版权声明:转载请加链接 https://blog.csdn.net/qq_33722172/article/details/84257910
写这篇博客的主要原因就是之前面试的两家公司都有问到这个问题,所以便着手研究了一下它的解决方法
问题描述:一个日志文件里逐行存储着 时间 ip 这种形式的日志,现在需要让你使用linux命令查找出日志文件中访问量最大的10个ip
怎么处理?
1.首先创建模拟数据
这里博主用python写了个创建模拟数据的脚本 文件内容格式 : 时间戳 ip
#!/usr/bin/python
# -*- coding:UTF-8 -*-
#filename = testdata.py
import random
import time
file = open('/ip.txt','w');
for i in range(0,500):
num = random.randint(1,10)
rand_str = time.time()
fir_1 = random.randint(0,255)
sec_2 = random.randint(0,255)
thr_3 = random.randint(0,255)
fou_4 = random.randint(0,255)
for j in range(1,num+1):
file.write(str(rand_str)+' '+str(fir_1)+'.'+str(sec_2)+'.'+str(thr_3)+'.'+str(fou_4)+'\n')
file.close()
print 'create sucessful!!'
2.输入命令
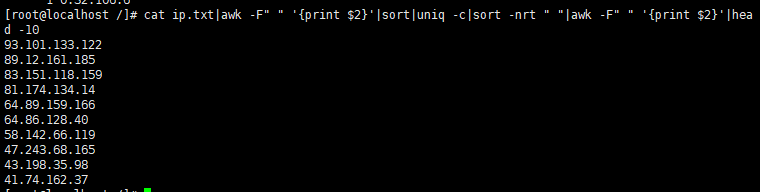
cat ip.txt|awk -F" " '{print $2}'|sort|uniq -c|sort -nrt " "|awk -F" " '{print $2}'|head -10
每一步命令解释:
cat ip.txt 将ip.txt文件内容输出到终端
| 通过管道符|将左边命令输出作为右边命令输入(后面|功能类似)
awk -F" " ‘{print $2}’
-F 指定输入文件折分隔符 -F" ": 以空格分隔
{print $2} 分隔后每一行就分成了时间戳和ip两个单元$1指时间$2指ip print $2 即输出ip
sort 对输出ip进行排序
uniq -c 检查及删除文本文件中重复出现的行列 -c或–count 在每列旁边显示该行重复出现的次数。
此时输出的数据格式为 出现次数 ip
sort -nrt " " 对输出结果排序 -n : 依照数值的大小排序 -r : 以相反的顺序来排序 -t : <分隔字符> 指定排序时所用的栏位分隔字符
接着继续用awk 将数据第二列ip输出
head -10 取前十条数据
命令执行结果: