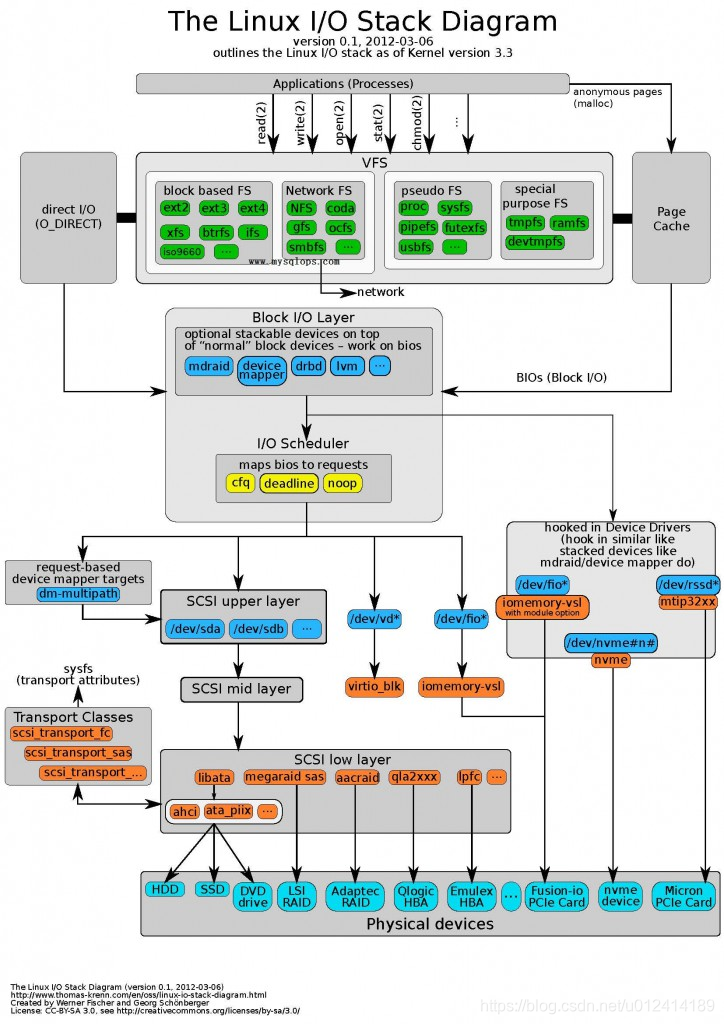
4、direct io有直接了解过吗(不经过page cache)
——从上面的图可以清楚的看到,direct io不经过pagecache直接写到block io层上
5、gdb的多线程调试熟悉吗
——没怎么用过,需要实际的去使用
6、linux下的一些监控命令知道吗,例如iostat
——iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
——vmstatvmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具
7、iostat里面的一些参数,例如iops 吞吐量,还有队列深度,这些监控指标了解吗
——命令格式:
iostat[参数][时间][次数]
命令参数:
● -C 显示CPU使用情况
● -d 显示磁盘使用情况
● -k 以 KB 为单位显示
● -m 以 M 为单位显示
● -N 显示磁盘阵列(LVM) 信息
● -n 显示NFS 使用情况
● -p[磁盘] 显示磁盘和分区的情况
● -t 显示终端和CPU的信息
● -x 显示详细信息
● -V 显示版本信息
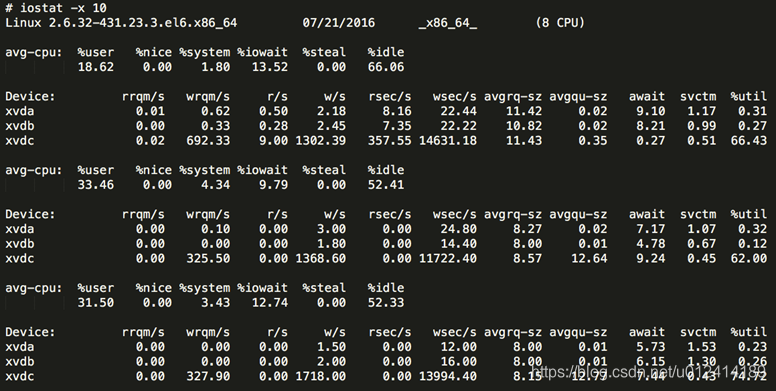
CPU 属性值
● %user:CPU处在用户模式下的时间百分比。
● %nice:CPU处在带NICE值的用户模式下的时间百分比。
● %system:CPU处在系统模式下的时间百分比。
● %iowait:CPU等待输入输出完成时间的百分比。
● %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
● %idle:CPU空闲时间百分比。
备注:
● 如果%iowait的值过高,表示硬盘存在I/O瓶颈,
● %idle值高,表示CPU较空闲,
● 如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
● %idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
磁盘每一列的含义如下:
● rrqm/s: 每秒进行 merge 的读操作数目。 即 rmerge/s
● wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
● r/s: 每秒完成的读 I/O 设备次数。 即 rio/s
● w/s: 每秒完成的写 I/O 设备次数。即 wio/s
● rsec/s: 每秒读扇区数。即 rsect/s
● wsec/s: 每秒写扇区数。即 wsect/s
● rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为扇区大小为 512 字节
● wkB/s: 每秒写 K 字节数。是 wsect/s 的一半
● avgrq-sz: 平均每次设备 I/O 操作的数据大小(扇区)
● avgqu-sz: 平均 I/O 队列长度。
● await: 平均每次设备 I/O 操作的等待时间(毫秒)
● svctm: 平均每次设备 I/O 操作的服务时间(毫秒)
● %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
备注:
● 如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
● 如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
● 如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
● 如果avgqu-sz比较大,也表示有当量io在等待。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间:
● 如果%util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈。
● svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm的增加。
● await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。一般来说 svctm < await,因为同时等待的请求的等待时间被重复计算了。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间
● 如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢
● 队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
● 如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
● 如果%util 很大,而 rkB/s 和 wkB/s 很小,一般是因为磁盘存在较多的磁盘随机读写,最好把磁盘随机读写优化成顺序读写。
8、还了解linux下面其他监控命令吗
——
Linux监控命令整理(top,free,vmstat,iostat,mpstat,sar)
Top 命令能够实时监控系统的运行状态,并且可以按照cpu、内存和执行时间进行排序
Free命令是监控系统内存最常用的命令
vmstat可以监控操作系统的进程状态、内存、虚拟内存、磁盘IO、上下文、CPU的信息。
Iostat是对系统磁盘IO操作进行监控,它的输出主要显示磁盘的读写操作的统计信息。同时给出cpu的使用情况
Mpstat可以监控到cpu的一些统计信息,在多核cpu的系统里不但能够查看所有cpu的平均状况信息,而且能够查看特定的cpu的信息
Sar命令可以全名的获取到cpu 、运行、磁盘IO、虚拟内存、内存、网络等信息。
9、数据库主要是用pgsql还是mysql,
——
一.PostgreSQL相对于MySQL的优势
1、在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
2、存储过程的功能支持要比MySQL好,具备本地缓存执行计划的能力;
3、对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
4、PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
5、PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。
6、MySQL的存储引擎插件化机制,存在锁机制复杂影响并发的问题,而PG不存在。
二、MySQL相对于PG的优势:
1、innodb的基于回滚段实现的MVCC机制,相对PG新老数据一起存放的基于XID的MVCC机制,是占优的。新老数据一起存放,需要定时触 发VACUUM,会带来多余的IO和数据库对象加锁开销,引起数据库整体的并发能力下降。而且VACUUM清理不及时,还可能会引发数据膨胀;
2、MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束;
3、MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;
4、MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大。
5、MySQL的存储引擎插件化机制,使得它的应用场景更加广泛,比如除了innodb适合事务处理场景外,myisam适合静态数据的查询场景。
三、总体上来说,开源数据库都不是很完善,商业数据库oracle在架构和功能方面都还是完善很多的。从应用场景来说,PG更加适合严格的企业应用场景(比如金融、电信、ERP、CRM),而MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)。
10、mysql的存储引擎了解吗,innnodb简单介绍下
——直接有相关的文档介绍,需要在仔细看一遍
11、索引为什么用b+树而不是用hash表
——b+树可以支持基于范围的顺序访问
12、聚集索引和非聚集索引的区别与联系
——B+树中对于聚集索引与非聚集索引,所有b+索引叶子节点都不能找到一个给定键值的具体行,是根据索引找到了被查找行所在的页,然后把这个页读入到缓存中,在内存中进行查找,最后得到查找的行。
——B+索引,将索引用b树的形式进行逻辑组织,然后用户给 一个索引,在b+树上通过二分查找去查找索引,直到目标的叶子节点匹配索引,然后读取这个叶子节点。
注意:每层的节点都是在磁盘中,都需要从磁盘读到内存中。
——对于聚集索引:叶子节点存放的是数据页信息、
——对于非聚集索引:叶子节点存放的是数据页的偏移地址,即一个书签,标明 了索引的相对行的地址。进一步理解:非聚集索引的叶子节点实际包含一个聚集索引,如果非聚集索引找不到需要的值这个时候就会通过聚集索引再去找一次。
13、abc这样的字段,怎么样选取数据库的索引,如何建立索引?
——
4、什么时候MySQL使用索引呢?
——如果某个字段的取值范围很广,几乎没有重复,即高选择性,则此时B树索引最合适
——当出现了高选择字段,同时从表中取出的行较少时,满足即可。
5、就上面的问题,那么为什么要取出行较少的时候使用索引呢?如果较多的时候则不会呢?
——因为当取的表行较多的时候,这个时候可能出现非聚集索引与聚集索引的交叉使用,这个时候造成大量的离散度,这个时候可能不如进行一个全盘的顺序读,而不是使用索引。
例如直接遍历,select一个性别。
6、那么对于select操作,数据库什么时候选择聚集索引,什么时候选择非聚集索引呢?
——innodb总是先去访问非聚集索引,因为非聚集索引效率更高,看非聚集索引的叶子节点信息中是否已经找到需要的数据,如果没有找到,还需要去访问包含的主键信息,在进行聚集索引,找到所需要的行。
——如果涉及到order排序操作的话,首先会直接选取聚集索引
——普通的查找会优先选择非聚集索引, 因为非聚集索引叶子节点存放的数据量比聚集索引多。
14、论文主要介绍的是什么
——一种闪存的数据分配算法
15、还有哪些擅长的地方
——数据库存储引擎,kv存储,分布式块存储,
16、kv存储里面主要熟悉哪些,例如memcached
——网络模型和存储模型
17、了解对象存储吗
——不太了解
总结:
1、操作系统底层io原理,内核操作还需要细看,
2、tcp网络的一下状态字还需要细看背下来,
3、linux下资源的一些监控命令需要在学习
4、gdb多线程的调试需要学习
5、paxos的一致性协议需要好好学习,类似其他的一致性协议ralft
6、数据库的上层索引建立需要自己尝试下
7、进程的加载过程
————————————————————————————————————————————
2018.8.28
商汤一面
1、vector不断的push会发生什么过程,重新扩容是怎么样扩容的
——vector不断的push,当超过了vector建立适合分配的连续大小空间,这个时候会发生扩容操作,扩容的大小是原来的两倍,然后会原来容器的数据全部拷贝到新的容器上来。
2、map的底层是怎么实现的
——底层是红黑树来实现的
3、map和的unordermap区别
——map的底层是红黑树,unordermap底层是哈希表来实现的
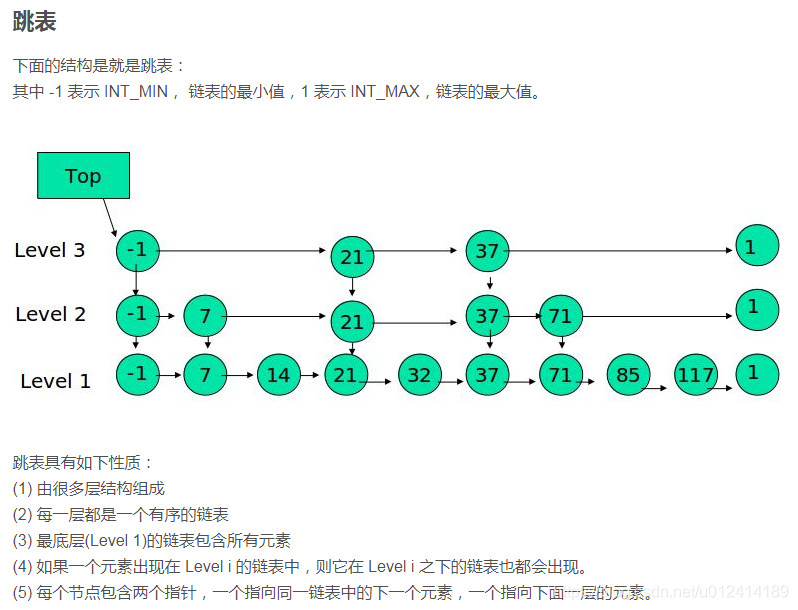
4、map底层用红黑树实现,还可以用哪些数据结构来实现
——当然还可以用avl tree实现,也可以用跳表来实现
——什么是跳表,跳表的数据结构是怎么样的?为什么要用跳表?
