版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wangyaninglm/article/details/84901376
构思这个系列的初衷是很明显的,之前我是从图论起家搞起了计算机视觉,后来发现深度学习下的计算机视觉没的搞了,后来正好单位的语料很丰富就尝试了NLP 的一些东西,早期非常痴迷于分词等等的技术,后来发现NLP 里面是有广阔天地的。
如果你现在打开微信,可能很多公众号都在推送从哪里爬取了一些语料数据如下图,

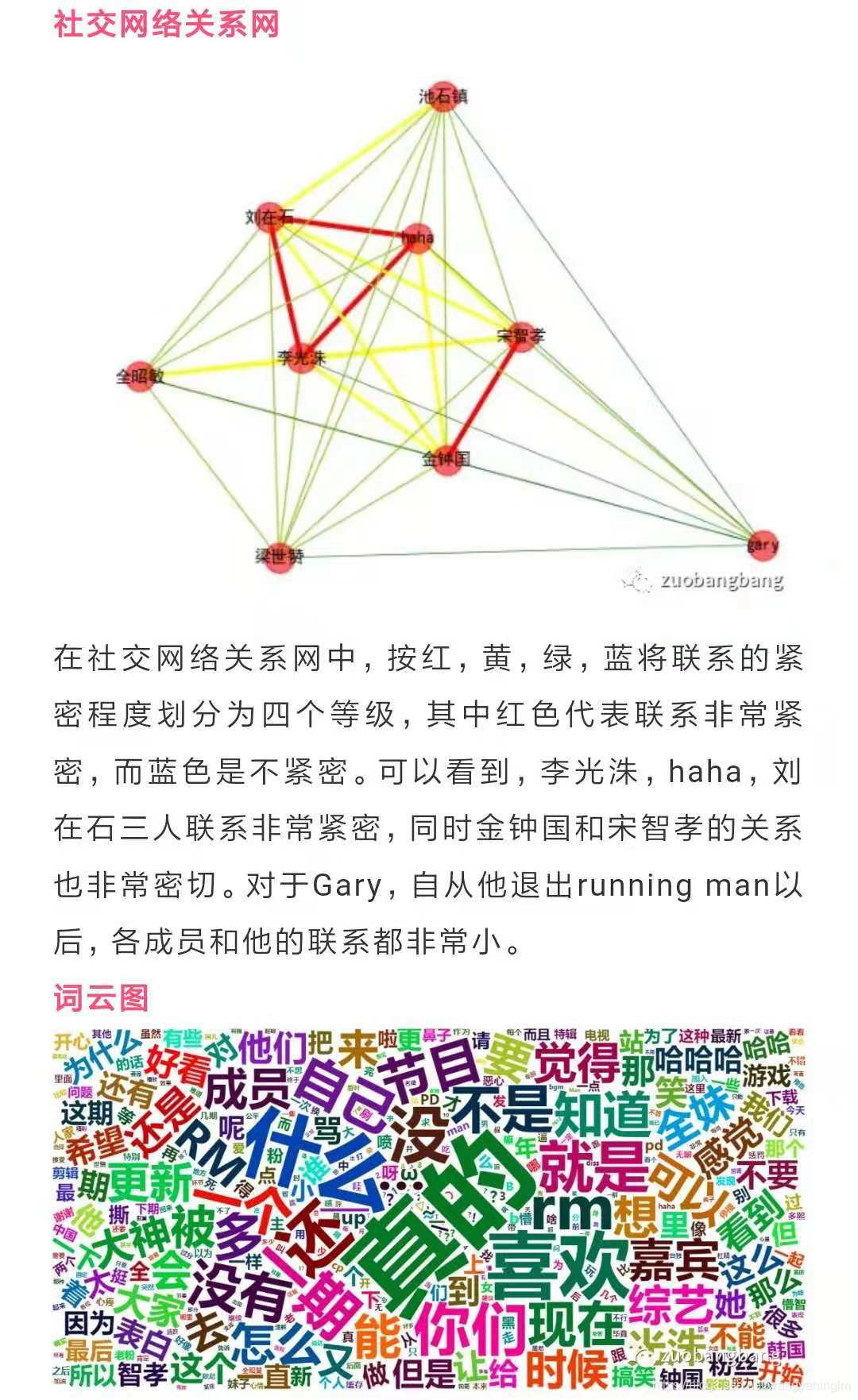
原文链接:透过评论看Runningman
比如豆瓣电影的评论,对某某最新上映的电影做了如下一些分析,看起来花花绿绿很是高端,当然我们也能做,而且要做的更高端一些!!!
系列文章:
1.基于分布式的短文本命题实体识别之----人名识别(python实现)
可视化
词云
wordCloud
# encoding: utf-8
'''
@author: season
@contact: [email protected]
@file: wordCloud.py
@time: 2018/11/6 22:38
@desc:
'''
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
import jieba.analyse
import pandas
import os
def file_name(file_dir,extension):
L = []
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == extension:
L.append(os.path.join(root, file))
return L
file_list = file_name('blog/','.txt')
print(file_list)
def get_all_strFromTxt(file_name):
str_blog = ''
with open(file_name,'r',encoding='utf-8') as f:
str_blog = f.read()
return str_blog
# file_path = u'''0.csv'''
# col_names = ["index","1","2"]
# data = pandas.read_csv(file_path, names=col_names, header = 0,engine='python', dtype=str,encoding='utf-8')
# # 返回前n行
# # 返回前n行
# first_rows = data.head(n=2)
# print(first_rows)
#
# data.info()
#
#
#
top_word_dict = {}
def getTopkeyWordsTFIDF(stop_word_file_path,topK=100,content = ''):
try:
jieba.analyse.set_stop_words(stop_word_file_path)
tags = jieba.analyse.extract_tags(content, topK, withWeight=True,allowPOS=('ns', 'n', 'vn', 'v'))
for v, n in tags:
print (v + '\t' + str((n )))
top_word_dict[v] = n*100
except Exception as e:
print(e)
finally:
pass
def getTopkeyWordsTextRank(stop_word_file_path,topK=100,content = ''):
try:
jieba.analyse.set_stop_words(stop_word_file_path)
tags = jieba.analyse.textrank(content, topK, withWeight=True)
for v, n in tags:
print (v + '\t' + str(int(n )))
except Exception as e:
print(e)
finally:
pass
str_summary = ''
#
# for i in range(0, len(data)):
# #print(data.iloc[i]['line_remark'])
# str_summary = str_summary+data.iloc[i]['line_remark']
#
for i in file_list:
str_summary = str_summary + get_all_strFromTxt(i)
text_from_file_with_apath = str_summary
getTopkeyWordsTFIDF('stop_words.txt',150,text_from_file_with_apath)
stop_words = [' ','挂号']
# 可以指定字体,或者按照词频生成
def show_WordCloud(str_all):
wordlist_after_jieba = jieba.cut(str_all, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud(background_color = "white",width = 1000,height = 860,font_path = "msyh.ttc",
# 不加这一句显示口字形乱码
margin = 2,
max_words=150, # 设置最大现实的字数
stopwords=stop_words,# 设置停用词
max_font_size=250,# 设置字体最大值
random_state=50# 设置有多少种随机生成状态,即有多少种配色方案
)
#my_wordcloud = my_wordcloud.generate(wl_space_split)
my_wordcloud = my_wordcloud.generate_from_frequencies(top_word_dict)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
show_WordCloud(text_from_file_with_apath)

