进程调度的时机
进程调度时机就是内核调用schedule函数的时机。当内核即将返回用户空间时,内核会检查need_resched标志是否设置。如果设置,则调用schedule函数,此时是从中断(或者异常、系统调用)处理程序返回用户空间的时间点作为一个固定的调度时间点。
除此之外,内核线程和中断处理程序中任何需要暂时中止执行当前执行路径的位置都可以直接调用schedule(),比如等待某个资源就绪。进程调度时机简单总结如下:
- 用户进程通过特定的系统调用主动让出CPU。
- 中断处理程序在内核返回用户态时进行调度。
- 内核线程主动调用schedule函数让出CPU。
- 中断处理程序主动调用schedule函数让出CPU。
schedule()在Linux内核4.15.13中实现如下:
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
* 警告:只能在CPU不可抢占的时候被调用
*/
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
local_irq_disable();
rcu_note_context_switch(preempt);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
rq_lock(rq, &rf);
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
prev->on_rq = 0;
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev);
if (to_wakeup)
try_to_wake_up_local(to_wakeup, &rf);
}
}
switch_count = &prev->nvcsw;
}
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space. For TSO
* (e.g. x86), the architecture must provide its own
* barrier in switch_mm(). For weakly ordered machines
* for which spin_unlock() acts as a full memory
* barrier, finish_lock_switch() in common code takes
* care of this barrier. For weakly ordered machines for
* which spin_unlock() acts as a RELEASE barrier (only
* arm64 and PowerPC), arm64 has a full barrier in
* switch_to(), and PowerPC has
* smp_mb__after_unlock_lock() before
* finish_lock_switch().
*/
++*switch_count;
trace_sched_switch(preempt, prev, next);//任务切换
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);//上下文切换
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}那么在core.c中有哪些地方调用了schedule()呢?(也就是哪里可以发生进程调度),经过搜索发现以下几处:
- asmlinkage __visible void __sched schedule_user(void);这个函数当set_need_resched()被调用或者被远程唤醒但IPI尚未到达。这是注释中给出的信息。
- void __sched schedule_preempt_disabled(void);在禁用抢占的时候被调用。
- static void do_sched_yield(void);将当前CPU声明给其他线程时执行此函数。
- int __sched yield_to(struct task_struct *p, bool preempt);将当前CPU声明给同一进程组中的其他进程是调用此函数。
- void io_schedule(void);源码中没有注释,不过可以推测是在当前进程准备进行IO时让出CPU。
其实linux中进程调度发生的时机和其他操作系统区别不大,无非是以下几种:
- 正在执行的进程执行完毕。
- 执行中的进程主动阻塞自己进入睡眠状态,或者调用了P原语因资源不足而被阻塞,或者调用了V原语激活了等待资源的队列。
- 进程IO准备就绪后被阻塞。
- 分时系统中时间片用完。
- 执行系统调用返回时发生调度。
- 就绪队列中有进程优先级高于当前进程时。
CGDB追踪调试schedule()
在自己系统中对menuOS进行调试,选择之前用过的fork系列的test.c。
分别在schedule,context_switch,switch_to,pick_next_task处设置断点。由于switch_to是内嵌汇编代码所以无法跟踪调试,下面会单独分析。
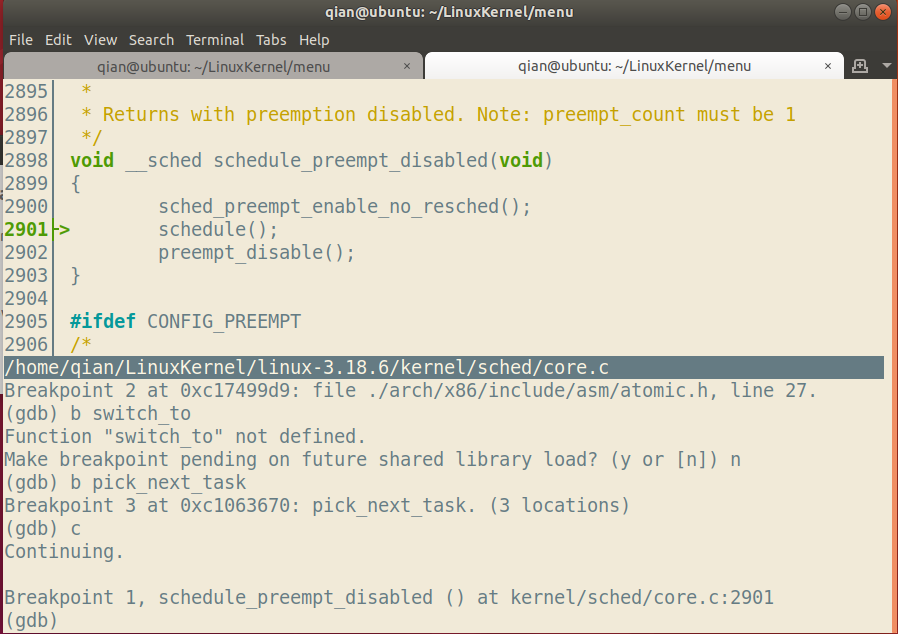
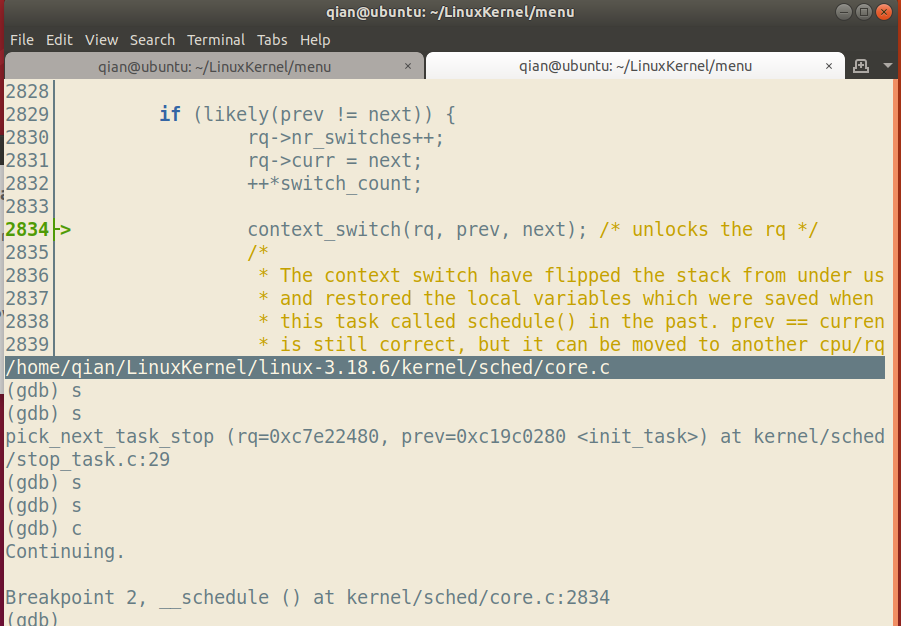

另外在按s进行调试的过程中我们发现经常进入一个叫做update_curr的函数,该函数如下:
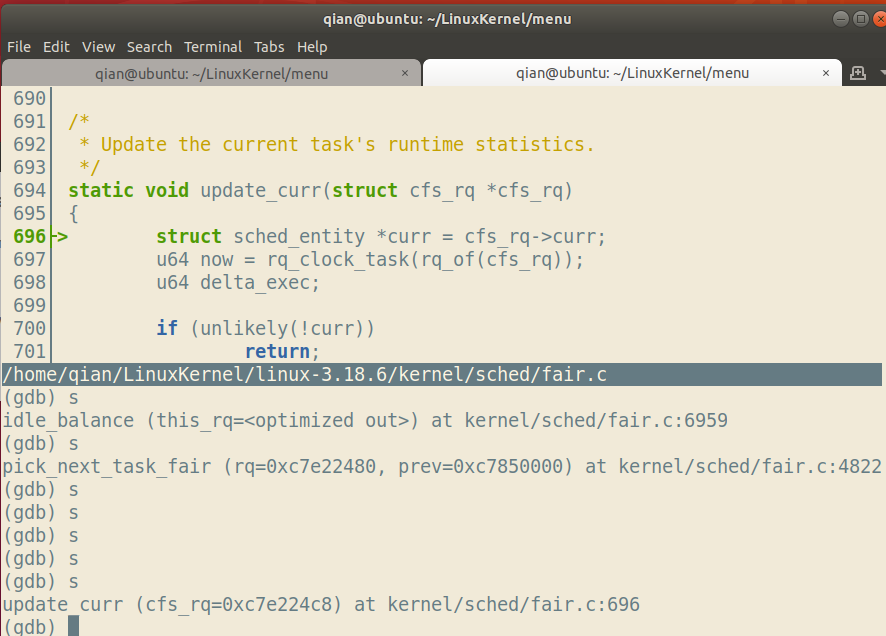
上下文(运行环境)的切换
为了控制进程执行,内核必须有能力挂起正在CPU种运行的进程,并恢复挂起的某个进程。这被称为进程切换,任务切换或者进程上下文切换。
进程上下文包含了进程执行需要的所有信息,包括用户地址空间(程序代码,数据,用户堆栈),控制信息(进程描述符,内核堆栈),硬件上下文,相关寄存器的值。
一般来说,CPU任何时刻都处于以下3中情况之中:
- 运行于用户空间,执行用户进程上下文。
- 运行于内和空间,处于进程,一般是内核线程的上下文。
- 运行于内核空间,处于中断上下文。
进程上下文和中断上下文
上下文(congtext)简单来说就是一个环境。
用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存 器值、变量等。所谓的“进程上下文”,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈上的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。一个进程的上下文可以分为三个部分:
- 用户级上下文:正文、数据、用户堆栈以及共享存储区。
- 寄存器上下文:通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP)。
- 系统级上下文:进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