——跳表就是利用有序链表来完成类似树搜索的一种方法
——为什么要用,因为构造树类似的数据结构比较麻烦,使用链表的话比较简单,有序链表查找仍然是遍历,因为链表的特性是不能随机存取。
——所以跳表skiplist就是使用多重索引的结构,利用不同层次的索引,通过索引来跳过不需要遍历的节点,具体的结构如下:
5、unordermap是怎么实现扩容的,在memecached里面又是怎么实现的,两者有什么不一样的
——unordermap进行扩容是按照传统哈希表的数据结构进行扩容的,当哈希冲突的因子超过了设定的阈值时, 这个时候会进行2倍的扩容,然后做一个重新哈希的方法,将数据在哈希在新扩建的哈希表上面。
——memcached里面哈希表扩容又是怎么实现的呢?
在memcached中哈希表示用链表法来解决哈希冲突的,具体的来说就是在memcached启动的时候会通过配置文件配置一个哈希表的大小,使用常见的哈希函数,这个哈希函数将会将数据库item映射到不同的哈希桶,对于同一个哈希桶来说,数据在桶内使用链表互相连接。
——哈希冲突,memcached中哈希冲突是按照数量来设定阈值的,默认是1.5倍,即当哈希表中的item大于了哈希表的1.5倍的时候,这个时候会触发冲突的表扩容和迁移操作。和其他的操作一样,迁移操作都是很费时的,那么在memecached中是如何迁移的呢?
——迁移操作:由于迁移操作和负载处理的io是一个互斥的过程,那么为了减少这种阻塞的现象,使用的是短时间内上锁和加锁,memecached会设定一个数量值,表示单次加锁上锁迁移数据块个数,默认是一个桶,那么迁移就按照,上锁,迁移当前桶,释放锁。用户进行获得锁去执行io,通过这种方法来较少io。
——io的写入,因为存在新表和旧表,那么是数据写入时写到旧表还是新表呢,memecached的做法是,如果原来桶在旧表就插入旧表,在新表就插入到新表,便于数据块的顺序性以及方便查找。
6、c11里面熟悉智能指针吗,讲一下智能指针
——智能指针主要是分为三种,unique_ptr,shared_ptr,weak_ptr
7、智能指针里面weak_ptr是怎么用的,对于shared_ptr来说,具体怎么调用
——weak_ptr的作用是防止shared_ptr循环引用的问题,简单的例子如下:
https://blog.csdn.net/csfreebird/article/details/8281044
X对对象,AB继承类,A对象里面有B类型指针,B对象里面有A类型指针,那么对于A x这个对象,
执行完初始化,执行x->b->a = x之后,x的引用计数为2,B对象的引用计数为1,这个时候都不会为0,造成了循环引用的问题。解决办法是,将B类里面的指针换成weak_ptr指针就可以解决这个问题。
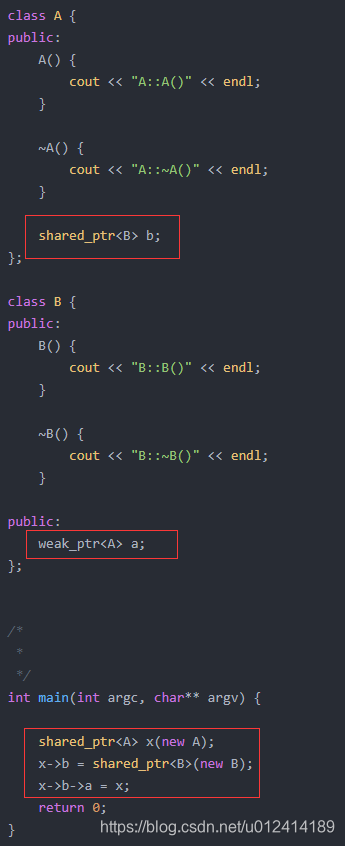
——对于第二个问题,那么weak_ptr为什么可以解决这个问题呢
weak_ptr其实是一种弱引用,对这种指针的操作都是不会对内存中的对象的引用计数+1的,类似一个普通的指针,但是这个指针区别在于他可以检测对象是否已经释放,避免指针访问非法空间。
对于上面这个例子,如果b类里面定义的是个weak__ptr指针,那么x->b->a = x操作不会导致x的引用计数+1,那么x对象引用计数为1,b对象引用计数为1,当x对象生命周期结束,x引用计数为0,被析构释放,这个时候x对象里面的b也会减1,这个b的对象引用计数为0,这个时候b也就析构了。
8、c++里面多线程了解过吗
——多线程的使用
——自己用的比较多的是,pthread_create 和pthread_exit 这个就是最简单的多线程的调用方法,在linux c语言里面也是这么用的,那么在c11里面具体的线程类是如何使用的呢?
——c11里面提供了标准的线程库,类似容器一样,线程库使用就想可以定义一个线程的对象,然后调用join/detach启动线程,前者阻塞当前主进程,后者不阻塞当前进行。
简单的例子如下:

9、讲一下c++里面怎么用多线程和锁,条件变量
——多线程使用的thread,锁使用的是mutex,条件变量cond
——在linux c里面的主要用法是pthread_cond_wait和pthread_cond_signal,一个是等待条件变量的到来,一个是向条件变量发出信号。
10、生产者消费者的模型讲解下
——生产者消费者模型就是一个典型的互斥加上同步的操作,互斥是对同一个时刻只能有一个操作资源,同时是说,只有生产者产生,消费者才能消费。

11、具体的用mutex和cond来怎么实现,调用哪些函数
In Thread1:
pthread_mutex_lock(&m_mutex);
pthread_cond_wait(&m_cond,&m_mutex);
pthread_mutex_unlock(&m_mutex);
In Thread2:
pthread_mutex_lock(&m_mutex);
pthread_cond_signal(&m_cond);
pthread_mutex_unlock(&m_mutex);
12、cond调用的时候判断信号量,是用if还是用while
——必须使用while,因为可能前一个判断条件导致进入了等待条件变量的状态,这个时候只要条件变量到来就会立即执行,但是事实并不是这样,使用while可以在进行一次判断,避免这种现象。
——可能确实这个被唤醒,但是此时队列的元素被其他的拿走了,那么这种情况还是需要继续判断的,所以使用while是正确的。

13、vector里面删除偶数是如何做到的
——遍历一遍删除即可
14、锁是每次都lock和unlock吗,有了解过c++里面的raii吗
——使用锁都是mutex mu,mu.lock()即可。
——RAII:资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源。因为C++的语言机制保证了,当一个对象创建的时候,自动调用构造函数,当对象超出作用域的时候会自动调用析构函数。所以,在RAII的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定。
所以使用这种机制,可以在类对象构造函数里面上锁,在类的析构函数里面下锁,通过这种方法完成对对象资源的锁。
15、说下线程池和线程的区别
——线程池就是一次性创建,为了减少中途创建线程的一些开销。
16、命令队列的具体实现
——实际就是一个生产者消费者的模型。
17、项目缓存管理是如何管理的,简单说下LRU的实现
18、分布式块存储是如何实现分布式的
——数据一致性写入
——数据分布式路由
——数据多副本
——数据分布式协议,二段式,三段式,paxos
19、一致性hash是怎么样的
——一致性哈希是为了数据均匀分布完成的,通过将数据块映射到对应的哈希环上,按照顺时针找到对应的节点。
20、一致性hash可以保证高可靠性吗
——不能保证,一致性hash只是完成的数据的均匀分布。
21、分布式里面高可靠性是如何保证的
——副本,多副本的一致性写入保证的
22、副本的同步写是怎么样的
——同步写分为两种,一种是同步写,一种是异步写。
23、一致性协议了解那些吗
——两段式提交协议,三段式提交协议,paxos协议
24、paxos里面活锁问题是怎么样的,如何避免的
——什么是活锁:Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。
——解决办法1:为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致,此时的paxos算法在本质上就退变为两阶段提交协议。
——解决办法2:解决活锁用得方法一般是随机定时器啊。当发现冲突后,不同的提交者随机休眠一段时间,然后再次申请。
25、简单算法,atoi的实现,字符串转换为整型,如果字符串越界整型,是如何检测
26、深度学习平台,海量小文件的对象存储
————————————————————————————————————————————
2018.8.29
拼多多三面:
1、对工作地的看法
2、目前手头上有哪些offer,分别在哪些城市
3、对于北京,上海,杭州,深圳工作考虑的优先级
5、对于拼多多这个公司的了解
6、对于自己以后的发展是如何看待的
7、工作的加班如何看待
————————————————————————————————————————————
wps三面:
1、基本工资待遇
3、对大学室友的看法
4、对工作地的看法
5、薪资结构
6、加班的情况
7、其它福利待遇
————————————————————————————————————————————
2018.9.1
阿里二面:
1、算法:原地反转单词,有序链表的归并
2、个人项目,项目里面agent是多长时间采样的,采样的数据直接写入到数据库会不会导致数据库压力太大。
3、数据库和采样之间的压力控制怎么完成的
4、你们是怎么对性能进行预估分析的
5、采用时间是多久,数据库采样清空操作时间又是多久
6、这样是一个固定的时间,没有做自动化的工具吗
7、闪存数据库的项目,讲讲什么是已读换写的原则
8、数据库里面冷热你是怎么分别的,用的LRU,有尝试过其他区分冷热的方法吗
9、一些新型的数据库,Rockdb这一类数据库会把随机的写变成顺序写,这一类你是怎么完成的?
——这一类数据库暂时还没有很了解
10、memcached里面内存时怎么划分的
——各个Slab按需动态分配一个page的内存(和4Kpage的概念不同,这里默认page为1M),page内部按照不同slab class的尺寸再划分为内存chunk供服务器存储KV键值对使用
11、内存划分块的大小比例是多少,还记得吗
——以前是一个固定的大小2倍,以两倍的大小进行递增
——现在的增加了growth factor的选项,即可以按1.25设置进行增长
12、redis有了解吗
——了解redis和memecached的区别,主要是以下三点:
——Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储
——redis支持数据的备份(Redis内建支持两种持久化方案,snapshot快照和AOF 增量Log方式。快照顾名思义就是隔一段时间将完整的数据Dump下来存储在文件中。AOF增量Log则是记录对数据的修改操作(实际上记录的就是每个对数据产生修改的命令本身))
——redis可以持久化数据,因此故障可以恢复
——redis支持虚拟化技术,内存数据不够的时候和磁盘的数据进行一个交换
——redis支持事务的一些操作
13、hadoop,spark这些平台有了解过吗
——没有
————————————————————————————————————————————
2018.9.3
快手一面:
1、项目
2、算法题:
——整数的反转,
——给出一个整数,给一个单项整数链表,要求求出链表中三个数字,这三个数字之和等于最初给出的整数。
3、网络的7层模型
——增加了会话层和表示层,分别是物理层,链路层,网络层,传输层,会话层,表示层,应用层
——会话层:通过传输层建立数据传输的通路。主要在系统之间发起会话或者接收会话请求。
