如果Executor故障,所有未被处理的数据会丢失,解决办法可以通过wal(hbase,hdfs/WAL)方式,将数据预先写到hdfs或者s3
如果Driver故障,driver程序就会停止,所有executor都会失去丢失,停止计算过程,解决办法需要配置和编程
1.配置diver程序自动重启,使用特定的clustermanager实现,
2。重启时从宕机的地方重启。通过检查点机制,就可以实现该功能。
//可以使用本地目录或者hdfs
jsc.checkpoint(“d:…”)
不要使用new的方式来创建sparkstreamingcontext上下文对象,而是通过工厂的方式JavaStreamingContext().getOrCreate()方法来创建上下文对象,在创建上下文对象的时候,首先会检查检查点目录,看是否job允许,没有job允许就直接new新的。
代码如下:
public class JavaSparkStreamingWCApp {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("wc");
conf.setMaster("local[4]");
//创建spark应用上下文,间隔批次是2
/**
* 这里为了做到容错,不使用new的方式来创建streamingContext对象,
* 而是通过工厂的方式JavaStreamingContext.getOrCreate()方式来创建,
*这种方式创建的好处是:在启动程序的时候回首先去检查点目录检查
* 如果有数据,就直接从数据中回复,如果没有数据,就直接new一个新的。
* 实验:一下代码实现了当driver正常运行的时候,宕机,
* 重启会自动从以前的checkpoint点拿取数据,重新计算。
*/
Function0<JavaStreamingContext> contextFunction = new Function0<JavaStreamingContext>() {
//首次创建context对象调用该方法
public JavaStreamingContext call() throws Exception {
JavaStreamingContext jsc = new JavaStreamingContext(conf, Seconds.apply(2));
JavaReceiverInputDStream<String> socket = jsc.socketTextStream("mini4", 9999);
/*变化的代码放到处这里是一个窗口函数,窗口的长度是24小时,滑块的间隔是2秒*/
JavaDStream<Long> dsCount = socket.countByWindow(new Duration(24 * 60 * 60 * 1000), new Duration(2000));
dsCount.print();
//切记,这里一定要写检查点
jsc.checkpoint("g:/log/data/spark/ck/java_spark_streaming_wc");
return jsc;
}
};
//失败重新连接的时候会经过检查点。
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("g:/log/data/spark/ck/java_spark_streaming_wc",contextFunction);
jsc.start();
try {
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
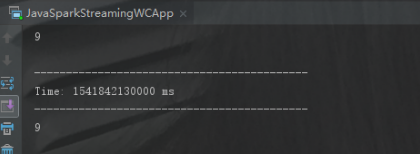
当Driver宕机后,重启后会从checkpoint端自动获取未读取的数据数据。
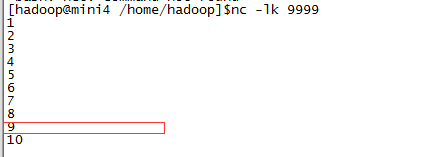
这里是验证上面的代码,mini4上使用
当输入到8的时候将程序停止,然后mini4上不停的输入数据,再次重启还会从9以后开始读取