AP聚类算法是基于数据点间的“信息传递"的一种聚类算法。AP算法不需要在运行算法之前确定聚类的个数。AP算法寻找数据集合中实际存在的点为聚类中心点,作为每类的代表。
基本概念
相似性矩阵S(similarity):使得s(i,j)>s(i,k)当且仅当xi与xj的相似性程度要大于其与xk的相似性,s(i,j)使用负的欧式距离,相似矩阵的定义方式可以参考我的另一篇文章:谱聚类
吸引信息矩阵R(responsibility):r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息;
归属信息矩阵A(availability):a(i,k)描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息。

exemplar:聚类的中心点;
damping factor:衰减系数,为了避免 r(i,k) 和 a(i,k) 在更新时发生数值震荡,衰减系数λ是介于0到1之间的实数;
preference:偏好参数,相似度矩阵S对角线上元素,表示数据点k作为聚类中心的程度。迭代开始前假设所有点成为聚类中心的能力相同,因此参考度一般设为相似度矩阵中所有值得最小值或者中位数,但是参考度越大则说明各数据点成为聚类中心的能力越强。r (i, k)+a (i, k)越大, i点隶属于以k点为聚类中心的聚类的可能性也越大
算法流程
1、 首先,availabilities被初始化为0,a(i,k)=0。然后用下式计算出responsibilities
2、 更新各点之间的吸引度,随之更新各点之间的归属度,公式如下:
3、 对以上步骤进行迭代,如果这些决策经过若干次迭代之后保持不变或者算法执行超过设定的迭代次数,又或者一个小区域内的关于样本点的决策经过数次迭代后保持不变,则算法结束
4、 a(i,k)+r(i,k)大于preference的对角线元素为类别中心, i属于a(i,k)+r(i,k)最大的类别k
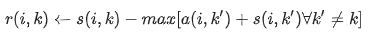
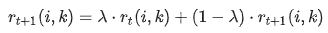
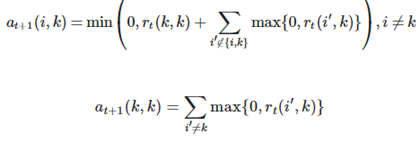
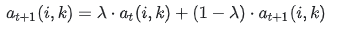
第一次迭代时,因为availabilities是0,r(i,k)被设置成输入的点i,k之间的相似度作为它的exemplar,减去点i和其他候选聚类中心之间的最大相似度。这个竞争更新是数据驱动的并且不考虑有多少其他的点支持每个候选聚类中心。
r(k,k)被设置成k被选作为聚类中心的输入的s(k,k)减去点k和其他所有候选聚类中心的最大相似度,表明k多么不合适分配给另一个聚类中心,来反映k是一个聚类中心的累积证据。responsibility的更新让所有的候选簇中心竞争数据点的控制权。availibility更新是从数据点积累关于是否每个候选聚类中心都会是一个好的聚类中心的证据。当一些点被有效地分配给其他聚类中心,他们的availabilities将会降到零下。这些负的availabilities会减小r(i,k)中的一些输入相似度s(i,k′) 的值,从竞争中去掉相应的候选聚类中心。
availability a(i,k)被设置成self-responsibility r(k,k)加上从其他点获得的正responsibilities候选聚类中心k的总和。只有正responsibilities部分是会被添加进来的,因为对于一个好的聚类中心正responsibilities是必要的。如果self-responsibility r(k,k)是负的,表明点k目前更适合作为另一个簇中心点的归属点比作为一个簇中心点。
算法优缺点
优点:
不需要指定最终聚类族的个数
已有的数据点作为最终的聚类中心,而不是新生成一个族中心。
模型对数据的初始值不敏感
对初始相似度矩阵数据的对称性没有要求
缺点:
AP算法需要事先计算每对数据对象之间的相似度,如果数据对象太多的话,空间复杂度(O(N^2))很高
时间复杂度(O(N^2T))很高,其中 N 为样本个数,T 为迭代次数
只适用于中小规模的数据集
聚类的好坏受到参考度和阻尼系数的影响
本文参考以下链接
https://www.cnblogs.com/lc1217/p/6908031.html
https://blog.csdn.net/qq_38195197/article/details/78136669
https://blog.csdn.net/xiaoleiniu1314/article/details/80007441