——表示层:主要进行对接收数据的解释、加密与解密、压缩与解压缩。确保一个系统的应用层发送的数据能被另一个系统的应用层识别。
4、网络中的NAT arp的含义
——NAT是网络地址转换(Network Address Translation),将内部的网络地址转化为公网唯一的IP地址,一般是有发现公网的路由器来完成这个转换过程的。
——它是一种把内部私有网络地址(IP地址)翻译成合法网络IP地址的技术。NAT 可以让那些使用私有地址的内部网络连接到Internet或其它IP网络上。NAT路由器在将内部网络的数据包发送到公用网络时,在IP包的报头把私有地址转换成合法的IP地址。
5、文件系统中的inode的含义
——文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。包含:
- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode
- 文件数据block的位置
6、IO栈了解吗
——说的就是三个图
————————————————————————————————————————————
快手二面:
1、项目
2、分布式二段式提交协议
——两段式协议主要是解决分布式事务的问题,多个机器就某个事务达成一致。
——它主要有两个阶段,一个是请求阶段,一个提交阶段。
——在请求阶段:系统中唯一存在的协调者将通知事务的参与者当前的事务,并阻塞等待参与者对于这个事务提交的决策,即同意当前事务,或者不同意当前事务。
——在提交阶段,协调者会对所有参与者的投票结果进行一个决策,最后给出结果是提交或者取消。然后将提交的结果发送给所有的参与者执行。
——存在的问题:
1、同步阻塞问题:当参与者占有公有资源的时候,参与者等待最终的决策结果,所以会一直阻塞
2、单点故障:协调者在整个协议中是唯一的,一旦协调者挂了,参与者会一直阻塞下去,造成严重的单点问题。
3、数据不一致,当参与者接收了执行请求,但是可能由于网络的原因,但是只有一部分参与者得到的执行,这个时候会导致不是所有的参与者都正确的写入数据,这就是数据的不一致。
——无法解决的问题:
1、如果协调者和参与者都出错,显然是无法执行一致性的
2、单点问题,即使选举出来了另外一个协调者,但是由于当前参与者仍然在阻塞状态,这个时候当前这一条的事务状态相当于没有了,只能完全回滚,在进行一次完整的两段式提交协议。
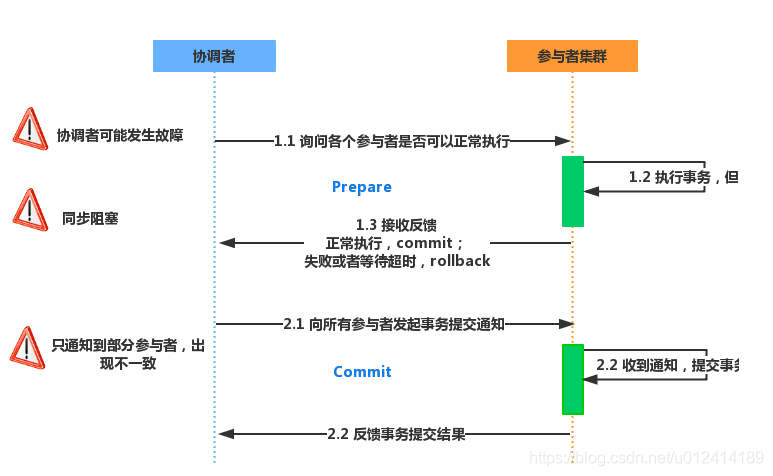
注意在准备阶段是执行事务,但是没有提交,事务还没有提交所有是随机可以回滚的。
3、分布式两段式提交协议中单点问题如何解决的
——二段式协议中单点问题是无法解决的,所以为了解决二段式提交的问题出现了三段式提交
——三段式提交相比二段式提交增加了两个不同:
三阶段提交协议在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段拆分成了两步:询问,然后再锁资源,最后真正提交。
——1.CanCommit阶段:协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。,注意是预估判断是不是可以执行,并没有执行当前的事务
——2.PreCommit阶段:A.假如Coordinator从所有的Cohort获得的反馈都是Yes响应,那么就会进行事务的预执行,B.假如有任何一个Cohort向Coordinator发送了No响应,或者等待超时之后,Coordinator都没有接到Cohort的响应,那么就中断事务:发送中断请求。
——3.DoCommit阶段:发送提交请求。A:执行提交,Coordinator接收到Cohort发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有Cohort发送doCommit请求。B,中断事务,Coordinator没有接收到Cohort发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
——三阶段提交协议和两阶段提交协议的不同
对于协调者(Coordinator)和参与者(Cohort)都设置了超时机制(在2PC中,只有协调者拥有超时机制,即如果在一定时间内没有收到cohort的消息则默认失败)。
在2PC的准备阶段和提交阶段之间,插入预提交阶段,使3PC拥有CanCommit、PreCommit、DoCommit三个阶段。
PreCommit是一个缓冲,保证了在最后提交阶段之前各参与节点的状态是一致的。
——三阶段提交协议的缺点
如果进入PreCommit后,Coordinator发出的是abort请求,假设只有一个Cohort收到并进行了abort操作,而其他对于系统状态未知的Cohort会根据3PC选择继续Commit,此时系统状态发生不一致性。
4、常用的主备的问题能不能解决上面的单点问题
——不能,因为当前的事务状态是未知的,只能回滚,再重新进行事务的提交
5、解释下paxos协议
——前面有解释
6、Linux Io栈中pagecache脏页什么时候被写回
——pagecache写回的时候主要是三个情况,一个是cache满的时候写回,一个是断点的时候写回,一个是快照的时候写回。这是自己对于cache的理解写回。
——在linux内核中操作pagecache的写回是通过以下的方法完成的:
调用fsync等。主动调用fsync,那么可以主动将脏页持久化
脏页太多(相关参数:dirty_background_ratio与dirty_ratio),按照脏页的数量比例定时刷新
脏页太久(相关参数:dirty_expire_centisecs)。按照脏页固定时间进行一次刷新写回操作
7、讲一下快照的ROW和COW的区别
——一个是写时复制,写性能较低,读性能较好
——一个是写时重定向,顺序读变成了随机读,读性能较差,但是写性能较好
8、你有什么想问我的
9、算法,两个链表的公共节点
——如果只用判断的话,只用去判断尾节点即可
10、

——两种方法,第一种方法是求出所有的区间,对区间计数
——第二种方法是类似dp,dp[i] = dp[i-1] + 第i秒打卡的人- 第i秒离卡的人
————————————————————————————————————————————
快手三面:
1、对一面二面官的感受
2、中间面试有遇到过什么问题
3、未来的工作城市计划
4、现在面试有拿到其它公司的offer吗
5、公司的对于新人的培训的态度是什么样的
6、预计结果九月中旬出来
————————————————————————————————————————————
科大讯飞一面:
1、cpp里面const的用法,const可以和static一起使用吗
——const的用法主要有三个:
——直接修饰变量,就是向编译器指明这个变量是常量属性,不可修改
——在修饰指针变量的时候,就有两种,const intp = &a; 代表这个指针指向的对象是常量,指针本身是变量,另外一种是int const p = &d,表示这个指针本身是常量,指向的数据是可以被修改的。
当然,如果是const int* const a,这种就是指针本身和指向的对象都是常量。
——const用来修饰函数,表示这是个常成员函数,例如int funa() const,这种对于常成员函数,无论是声明还是定义,都需要加const限定,常成员函数可以访问const数据成员,也可以访问非const数据成员,注意是只是访问,但不可以修改。反过来,const数据成员可以被const成员函数访问,也可以被非const的成员函数访问。对于const int funa(),这种就比较好理解了,函数的返回值为常量,即函数只允许只读,不能写返回值。