算法 0.08393536068790623
图像 0.06798005803851344
数据 0.05240655130424626
文档 0.05059459998147416
博主 0.05050301638484851
使用 0.04356879903615233
函数 0.042060415733978916
查询 0.04005136456931241
匹配 0.037386342706479996
代码 0.03603846563455227
方法 0.034559914773027035
节点 0.033931860083514016
特征 0.03291738415318488
进行 0.031490540413372146
排序 0.029646884115013712
计算 0.029533756683699914
需要 0.029447451266380476
线程 0.02876913122420475
像素 0.028464105792597654
模型 0.027687724999548125
文件 0.027195920887218235
字段 0.026565494216139303
结果 0.025830152697758277
视差 0.024437895533599558
信息 0.02390653201451686
分片 0.02315742689824399
文章 0.02157718425850839
处理 0.02109550803266701
学习 0.021005721546578465
定义 0.02056261379145052
实现 0.02039579088457056
参数 0.02036164789518406
问题 0.020284272744458855
用户 0.019859257580053805
返回 0.019832118152486682
分词 0.019801132262955684
创建 0.019597880527283076
系统 0.019390564734465893
版权 0.018984989081581773
时候 0.018884022674800702
转载 0.01866584359633088
检测 0.018436606839486752
包含 0.017926737352527033
矩阵 0.017271551959541505
安装 0.0171156281612187
数据库 0.016960979586574783
主题模型
行业语料库
保险行业语料库
https://github.com/Samurais/insuranceqa-corpus-zh/wiki
医学健康类语料库
中国疾病知识图谱
http://med.ckcest.cn/knowledgeGraph.jsp
疾病科学数据库:
http://med.ckcest.cn/resource/scientificData.html
中国医院大全:
http://yyk.qqyy.com/search.html
99医院库(医疗评分):
https://yyk.99.com.cn/
扫描二维码关注公众号,回复:
4429197 查看本文章

药物临床试验登记与信息公示平台
http://www.chinadrugtrials.org.cn/eap/clinicaltrials.prosearch