A Support Vector Method for Clustering
原文地址:A Support Vector Method for Clustering
本文介绍了一种基于SVM的聚类方法,核心思想是用高斯核的SVM找到多个能够包围数据的半径最小的超球。使用此方法不用预先确定类别的结构和个数。
Abstract
聚类问题可以用参数化或非参数化的方法处理。参数化方法往往限制于其表达能力(expressive power),即需要预先猜想类别的结构(概率分布)。这篇文章提出一种非参数化的基于SV的方法用来描述高维分布的特性,首先找到一个最小半径的能够包围所有数据的超球,通过减小高斯核的方差(the width parameter of the Gaussian kernel function),可以使超球分类成很多的小部分,每一小部分中包含的点便是一种类别。用软间隔解决异常值问题从而处理不同类别重叠的问题。
Describing Cluster Boundaries with Support Vectors
共有 个数据点 , , 是 变换至高维的特征,加入松弛变量 ,要想求得包围所有数据的最小半径的超球,可用下面的问题描述:
其中 为半径, 为超求的球心,拉格朗日函数:
其中拉格朗日乘子 , 为惩罚参数。对 分别求偏导并置零得:
KKT条件:
对于样本点 :
- 若 则样本点在超球外;
- 若
则样本点在超球面上或超球面内,当
:
- 若 则称样本点是一个支持向量(SV);
- 若 则称样本点为边界支持向量(bounded SV)
接下来拉格朗日对偶函数:
将上述推导出的条件代入可得约束条件变为:
将内积运算全部换成如下的高斯核:
为宽度参数(width parameter,即 ),那么拉格朗日对偶函数可写为:
此时数据点到球心的距离:
可化为:
那么超球的半径即为SV到球心的距离。此时闭合轮廓的形状由参数 和 决定。如下图, 增大,轮廓就越贴合样本点。 主要定义了单个样本对整个分类超平面的影响,当 比较小时,单个样本对整个分类超平面的影响比较小,不容易被选择为支持向量,反之,当 比较大时,单个样本对整个分类超平面的影响比较大,更容易被选择为支持向量,或者说整个模型的支持向量也会多。

而当 减小时,如下图,轮廓边缘变得平滑,SV的数量减少,而bounded SV的数量增多(当 时bounded SV才会存在),可以更好地处理异常点。如果把惩罚系数 和RBF核函数的系数 一起看,当 比较大, 比较大时,我们会有更多的支持向量,我们的模型会比较复杂,容易过拟合一些。如果 比较小 , 比较小时,模型会变得简单,支持向量的个数会少。
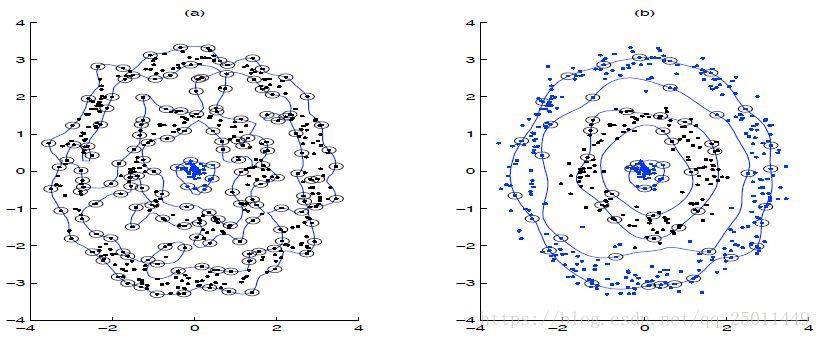
Support Vector Clustering (SVC)
为了将数据点聚类,文中介绍了一种求两点间邻接矩阵的方法:

如果两点连线间的所有点均在超球内部,说明两数据点有连接,即位于同一类。
Overlapping clusters(不是很懂)
当存在重叠时,说明bounded SV很多,SVC可以近似地看作Parzen窗概率密度估计(如下公式)。
Parzen窗概率密度估计值最大的点便是核心的点。
The iris data
在鸢尾花数据集的数值实验中,SVC表现要优于information theoretic approach和SPC algorithm这两个非参数化的聚类方法。具体实验结果如下:

同时,需要注意的是,SVC在低维特征上的表现要优于高维特征,因此最好事先对数据特征进行降维处理,例如PCA。
Varying and
这里将如何寻找最优的 和 ,对于 最好从小到大依次寻找,因为一个比较好的聚类通常含有较少的类别。当SV的数量超出某个范时便可确定参数 和 。