——const的对象的常引用,在c++ 中,经常用对象的常指针和常引用作为函数参数,这样既能保证数据的安全,是的数据在函数中不能被任意修改,能再点用函数不必传递实参对象的副本,大幅度减少函数调用的空间和时间的开销。类似,void f2 (const int &d)
——不可以。C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
2、cpp里面数组的传参数,参数的大小
——这里说的cpp传参数指的是传了一个数组,数组名实际是数组中第一个元素的地址,也就是这个数组的首地址,那么地址的大小就取决于当前机器码大小,32位机器是4byte,64机器就是8byte
3、cpp里面用过c11的那些特性
——STL的容器,智能指针,模板
4、析构函数为什么要设置虚函数
——先析构子类,再去析构父类
5、c11里面容器了解吗,说下vector和list的区别
6、哈希表用过吗,哈希表是在怎么解决哈希冲突的
——开放式地址寻址,链表法
7、哈希函数有了解过吗
——常用的是SHA系列,例如SHA1,SHA2,SHA3,SHA4这些
——还有一个就是MD5,用来做校验文件是否有被修改过
8、多线程之间是怎么同步的,有了解过吗
——linux上的多线程使用的同步方法有互斥锁+条件变量
——最经典的就是生产者消费者的同步问题,命令队列的同步
9、windows上多线程的同步,事件有了解过吗
——主要思想是,会定义同一个事件,会有一个等待事件的函数,这个函数会等待事件到达某个状态,不同的线程等待时间状态不一样,从而完成一个同步。
例如:
#include<string>
#include<iostream>
#include<process.h>
#include<windows.h>
using namespace std;
//声明3个事件句柄
HANDLE hev1, hev2, hev3;
//线程绑定的函数返回值和参数是确定的,而且一定要__stdcall
unsigned __stdcall threadFunA(void *)
{
for(int i = 0; i < 10; i++){
WaitForSingleObject(hev1, INFINITE);//等待事件1
cout<<"A";
SetEvent(hev2);//触发事件2
}
return 1;
}
unsigned __stdcall threadFunB(void *)
{
for(int i = 0; i < 10; i++){
WaitForSingleObject(hev2, INFINITE);//等待事件2
cout<<"B";
SetEvent(hev3);//触发事件3
}
return 2;
}
unsigned __stdcall threadFunC(void *)
{
for(int i = 0; i < 10; i++){
WaitForSingleObject(hev3, INFINITE);//等待事件3
cout<<"C";
SetEvent(hev1);//触发事件1
}
return 3;
}
int main()
{
hev1 = CreateEvent(NULL, FALSE, FALSE, NULL);
hev2 = CreateEvent(NULL, FALSE, FALSE, NULL);
hev3 = CreateEvent(NULL, FALSE, FALSE, NULL);
SetEvent(hev1);//触发事件1,从A开始打印
HANDLE hth1, hth2, hth3;
//创建线程
hth1 = (HANDLE)_beginthreadex(NULL, 0, threadFunA, NULL, 0, NULL);
hth2 = (HANDLE)_beginthreadex(NULL, 0, threadFunB, NULL, 0, NULL);
hth3 = (HANDLE)_beginthreadex(NULL, 0, threadFunC, NULL, 0, NULL);
//等待子线程结束
WaitForSingleObject(hth1, INFINITE);
WaitForSingleObject(hth2, INFINITE);
WaitForSingleObject(hth3, INFINITE);
//一定要记得关闭线程句柄
CloseHandle(hth1);
CloseHandle(hth2);
CloseHandle(hth3);
//删除事件
CloseHandle(hev1);
CloseHandle(hev2);
CloseHandle(hev3);
}
10、线程安全里面的可重入函数有了解吗
——线程安全:
一般来讲就是一个代码块被多个并发线程反复调用时会一直产生正确的结果。
线程安全问题都是由全局变量及静态变量引起的。任何未使用静态数据或其他共享资源的函数都是线程安全的。而使用全局变量或静态局部变量的函数是非线程安全的。
使用静态数据或其他共享资源的函数,必须通过加锁的方式来使函数实现线程安全。
线程安全函数解决多个线程调用函数时访问共享资源的冲突问题。
可重入函数:
1、函数被不同的控制流程调用,有可能在第一次调用还没返回时就再次有别的线程进入该函 数,这称为重入
2、访问时有可能因为重入而造成错乱,像这样的函数称为 不可重入函数,反之,如果一个函数只访问自己的局部变量或参数,则称为可重入函数。
3…可重入函数特点: 函数可以由多于一个线程并发使用,而不必担心数据错误。可重入函数可以在任意时刻被中断,稍后再继续运行,不会发生数据错误。
可重入函数的条件:
1.不在函数内部使用静态或全局数据
2.不返回静态或全局数据,所有数据都有函数的调用者提供
3.使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据
4.不调用不可重入函数
可重入函数和线程安全的关系和区别:
可重入函数与线程安全并不相同,一般来说,可重入的函数一定是线程安全的,但反过来不一定成立,关系可由下图解释:

(1)如果一个函数中不加锁的用到了全局或静态变量,那么它不是线程安全的,也不是可重入的
(2)如果我们对它加以改进,在访问全局或静态变量时使用互斥量或信号量等方式加锁,则可以使它变成线程安全的,但此时它仍然是不可重入的,
因为通常加锁方式是针对不同 线程的访问,而对同一线程可能出现问题;
(3)如果将函数中的全局或静态变量去掉,改成函数参数等其他形式,则有可能使函数变成既线程安全,又可重入
记住:
1.可重入概念只和函数访问的变量类型有关,和是否使用锁没有关系。
2.而线程安全和锁的使用关系密切,很多时候线程安全是靠锁来保证的
11、linux里面怎么看一个进程的资源
——ps 找到进程的pid,然后top | grep pid,显示的就是对应进程的一些资源
12、linux里面怎么编辑日志
——编辑日志,vim,nano ,cat
13、linux里面怎么同步差异数字
——comm 和diff两个命令,前者是显示两个文件相同的行,后者是显示两个文件不同的行
14、c11里面的智能指针有了解过吗,讲下三种智能指针的区别
——unique_ptr,shared_ptr,weak_ptr
15、tcp的服务端开发是怎么样的
——socket,bind,listen,accecpt, read , write, close
16、多客户端连接服务端是怎么完成的
——服务端同一个端口号可以监听多个客户端的连接,因为实际有连接通道的是socket,而socket套接字的标识有以下几个部门组成:
——1. 端口只是一个数字辨识,不是真正的物理端口;
2. 一个Socket连接的主键(即不同socket之间的区分)是由一个==五元组{SRC-IP, SRC-PORT, DEST-IP, DEST-PORT, PROTOCOL}组成,即{源地址,源端口,目标地址,目标端口,协议}组成,那些说四元组不包含协议的说法是错误的。 ==
3. 一个进程可以拥有多个socket连接。
例子一、两个客户端连接在同个服务器的同个端口80,即有两个socket连接:
- socket1 {SRC-A, 100, DEST-X,80, TCP}
- socket2{SRC-B, 100, DEST-X,80, TCP}
主机A和主机B的地址不同,两台主机同时连接到服务器X的80端口。服务器要怎么处理这个连接是它的事,我们要理解的是为什么一个主机同个端口能监听多个客户端Socket连接。
解释:
- 是因为两个客户端的IP不同,服务器能识别出不同的Socket;
- 即使IP地址相同,端口不同,服务器也能够分辨;
- 只要服务器知道收到的请求和哪个socket相关,那么它就能使用这个socket正确地回复那个客户端;
- 如果对于不同的socket需要不同的端口,那么不仅仅浪费服务器资源,而且每次客户端连接上serverSocket之后还要另外分配新的端口和客户端通信。没必要。
正是由于这种特性,所以同一个进程可以监听多个客户端的连接,可以使用io复用的一些操作select/poll/epoll这些操作。
——总结:
● 不同协议可以监听同一个端口(不管是不是在服务器的同个进程)
● 某个协议的进程可以监听多个客户端的连接,因为只要五元组不同进程就能分辨。
● 从上面的例子可以知道,客户端同个进程也可以在同个端口用不同的协议与客户端建立连接。
17、tcp是如何保证可靠传输的,在已经建立连接传输的过程中
——第一个是通过传输数据的序列号来完成的,比如seq=10000,返回的确认信号ack=10000+1,如果再一段时间内没有接收到,会进行超时重传。
——第二个通过滑动窗口机制来完成的,滑动窗口 一次性发送窗口内的所有数据包,那么整个窗口必须按照有序的回复ack信号进行 移动,例如如果5、6号包返回了,但是2号包还没有返回,这个时候会去等待2号包的返回。
18、网络滑动窗口具体是怎么样的
——一个是保证可靠传输,一个是滑动窗口大小的调整,就是拥塞窗口
————————————————————————————————————————————
依图二面:
1、项目
2、cpp中虚函数的介绍
——在cpp里面,虚函数主要有两种,一种是静态多态,一种是动态多态,动态的多态主要是由虚函数完成的。
3、cpp中堆栈的介绍
——局部变量,堆中变量的生命周期由程序员自己控制
4、cpp中智能指针是什么样的,有了解吗
——主要有三个指针,一个是unique_ptr,一个是shared_ptr,一个是weak_ptr
5、智能指针和普通的指针有什么区别
——智能指针更多的是为了避免普通指针出现的类似野指针的情况。
——普通指针最容易出现三种现象:野指针,悬空指针
——野指针是指那些没有初始化的指针
——悬空指针是指当前指针指向的内存已经被释放了,那么这个指针就变成了悬空指针
6、网络传输用的什么协议
——TCP
7、tcp的packet你们是怎么定义的
——自己定义的
8、除了华为的分布式存储系统,还了解哪些分布式的系统
——ceph
9、fusionstorage和ceph有什么区别
——计算路由的区别
——存储池的区别
——元数据管理的区别
10、有了解过其他分布式系统,memcached redis,tail,dynamo
11、hdfs hadoop有了解过吗
12、以后自己未来的从事方向
13、对云平台的看法
————————————————————————————————————————————
2018.9.12
美团一面:
1、项目
2、cpp里面指针的介绍
3、cpp里面vector和list的区别介绍
4、连续数据分配为什么可以随机寻址
5、项目中遇到的最大难点
6、调试如何做到的
美团二面:
1、项目
2、操作系统知识,线程和进程的区别
3、进程之间的通信方式
4、多线程的自加操作,可能出现的可能性
5、tcp网络通信里面如何处理高并发的
6、select和epoll的区别
7、算法:atoi的实现,注意很多边界条件
招银网络科技一面:
1、cpp里面三种特性,封装继承多态,分别适用于哪些应用场景
2、虚函数的底层实现
3、const define inline的区别联系
——a、inline定义的内联函数,函数代码被放入符号表中,在使用时直接替换,没有调用的开销,效率高。
b、类的内联函数是一个真正的函数,所以编译器在调用内联函数是,首先会检查它的参数类型,保证调用正确;然后进行一系列相关检查,就像对待真正的函数一样。这样可以消除他的安全隐患。
c、inline可以作为某个类的成员函数,因此可以在其中使用所在类的保护成员及私有成员。
3、inline的缺点
inline是以代码膨胀为代价的,每一处内联函数的调用都会复制代码,会使程序的代码量增大,消耗更多的内存。所以不要随便的将构造函数和析构函数放在类的声明中。
4、define和inline的区别
——1、内联在函数编译时展开,而宏在预编译时展开。
2、编译时,内联函数可以直接被镶嵌到目标代码中,而宏定义只是一个简单的文本替换。
3、内联函数可以完成类型检查、语句是否正确等编译功能,宏定义则不可以。(宏定义不是函数,inline是函数)。
5、设计模式有了解过吗
——讲解下常见的设计模式,单利模式,装饰着模式,观察者模式,适配器模式
6、关系型数据库和非关系数据库的区别,分别有哪些
——关系型数据库主要是存放结构化数据,非关系型数据库主要存放非结构化数据
——常见的关系型数据库有mysql,pgsql,oracle等,菲关系型数据库有memcache,redis,leveldb,mongodb,rockdb这些。
7、数据库的索引是怎么划分的
——聚集索引和非聚集索引,一个是叶子节点为数据,一个叶子节点为指针
8、http和https有什么不同
——https协议需要到ca申请证书,一般免费证书很少,需要交费。
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的。
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
————————————————————————————————————————————
2018.9.13
美团三面:
1、项目问题
2、实习工作
3、fusionstorage和ceph,s3的优缺点,以及他们之间的比较
4、介绍一个你认为最好的项目
5、项目中的难点,实用价值
6、算法题:乱序书架还原成为升序
美团hr面:
1、项目介绍
2、对基础架构的了解
3、对于公司的了解
4、自己发展最看中什么
5、觉得比自己的人有哪些好点
6、几年内觉得自己能成为行业的大牛
7、公司是否有部门墙
8、公司是怎么样培训新人的?
