版权声明:原创文章,谢绝转载 https://blog.csdn.net/m0_37367424/article/details/84675888
一. 计数器
计数器时收集作业,学习计数器可以帮助我们深入学习MapReduce原理,益处多多。
二. 计数器分类。
- 内置计数器
- 任务计数器
- 作业计数器
- 自定义计数器
- java计数器
- streaming计数器
三. 内置计数器
内置计数器主要包含5类,分别如下:
- MapReduce计数器
- 文件系统计数器
- FileInputFormat计数器
- FileoutputFormat计数器
- 作业计数器
对应运行结果中的相关技术。
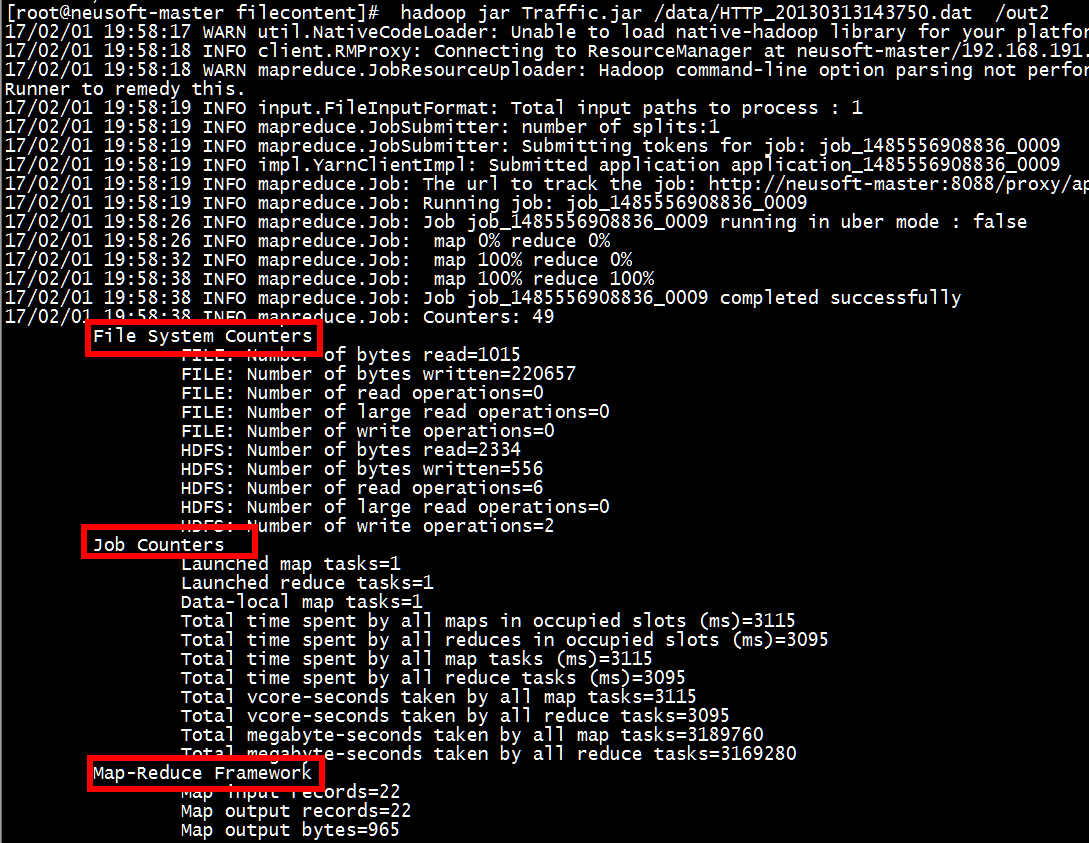
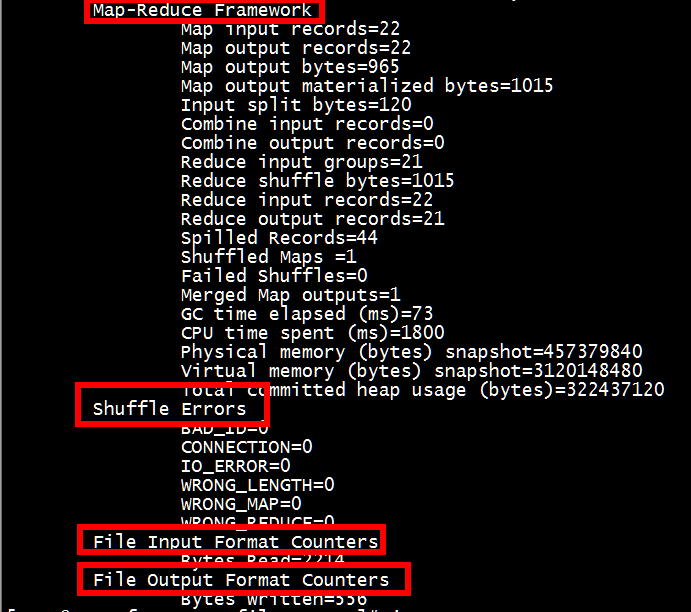
任务计数器在任务运行过程中更新,由相关联的任务统计,然后发送数组到AM;作业计数器由AM维护。
1. 任务计数器
在任务执行过程中,任务计数器采集任务的相关信息,每个作业的所有任务的结果会被聚集起来。例如,MAP_INPUT_RECORDS 计数器统计每个map任务输入记录的总数,并在一个作业的所有map任务上进行聚集,使得最终数字是整个作业的所有输入记录的总数。任务计数器的值每次都是完整传输的,而非传输自上次传输以后的计数值。以下为计数器列表:
(详细列表见:链接)
- MapReduce任务计数器
| 英文相关字段 | 计数器名称 | 说明 |
|---|---|---|
| MAP_INPUT_RECORDS | map输入的记录数 | 作业中所有map已处理的输入记录数。每次Recorder读取到一条记录并将其传递给map的map函数时,该计数器值递增 |
| SPLIT_RAW_BYTES | 分片元数据(分片原始字节数) | map读取的输入分片的元数据大小。所谓元数据,即描述分片在文件中位移、长度等的数据,一般很小 |
| MAP_OUTPUT_RECORD | map输出的记录数 | 作业中map产生的map输出记录数。每此一个map的OutputCollector调用collect方法时,该计数器增加 |
| ··· | ···· | ···· |
- 文件系统计数器
| 英文相关字段 | 计数器名 | 说明 |
|---|---|---|
| BYTES_READ | 文件系统的读字节数 | 由map任务和reduce任务在各个文件系统中读取的字节数,每个文件系统分别对应一个计数器 |
| READ_OPS | map任务和reduce在各个文件系统中进行读操作的数量,包含(open操作,file status 操作等) | |
| ·· | ·· | ·· |
- FileInputFormat计数器
| 英文相关字段 | 计数器名 | 说明 |
|---|---|---|
| BYTES_READ | 读取字节数 | 由map任务通过FileInputFormat读取的字节数 |
- FileOutputFormat计数器
| 英文相关字段 | 计数器名 | 说明 |
|---|---|---|