当发生进程调度时,进行进程切换就是上下文切换(context switch).操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的模式切换(mode switch)与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的“ 中断上下文”,就是硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。中断上下文,其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被中断的进程环境)。中断时,内核不代表任何进程运行,它一般只访问系统空间,而不会访问进程空间,内核在中断上下文中执行时一般不会阻塞。
简单来说,中断发生以后,CPU跳到内核设置好的中断处理代码中去,由这部分内核代码来处理中断。这个处理过程中的上下文就是中断上下文。
Linux内核工作在进程上下文或者中断上下文。提供系统调用服务的内核代码代表发起系统调用的应用程序运行在进程上下文;另一方面,中断处理程序,异步运行在中断上下文。中断上下文和特定进程无关。
switch_to关键汇编代码分析
该部分定义在/linux-3.18.6/arch/x86/include/asm/switch_to.h中,代码如下:
/*
* Saving eflags is important. It switches not only IOPL between tasks,
* it also protects other tasks from NT leaking through sysenter etc.
*/
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
//完成内核堆栈的切换
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
//next_ip一般是$1f,新创建的进程则是ret_from_fork
"jmp __switch_to\n" /* regparm call */ \
//jmp通过寄存器传递参数,比较直观;而call则通过堆栈传递参数
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
在这段代码中有一些值得注意的地方,比如:
- next_ip一般是$1f,对新创建的子进程是ret_from_fork。
jmp跳转到switch_to。这是jmp和ret的搭配。通常我们看到的是call和ret的搭配,call会自动压栈返回地址,ret会弹出返回地址。jmp不会压栈,ret会弹出当前栈顶,也就是$1f所在的位置。
经验
需要注意的是,在比较新版本的内核中,schedule()被调用只能是在CPU不可抢占的时候,需要检查的标志位也变成了TIF_NEED_RESCHED。具体在Linux系统中调度何时发生、怎样发生是一个比较复杂的问题。(我理解还比较模糊,在3.18.6这个版本的内核中甚至没有提到过CPU抢占和不可抢占这一说法,至少在core.c中没有。另外在3.18.6中用的都是**_schedule()函数,而在4.15.13中用的都是schedule()**函数,他们的写法有很大不同。不得不感叹于计算机行业的变化之快,这也是我们为什么需要做中学的原因之一。)
另外在这次的内核代码中,可以看到贴近硬件的编程人员的特别技能——likely和unlikely。
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)likely表示该表达式取1的可能性较大,unlikely表示该表达式取0的可能性更大。
从函数功能上讲这两个宏定义是一样的,但是在编译器编译时会把分支编译成有利于顺序执行的结构。