背景
Redis采用的过期策略是定期删除+惰性删除,但由于定期删除的随机性和惰性删除的被动性,仍然可能出现大量过期key堆积在内存里,导致redis的内存快耗尽。
为了避免这种情况,redis的内存数据集大小上升到一定大小的时候,就会开启内存淘汰功能。
Redis提供了下面几种内存淘汰策略供用户选择:
- noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
- allkeys-lru:在主键空间中,优先移除最近未使用的key。
- allkeys-random:在主键空间中,随机移除某个key。
- volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
- volatile-random:在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
其中allkeys-lru策略是最推荐,最常使用的。
LRU
1. LRU缓存的思想
- 固定缓存大小,需要给缓存分配一个固定的大小。
- 每次读取缓存都会改变缓存的使用时间,将缓存的存在时间重新刷新。
- 需要在缓存满了后,将最近最久未使用的缓存删除,再添加最新的缓存。
2. 实现思路
基于HashMap和双向链表实现LRU缓存。
其中head代表双向链表的头部,tail代表尾部。
首先预先设置LRU的容量,如果存储满了,则删除双向链表的尾部,每次新增和访问数据,则把新的节点增加到头部,或者把已经存在的节点移动到头部。
3. Java代码
import java.util.HashMap;
class DLinkedNode {
String key;
int value;
DLinkedNode pre;
DLinkedNode next;
}
public class LRUCache {
private HashMap cache = new HashMap();
private int count;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.count = 0;
this.capacity = capacity;
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.pre = head;
}
public int get(String key) {
DLinkedNode node = (DLinkedNode) cache.get(key);
if(node == null){
return -1; // 若访问的节点不存在,返回-1
}
// 将被访问的节点移动到头部
this.moveToHead(node);
return node.value;
}
public void set(String key, int value) {
DLinkedNode node = (DLinkedNode) cache.get(key);
if(node == null){
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
this.cache.put(key, newNode);
this.addNode(newNode);
++count;
if(count > capacity){
// 移除尾部节点
DLinkedNode tail = this.popTail();
this.cache.remove(tail.key);
--count;
}
}else{
// 更新value.
node.value = value;
this.moveToHead(node);
}
}
/**
* 在头节点后添加新节点
*/
private void addNode(DLinkedNode node){
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
/**
* 从链表中删除存在的节点
*/
private void removeNode(DLinkedNode node){
DLinkedNode pre = node.pre;
DLinkedNode next = node.next;
pre.next = next;
next.pre = pre;
}
/**
* 将节点移动到头部
*/
private void moveToHead(DLinkedNode node){
this.removeNode(node);
this.addNode(node);
}
// 移除尾部节点
private DLinkedNode popTail(){
DLinkedNode res = tail.pre;
this.removeNode(res);
return res;
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
DLinkedNode node = head.next;
while (node.next != null) {
stringBuilder.append(String.format("%s:%d ", node.key, node.value));
node = node.next;
}
return stringBuilder.toString();
}
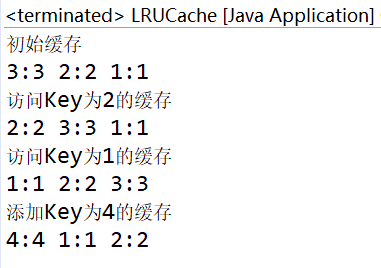
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(3);//缓存容量为3
lruCache.set("1", 1);
lruCache.set("2", 2);
lruCache.set("3", 3);
System.out.println("初始缓存\n"+lruCache);
lruCache.get("2");
System.out.println("访问Key为2的缓存\n"+lruCache);
lruCache.get("1");
System.out.println("访问Key为1的缓存\n"+lruCache);
lruCache.set("4", 4);
System.out.println("添加Key为4的缓存\n"+lruCache);
}
}
- 输出结果
Redis的LRU实现
如果按照HashMap和双向链表实现,需要额外的存储存放next和prev指针,牺牲比较大的存储空间,显然是不划算的。
所以Redis采用了一个近似的做法,就是随机取出若干个key,即基于server.maxmemory_samples配置选取固定数目的key,然后比较它们的lru访问时间,然后淘汰最近最久没有访问的key,maxmemory_samples的值越大,Redis的近似LRU算法就越接近于严格LRU算法,但是相应消耗也变高,对性能有一定影响,样本值默认为5。