| BYTES_WRITTEN | 写的字节数 | 由map任务(仅包含map的作业)或者reduce任务通过FileOutputFormat写的字节数。 |
2. 作业计数器
作业计数器同任务计数器不同,它是由AM维护的(参考MapReduce运行流程,一个作业对应一个AM),计数器无需在网络间传递数据。以下列出溢写常用到的作业计数器,详细列表见上
| 计数器名称 | 说明 |
|---|---|
| 启用的map任务数(TOTAL_LAUNCHED_MAPS) | 启动的map任务数,包括以“推测执行” 方式启动的任务。 |
| 启用的 reduce 任务数(TOTAL_LAUNCHED_REDUCES) | 启动的reduce任务数,包括以“推测执行” 方式启动的任务。 |
| 失败的map任务数(NUM_FAILED_MAPS) | 失败的map任务数。 |
| 失败的 reduce 任务数(NUM_FAILED_REDUCES | 失败的reduce任务数。 |
| 数据本地化的 map 任务数(DATA_LOCAL_MAPS) | 与输入数据在同一节点的 map 任务数。 |
| 机架本地化的 map 任务数(RACK_LOCAL_MAPS) | 与输入数据在同一机架范围内、但不在同一节点上的 map 任务数。 |
| 其它本地化的 map 任务数(OTHER_LOCAL_MAPS) | 与输入数据不在同一机架范围内的 map 任务数。由于机架之间的宽带资源相对较少,Hadoop 会尽量让 map 任务靠近输入数据执行,因此该计数器值一般比较小。 |
| map 任务的总运行时间(SLOTS_MILLIS_MAPS) | map 任务的总运行时间,单位毫秒。该计数器包括以推测执行方式启动的任务。 |
| reduce 任务的总运行时间(SLOTS_MILLIS_REDUCES) | reduce任务的总运行时间,单位毫秒。该值包括以推测执行方式启动的任务。 |
三. 自定义计数器
计数器由三部分组成:分组名,计数器名,计数器的值
1. java计数器
1.1 创建计数器
创建java计数器包含两种方法:
- 基于枚举类型创建计数器,对于枚举计数器,组名=包名+类名,枚举类型的字段就是计数器名称
- 基于String创建计数器,对于该计数器,第一个参数为组名,第二个参数为计数器名。
分别对应一下两个方法,返回一个计数器对象: Counter getCounter(Enum<?> var1)Counter getCounter(String var1, String var2)
计数器Counter对象主要包含如下方法
String getName()String getDisplayName();long getValue()void setValue(long var1)void increment(long var1):增加计数器值
1.2 获取计数器
Counters counters = job.getCounters();
total = counters.findCounter(MaxTemperature.Temperature.TOTAL).getValue();//获取自定义计数器
mpas = counters.findCounter(TaskCounter.MAP_INPUT_RECORDS).getValue(); //获取内置计数器
