在本文中,我们将介绍自然语言处理(NLP)在迁移学习上的最新应用趋势,并尝试执行一个分类任务:使用一个数据集,其内容是亚马逊网站上的购物评价,已按正面或负面评价分类。然后在你可以按照这里的说明,用你自己的数据重新进行实验。
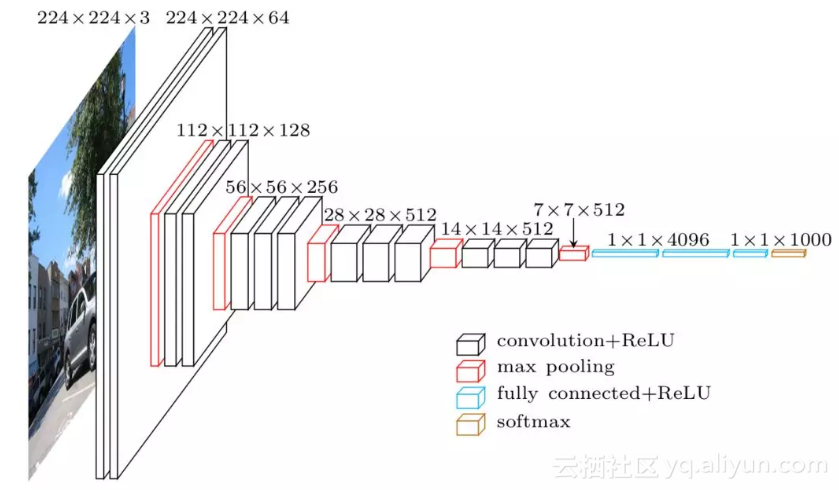
迁移学习模型的思路是这样的:既然中间层可以用来学习图像的一般知识,我们可以将其作为一个大的特征化工具使用。下载一个预先训练好的模型(模型已针对ImageNet任务训练了数周时间),删除网络的最后一层(完全连接层),添加我们选择的分类器,执行适合我们的任务(如果任务是对猫和狗进行分类,就选择二元分类器),最后仅对我们的分类层进行训练。
由于我们使用的数据可能与之前训练过的模型数据不同,我们也可以对上面的步骤进行微调,以在相当短的时间内对所有的层进行训练。
除了能够更快地进行训练之外,迁移学习也是特别有趣的,仅在最后一层进行训练,让我们可以仅仅使用较少的标记数据,而对整个模型进行端对端训练则需要庞大的数据集。标记数据的成本很高,在无需大型数据集的情况下建立高质量的模型是很可取的方法。
迁移学习NLP的尴尬
目前,深度学习在自然语言处理上的应用并没有计算机视觉领域那么成熟。在计算机视觉领域中,我们可以想象机器能够学习识别边缘、圆形、正方形等,然后利用这些知识去做其他事情,但这个过程对于文本数据而言并不简单。