谈到HashMap和ConcurrentHashMap,必然会联想到一些其他集合结构,比如HashTable,Vector等,先理一下他们的区别吧。其实HashTable和Vector已经被废弃了,HashTable和Vector以及ConcurrentHashMap都是线程安全的同步结构,区别是HashTable和Vector是采用synchronized关键字对整个集合对象加锁,效率低下。而ConcurrentHashMap则是采用分段加锁的方式细化了锁的颗粒度,由于高效率所以替代了前两者。但是HashMap是线程不安全的,至于为什么线程不安全下文会有详解,先比较一下两个版本中HashMap和ConcurrentHashMap有什么改变。
一.HashMap
1.JDK1.7中
HashMap本质上是一个Entry数组,Entry中即为键值对,Entry数组在table中的位置是这么计算出来的:
int hash = hash(key.hashCode());
int index = indexFor(hash,table.length);大致是根据key对象的hashcode值,即key对象的内存地址值,通过hash算法得到一个hash值,这里很清晰的可以看出hashcode值和hash值是两个东西两个概念不要混淆。得到hash值后,再结合数组table的长度计算出数组下标,这里贴出两个算法内容,即hash算法hash()以及位置算法indexFor()。
static final hash(Object key){
int h;
return (key == null)?0:(h = key.hashcode()^(h >> 16));
}我也不太清楚这里h>>16是什么意思,不过ConcurrentHashMap默认线程并发量是16,是不是有关系呢?
static int indexFor(int h,int length){
return h & (length - 1);
}这里有一个设计很巧妙的地方,关于为什么HashMap的长度包括扩容后的长度都是2的次方这个问题,这个indexFor方法逻辑给出了答案。因为2的次方减一即(length - 1)得到的数其二进制样式差不多,前面有多少个0不一定,但后面一定是连续的1。比如(2-1)的二进制是000001,(2的三次方-1)的二进制是000111。而&(与运算)原则是有0就是0,都是1才是1。想象一下,比如000111这种二进制参与与运算,前三位即0的位置不管另一个二进制上对应位是什么都是0,即一种情况,而后三位即1的那位得看另一个二进制对应位置上是什么,即两种情况。很好理解,1越多,情况越多,即求出来的数组下标可能性越多,即散列越均匀,形成的链表越少,查询效率越高。理解这个小知识点很重要。
好像有点扯远了,再回来看JDK1.7中HashMap的结构,通过前文也可以看出来,如果两个key计算出来的数组下标index相同,那么这两个Entry会在该位置上形成链表,结构可以这么画:

HashMap的get(key)方法就是根据key求出数组下标,还是那一套,如果那个位置没有链表,直接返回value,如果有链表就遍历链表拿到value。这里有个地方容易模糊,哪怕这个key在HashMap中不存在,也是可以根据这个key求出一个数组下标index的,只不过根据这个key拿value的时候为null。
HashMap的put方法就是根据负载因子和数组长度先判断需不需要扩容 ,注意,因为扩容后的table的长度就变了嘛,而每个Entry的数组下标位置和table的长度有关,所以扩容后会重新计算这些Entry的数组下标位置,可以理解为全部重新放了一遍,空间大了整理一下位置,整理好后就可以继续往里面PUT东西了,还是那套,先根据key计算出index值,判断key存在不存在,存在就覆盖不存在就添加。
这里可以再补充一个知识点,关于为什么HashMap不是线程安全的呢?因为put没有加锁,最终结果是某个位置上的Entry可能形成链表。知道多线程下有这个结果就行,至于为什么会形成链表过程有点复杂暂且不论。如果某个位置上的Entry可能形成链表,get(key)的时候根据这个key计算出来的位置刚好是这个环形链表的位置,更不巧的是没有这个key对应的键值对,那就完了,会一直遍历这个环形链表,因为源码中是遍历到null才推出循环的,环形链表没有null结果就是死循环。这么看来HashMap多线程下造成死循环的条件还是蛮苛刻的嘛。
2.JDK1.8中
JDK1.8中HashMap的结构发生了变化,即当Entry链表达到了一定的长度,会用红黑树结构代替链表结构,也就是说存在链表结构和红黑树结构同时存在的情况,图可以这么画:

这样就有效解决了Hash冲突问题,其他变化不大。
二.ConcurrentHashMap
1.JDK1.7中
ConcurrentHashMap能够实现线程安全且高效是因为采用了分段加锁的方式,与HashMap结合起来看,其实就是把一个大table分成了一段一段的Segment,Segment实现了再入锁ReentranLock,即充当了ConcurrentHashMap中锁的角色。Segment中有一个一个的HashEntry键值对有效数据,图可以这么画:
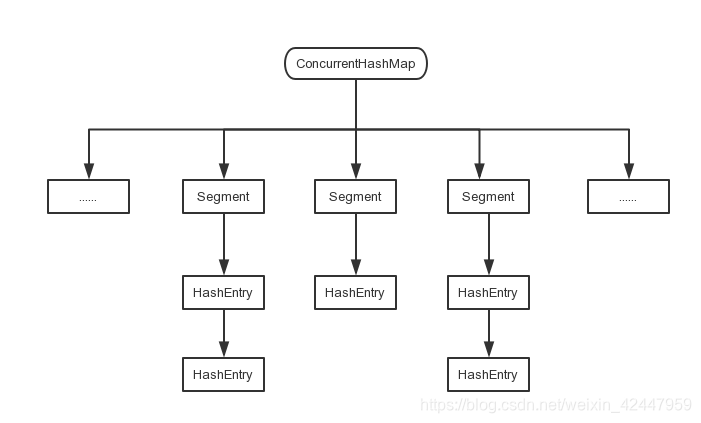
其实可以把Segment理解为一个大table中一个一个的位置,这么一理解ConcurrentHashMap与HashTable最大的区别就是ConcurrentHashMap对大table中每个位置加了锁,而HashMap如果要加锁的话就是对整个table加锁,当然效率就高了。
ConcurrentHashMap的get方法还是那套,根据key找到对应的Segment,再遍历key拿到具体的HashEntry。
ConcurrentHashMap的put方法就显得复杂了,不过大致还是那套,大致是先判断是否需要扩容,扩容整理后根据key找到对应的Segmentm,再往Segment中put键值对,这个时候put是加锁的,利用自旋锁去尝试获取锁,获取锁后判断key是否存在,存在就覆盖不存在就添加一个键值对。总之就是利用再入锁的方式锁住Segment,保证只有一个线程在操作Segment,这就相当于在HashMap中保证了只有一个线程在数组的一个位置中put,这当然不会形成环形链表了。
2.JDK1.8中
JDK1.8中变化较大,首先取消了Segment,理解一下第一层直接就是HashEntry。还有就是当链表达到一定长度的时候会以红黑树的形式代替,这个和HashMap一样嘛,图可以这么画:

put的时候采用了CAS+synchronized保证线程安全,get就还是那样,读不影响线程安全,所以变化不大。