1.3 举例 – 创建计数器
此处演示了创建计数器的过程,详情见代码注释
// ---省略一堆无关代码----
/**
* 范例9-1:统计最高气温的的记录,包含统计气温的缺失记录等
* */
public class MaxTemperatureWithCounters extends Configured implements Tool {
// 枚举类型计数器,两个字段表示缺失值和不合法值
enum Temperature {
MISSING, MALFORMED
}
// map类
static class MaxTemperatureWithCountersMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 此类为具体解析类,并非重点,如有需要请访问以下链接查看:https://github.com/zhaopengyue/hadoop-book/blob/master/common/src/main/java/NcdcRecordParser.java
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
// 正常情况下直接写入
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
} else if (parser.isMalformedTemperature()) {
// 失败情况下,使用计数器计数
// 该计数器为枚举类型。
context.getCounter(Temperature.MALFORMED).increment(1);
} else if (parser.isMissingTemperature()) {
context.getCounter(Temperature.MISSING).increment(1);
}
// 动态计数器
context.getCounter("TemperatureQuality", parser.getQuality()).increment(1);
}
}
// ----省略一堆代码----
实验结果:

说明:注:通常情况下,我们自定义的计数器的分组名为:包名+类名,有时候我们想显示的人性化一点即显示我们想要的计数器名称,解决方案是在该MapReduce程序同一个包下建立一个属性文件,文件的命名规则是:类_枚举.properties(相当于指定枚举计数器定义位置)
#CounterGroupName 用来声明groupName的控制台显示信息
CounterGroupName=非法计数器
#枚举类型加.name用来声明counterName的控制台显示信息
MISSING.name=缺失值
文件放置相对位置

1.4 举例 – 获取计数器
暂带补充
2. streaming计数器
该计数器通过向标准错误流输出一定格式的字符串来控制计数器。
格式为:reporter:counter:groupName(分组名), counter(计数器名):amount(增加的值)
以python为例
sys.err.write('reporter:counter:Temperature,Missing,1')