追一科技一面:
1、简单介绍下项目
2、项目主要负责什么
3、缓存替换算法优化主要优化什么
4、SSD内部垃圾回收制度怎么样的,如何减少寿命
5、SSD内部的并行操作又是怎么样的
————————————————————————————————————————————
2018.9.15
科大讯飞一面:
1、项目中的最难点
2、SSD和HDD的区别联系
3、SSD的写放大是怎么一回事
4、以后的职业规划
5、工作地的选择
————————————————————————————————————————————
2018.9.17
华为终面:
1、如何选择工作地
2、为什么选择消费者bg
————————————————————————————————————————————
2018.9.18
海康一面:
1、全程项目
2、每个项目都问到
海康二面:
1、觉得最好的项目
2、项目的难点
3、说出两个你的优点和缺点
4、薪资福利
————————————————————————————————————————————
2018.9.19
绿盟一面:
1、SSD和HDD的区别
2、传统数据库针对HDD有哪些优化
3、kv存储有哪些
4、memcached的主要结构介绍一些
5、memcached的进程模型,网络模型,存储模型
6、进程模型中多进程多线程是如何保证的
7、网路模型中异步和同步的优缺点
8、如何去监控一个进程的状态
9、如何保证自己写的进程,程序是最优的
10、内存泄漏时如何检测的
11、那么在c语言里面自己是如何检测内存泄漏的,除了用工具
绿盟二面:
1、实习项目介绍
2、人生
3、有没有对安全有所了解
————————————————————————————————————————————
2018.9.20
360企业安全一面:
1、项目
2、文件系统的数据是怎么存储在HDD上面的
3、用SSD存储和HDD存储有什么异同点
4、算法,手写遍历二叉树
360企业安全二面:
1、讲讲项目
2、讲讲你了解的kv存储
3、讲讲memcached redis leveldb boatdb的常见应用场景
4、用一句话介绍你所学习的内容
360企业安全三面:
1、讲解下所做的项目
2、实习的主要工作内容
3、项目的分布式存储系统各ceph的优缺点及不同点
4、项目中存储节点代理是收集哪些数据
5、代码的程序是你自己写的吗,还是说用的别人的
6、你们的代理主要监控哪些数据,如果给你自己,你应该如何监控
7、代理的采集的数据时间是多少,这样采集间隔是最优的吗,这样采集会出现哪些问题
8、数据库查询操作代码写一下
9、你分析数据主要是分析哪一些
10、能简单介绍下方差是什么样的吗,用最直白的方法
11、操作系统的考察,分页,内存和磁盘的比较
12、网络的考察,dns协议,网络五层协议,应用层知道有哪些协议
13、进程从数据库里面读写数据,是用的什么网络协议
14、tcp三次握手是什么样的
15、tcp三次握手的状态分别是什么样的
16、你对平台的理解
17、你对IAAS的理解
18、熟悉一些网络安全吗
19、对公司业务的介绍
————————————————————————————————————————————
2018.9.26
腾讯一面:
1、项目介绍
2、闪存数据库的项目介绍
3、select和epoll的区别
4、手撕反转链表
5、具体的业务是什么
2018.9.27
迅雷一面:
1、项目指标
2、hdd ssd 内存 cache的延时
3、select和epoll的区别
4、网络通信的多路复用的知识
5、分布式项目
6、一致性哈希环的讲解
7、pgsql数据库的读写延时
8、团队合作的业务场景
9、对自己的之后从事的方向有什么想法
10、迅雷这边主要业务是区块链和共享云计算
————————————————————————————————————————————
2018.9.29
腾讯二面:
分布式知识:
1、为什么要做分布式
2、分布式相比单机有什么好处
3、分布式存储和普通的存储在哪里有问题
4、分布式系统中CAP的概念
5、如果给予多的高可靠性,那么他的可用性就会下降,那么这种问题如何解决?
6、可靠性的保证是使用强一致性,那么强一致性会导致哪些问题
7、如果出现这种问题,使用最终一致性来解决
8、最终一致性,保证数据的写入中间不是一致性,那么这些数据在读的时候就会不一致,那么如何解决这些问题呢?
9、项目里面使用的强一致性,那么当某个副本没有成功写入的时候,这个时候读取的数据就不一致了,不一致如何解决的呢?
10、read repair操作每次会去比较三个副本里面的数据,这样做不是会很耗时吗
操作系统知识:
1、给你两个进程,进程a和进程b,进程a用new开辟的内存首地址是pa,进程b用new开辟的内存首地址是pb,pb可以等于pa吗,他们开辟的内存可以是同一块内存空间吗?
2、23位机器上进程最大地址空间多大
3、系统调用了解吗,什么是系统调用,举个例子
4、open和fopen的区别
5、什么是内联函数,哪些函数应该设置为内联函数
6、内联函数和普通函数相比,有哪些优点
7、什么是缓冲区溢出
8、对于数组的缓冲溢出,解释下缓冲区的溢出
9、访问非法空间和访问其他数据异常,这两种情况分别介绍下
10、怎么去用代码检测这两种情况的发生
网络知识:
1、网络里面有个SO_REUSEADDR 指令,这个指令有什么作用?
2、网络通信如果多个进程共用一个端口号,那么这个端口号发送的数据,怎么分辨是达到哪个进程呢?
linux系统的相关知识:
1、crontb命令听说过吗
2、linux里面一般使用哪些命令
数据库:
1、数据库了解吗
2、innodb和myisam相比,有哪些好处坏处
————————————————————————————————————————————
迅雷二面:
1、项目
2、讲下c语言里面数组在内存中的分布
3、讲下分布式里面一致性哈希的概念
4、给你出个算法题目,12个球,一个天平,最快找出其中一个不一样的球
5、共享云计算和区块链的区别联系
迅雷三面:
1、项目
2、实习主要学习到了什么
3、为什么不去实习公司
4、介绍下迅雷的一些业务
5、迅雷工作的一些氛围
6、拿到了哪些offer
7、工作考虑点在哪些